|
PLASMA
2.4.5
PLASMA - Parallel Linear Algebra for Scalable Multi-core Architectures
|
|
PLASMA
2.4.5
PLASMA - Parallel Linear Algebra for Scalable Multi-core Architectures
|

Go to the source code of this file.
Macros | |
| #define | REAL |
Functions | |
| int | CORE_slarfx2 (int side, int N, float V, float TAU, float *C1, int LDC1, float *C2, int LDC2) |
| int | CORE_slarfx2c (int uplo, float V, float TAU, float *C1, float *C2, float *C3) |
| int | CORE_slarfx2ce (int uplo, float *V, float *TAU, float *C1, float *C2, float *C3) |
| int | CORE_shbelr (int uplo, int N, PLASMA_desc *A, float *V, float *TAU, int st, int ed, int eltsize) |
| int | CORE_shbrce (int uplo, int N, PLASMA_desc *A, float *V, float *TAU, int st, int ed, int eltsize) |
| int | CORE_shblrx (int uplo, int N, PLASMA_desc *A, float *V, float *TAU, int st, int ed, int eltsize) |
| int | CORE_sgbelr (int uplo, int N, PLASMA_desc *A, float *V, float *TAU, int st, int ed, int eltsize) |
| int | CORE_sgbrce (int uplo, int N, PLASMA_desc *A, float *V, float *TAU, int st, int ed, int eltsize) |
| int | CORE_sgblrx (int uplo, int N, PLASMA_desc *A, float *V, float *TAU, int st, int ed, int eltsize) |
| void | CORE_sasum (int storev, int uplo, int M, int N, float *A, int lda, float *work) |
| void | CORE_sgeadd (int M, int N, float alpha, float *A, int LDA, float *B, int LDB) |
| void | CORE_sbrdalg (PLASMA_enum uplo, int N, int NB, PLASMA_desc *pA, float *C, float *S, int i, int j, int m, int grsiz) |
| int | CORE_sgelqt (int M, int N, int IB, float *A, int LDA, float *T, int LDT, float *TAU, float *WORK) |
| void | CORE_sgemm (int transA, int transB, int M, int N, int K, float alpha, float *A, int LDA, float *B, int LDB, float beta, float *C, int LDC) |
| int | CORE_sgeqrt (int M, int N, int IB, float *A, int LDA, float *T, int LDT, float *TAU, float *WORK) |
| int | CORE_sgessm (int M, int N, int K, int IB, int *IPIV, float *L, int LDL, float *A, int LDA) |
| int | CORE_sgetrf (int M, int N, float *A, int LDA, int *IPIV, int *INFO) |
| int | CORE_sgetrf_incpiv (int M, int N, int IB, float *A, int LDA, int *IPIV, int *INFO) |
| int | CORE_sgetrf_reclap (const int M, const int N, float *A, const int LDA, int *IPIV, int *info) |
| int | CORE_sgetrf_rectil (const PLASMA_desc A, int *IPIV, int *info) |
| void | CORE_sgetrip (int m, int n, float *A, float *work) |
| void | CORE_slacpy (PLASMA_enum uplo, int M, int N, float *A, int LDA, float *B, int LDB) |
| void | CORE_slange (int norm, int M, int N, float *A, int LDA, float *work, float *normA) |
| void | CORE_slansy (int norm, int uplo, int N, float *A, int LDA, float *work, float *normA) |
| void | CORE_slaset (PLASMA_enum uplo, int n1, int n2, float alpha, float beta, float *tileA, int ldtilea) |
| void | CORE_slaset2 (PLASMA_enum uplo, int n1, int n2, float alpha, float *tileA, int ldtilea) |
| void | CORE_slaswp (int N, float *A, int LDA, int I1, int I2, int *IPIV, int INC) |
| int | CORE_slaswp_ontile (PLASMA_desc descA, int i1, int i2, int *ipiv, int inc) |
| int | CORE_slaswpc_ontile (PLASMA_desc descA, int i1, int i2, int *ipiv, int inc) |
| void | CORE_slauum (int uplo, int N, float *A, int LDA) |
| int | CORE_spamm (int op, int side, int storev, int M, int N, int K, int L, float *A1, int LDA1, float *A2, int LDA2, float *V, int LDV, float *W, int LDW) |
| int | CORE_sparfb (int side, int trans, int direct, int storev, int M1, int N1, int M2, int N2, int K, int L, float *A1, int LDA1, float *A2, int LDA2, float *V, int LDV, float *T, int LDT, float *WORK, int LDWORK) |
| int | CORE_spemv (int trans, int storev, int M, int N, int L, float ALPHA, float *A, int LDA, float *X, int INCX, float BETA, float *Y, int INCY, float *WORK) |
| void | CORE_splgsy (float bump, int m, int n, float *A, int lda, int bigM, int m0, int n0, unsigned long long int seed) |
| void | CORE_splrnt (int m, int n, float *A, int lda, int bigM, int m0, int n0, unsigned long long int seed) |
| void | CORE_spotrf (int uplo, int N, float *A, int LDA, int *INFO) |
| void | CORE_sshift (int s, int m, int n, int L, float *A) |
| void | CORE_sshiftw (int s, int cl, int m, int n, int L, float *A, float *W) |
| int | CORE_sssssm (int M1, int N1, int M2, int N2, int K, int IB, float *A1, int LDA1, float *A2, int LDA2, float *L1, int LDL1, float *L2, int LDL2, int *IPIV) |
| void | CORE_ssymm (int side, int uplo, int M, int N, float alpha, float *A, int LDA, float *B, int LDB, float beta, float *C, int LDC) |
| void | CORE_ssyrk (int uplo, int trans, int N, int K, float alpha, float *A, int LDA, float beta, float *C, int LDC) |
| void | CORE_ssyr2k (int uplo, int trans, int N, int K, float alpha, float *A, int LDA, float *B, int LDB, float beta, float *C, int LDC) |
| void | CORE_sswpab (int i, int n1, int n2, float *A, float *work) |
| int | CORE_sswptr_ontile (PLASMA_desc descA, int i1, int i2, int *ipiv, int inc, float *Akk, int ldak) |
| void | CORE_strdalg (PLASMA_enum uplo, int N, int NB, PLASMA_desc *pA, float *C, float *S, int i, int j, int m, int grsiz) |
| void | CORE_strmm (int side, int uplo, int transA, int diag, int M, int N, float alpha, float *A, int LDA, float *B, int LDB) |
| void | CORE_strsm (int side, int uplo, int transA, int diag, int M, int N, float alpha, float *A, int LDA, float *B, int LDB) |
| void | CORE_strtri (int uplo, int diag, int N, float *A, int LDA, int *info) |
| int | CORE_stslqt (int M, int N, int IB, float *A1, int LDA1, float *A2, int LDA2, float *T, int LDT, float *TAU, float *WORK) |
| int | CORE_stsmlq (int side, int trans, int M1, int N1, int M2, int N2, int K, int IB, float *A1, int LDA1, float *A2, int LDA2, float *V, int LDV, float *T, int LDT, float *WORK, int LDWORK) |
| int | CORE_stsmlq_corner (int m1, int n1, int m2, int n2, int m3, int n3, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *A3, int lda3, float *V, int ldv, float *T, int ldt, float *WORK, int ldwork) |
| int | CORE_stsmlq_sytra1 (int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt, float *WORK, int ldwork) |
| int | CORE_stsmqr (int side, int trans, int M1, int N1, int M2, int N2, int K, int IB, float *A1, int LDA1, float *A2, int LDA2, float *V, int LDV, float *T, int LDT, float *WORK, int LDWORK) |
| int | CORE_stsmqr_corner (int m1, int n1, int m2, int n2, int m3, int n3, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *A3, int lda3, float *V, int ldv, float *T, int ldt, float *WORK, int ldwork) |
| int | CORE_stsmqr_sytra1 (int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt, float *WORK, int ldwork) |
| int | CORE_stsqrt (int M, int N, int IB, float *A1, int LDA1, float *A2, int LDA2, float *T, int LDT, float *TAU, float *WORK) |
| int | CORE_ststrf (int M, int N, int IB, int NB, float *U, int LDU, float *A, int LDA, float *L, int LDL, int *IPIV, float *WORK, int LDWORK, int *INFO) |
| int | CORE_sttmqr (int side, int trans, int M1, int N1, int M2, int N2, int K, int IB, float *A1, int LDA1, float *A2, int LDA2, float *V, int LDV, float *T, int LDT, float *WORK, int LDWORK) |
| int | CORE_sttqrt (int M, int N, int IB, float *A1, int LDA1, float *A2, int LDA2, float *T, int LDT, float *TAU, float *WORK) |
| int | CORE_sttmlq (int side, int trans, int M1, int N1, int M2, int N2, int K, int IB, float *A1, int LDA1, float *A2, int LDA2, float *V, int LDV, float *T, int LDT, float *WORK, int LDWORK) |
| int | CORE_sttlqt (int M, int N, int IB, float *A1, int LDA1, float *A2, int LDA2, float *T, int LDT, float *TAU, float *WORK) |
| int | CORE_sormlq (int side, int trans, int M, int N, int IB, int K, float *V, int LDV, float *T, int LDT, float *C, int LDC, float *WORK, int LDWORK) |
| int | CORE_sormqr (int side, int trans, int M, int N, int K, int IB, float *V, int LDV, float *T, int LDT, float *C, int LDC, float *WORK, int LDWORK) |
| void | QUARK_CORE_sasum (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_enum storev, PLASMA_enum uplo, int m, int n, float *A, int lda, int szeA, float *work, int szeW) |
| void | QUARK_CORE_sasum_f1 (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_enum storev, PLASMA_enum uplo, int m, int n, float *A, int lda, int szeA, float *work, int szeW, float *fake, int szeF) |
| void | QUARK_CORE_sgeadd (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int nb, float alpha, float *A, int lda, float *B, int ldb) |
| void | QUARK_CORE_sbrdalg (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int N, int NB, PLASMA_desc *A, float *C, float *S, int i, int j, int m, int grsiz, int BAND, int *PCOL, int *ACOL, int *MCOL) |
| void | QUARK_CORE_sgelqt (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *A, int lda, float *T, int ldt) |
| void | QUARK_CORE_sgemm (Quark *quark, Quark_Task_Flags *task_flags, int transA, int transB, int m, int n, int k, int nb, float alpha, float *A, int lda, float *B, int ldb, float beta, float *C, int ldc) |
| void | QUARK_CORE_sgemm2 (Quark *quark, Quark_Task_Flags *task_flags, int transA, int transB, int m, int n, int k, int nb, float alpha, float *A, int lda, float *B, int ldb, float beta, float *C, int ldc) |
| void | QUARK_CORE_sgemm_f2 (Quark *quark, Quark_Task_Flags *task_flags, int transA, int transB, int m, int n, int k, int nb, float alpha, float *A, int lda, float *B, int ldb, float beta, float *C, int ldc, float *fake1, int szefake1, int flag1, float *fake2, int szefake2, int flag2) |
| void | QUARK_CORE_sgemm_p2 (Quark *quark, Quark_Task_Flags *task_flags, int transA, int transB, int m, int n, int k, int nb, float alpha, float *A, int lda, float **B, int ldb, float beta, float *C, int ldc) |
| void | QUARK_CORE_sgemm_p2f1 (Quark *quark, Quark_Task_Flags *task_flags, int transA, int transB, int m, int n, int k, int nb, float alpha, float *A, int lda, float **B, int ldb, float beta, float *C, int ldc, float *fake1, int szefake1, int flag1) |
| void | QUARK_CORE_sgemm_p3 (Quark *quark, Quark_Task_Flags *task_flags, int transA, int transB, int m, int n, int k, int nb, float alpha, float *A, int lda, float *B, int ldb, float beta, float **C, int ldc) |
| void | QUARK_CORE_sgeqrt (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *A, int lda, float *T, int ldt) |
| void | QUARK_CORE_sgessm (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int k, int ib, int nb, int *IPIV, float *L, int ldl, float *A, int lda) |
| void | QUARK_CORE_sgetrf (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int nb, float *A, int lda, int *IPIV, PLASMA_sequence *sequence, PLASMA_request *request, PLASMA_bool check_info, int iinfo) |
| void | QUARK_CORE_sgetrf_incpiv (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *A, int lda, int *IPIV, PLASMA_sequence *sequence, PLASMA_request *request, PLASMA_bool check_info, int iinfo) |
| void | QUARK_CORE_sgetrf_reclap (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int nb, float *A, int lda, int *IPIV, PLASMA_sequence *sequence, PLASMA_request *request, PLASMA_bool check_info, int iinfo, int nbthread) |
| void | QUARK_CORE_sgetrf_rectil (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_desc A, float *Amn, int size, int *IPIV, PLASMA_sequence *sequence, PLASMA_request *request, PLASMA_bool check_info, int iinfo, int nbthread) |
| void | QUARK_CORE_sgetrip (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, float *A, int szeA) |
| void | QUARK_CORE_sgetrip_f1 (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, float *A, int szeA, float *fake, int szeF, int paramF) |
| void | QUARK_CORE_sgetrip_f2 (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, float *A, int szeA, float *fake1, int szeF1, int paramF1, float *fake2, int szeF2, int paramF2) |
| void | QUARK_CORE_ssymm (Quark *quark, Quark_Task_Flags *task_flags, int side, int uplo, int m, int n, int nb, float alpha, float *A, int lda, float *B, int ldb, float beta, float *C, int ldc) |
| void | QUARK_CORE_ssygst (Quark *quark, Quark_Task_Flags *task_flags, int itype, int uplo, int N, float *A, int LDA, float *B, int LDB, PLASMA_sequence *sequence, PLASMA_request *request, int iinfo) |
| void | QUARK_CORE_ssyrk (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int trans, int n, int k, int nb, float alpha, float *A, int lda, float beta, float *C, int ldc) |
| void | QUARK_CORE_ssyr2k (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int trans, int n, int k, int nb, float alpha, float *A, int lda, float *B, int LDB, float beta, float *C, int ldc) |
| void | QUARK_CORE_ssyrfb (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int n, int k, int ib, int nb, float *A, int lda, float *T, int ldt, float *C, int ldc) |
| void | QUARK_CORE_slacpy (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_enum uplo, int m, int n, int mb, float *A, int lda, float *B, int ldb) |
| void | QUARK_CORE_slange (Quark *quark, Quark_Task_Flags *task_flags, int norm, int M, int N, float *A, int LDA, int szeA, int szeW, float *result) |
| void | QUARK_CORE_slange_f1 (Quark *quark, Quark_Task_Flags *task_flags, int norm, int M, int N, float *A, int LDA, int szeA, int szeW, float *result, float *fake, int szeF) |
| void | QUARK_CORE_slansy (Quark *quark, Quark_Task_Flags *task_flags, int norm, int uplo, int N, float *A, int LDA, int szeA, int szeW, float *result) |
| void | QUARK_CORE_slansy_f1 (Quark *quark, Quark_Task_Flags *task_flags, int norm, int uplo, int N, float *A, int LDA, int szeA, int szeW, float *result, float *fake, int szeF) |
| void | QUARK_CORE_slaset (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_enum uplo, int n1, int n2, float alpha, float beta, float *tileA, int ldtilea) |
| void | QUARK_CORE_slaset2 (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_enum uplo, int n1, int n2, float alpha, float *tileA, int ldtilea) |
| void | QUARK_CORE_slaswp (Quark *quark, Quark_Task_Flags *task_flags, int n, float *A, int lda, int i1, int i2, int *ipiv, int inc) |
| void | QUARK_CORE_slaswp_f2 (Quark *quark, Quark_Task_Flags *task_flags, int n, float *A, int lda, int i1, int i2, int *ipiv, int inc, float *fake1, int szefake1, int flag1, float *fake2, int szefake2, int flag2) |
| void | QUARK_CORE_slaswp_ontile (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_desc descA, float *A, int i1, int i2, int *ipiv, int inc, float *fakepanel) |
| void | QUARK_CORE_slaswp_ontile_f2 (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_desc descA, float *A, int i1, int i2, int *ipiv, int inc, float *fake1, int szefake1, int flag1, float *fake2, int szefake2, int flag2) |
| void | QUARK_CORE_slaswpc_ontile (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_desc descA, float *A, int i1, int i2, int *ipiv, int inc, float *fakepanel) |
| void | QUARK_CORE_slauum (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int n, int nb, float *A, int lda) |
| void | QUARK_CORE_splgsy (Quark *quark, Quark_Task_Flags *task_flags, float bump, int m, int n, float *A, int lda, int bigM, int m0, int n0, unsigned long long int seed) |
| void | QUARK_CORE_splrnt (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, float *A, int lda, int bigM, int m0, int n0, unsigned long long int seed) |
| void | QUARK_CORE_spotrf (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int n, int nb, float *A, int lda, PLASMA_sequence *sequence, PLASMA_request *request, int iinfo) |
| void | QUARK_CORE_sshift (Quark *quark, Quark_Task_Flags *task_flags, int s, int m, int n, int L, float *A) |
| void | QUARK_CORE_sshiftw (Quark *quark, Quark_Task_Flags *task_flags, int s, int cl, int m, int n, int L, float *A, float *W) |
| void | QUARK_CORE_sssssm (Quark *quark, Quark_Task_Flags *task_flags, int m1, int n1, int m2, int n2, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *L1, int ldl1, float *L2, int ldl2, int *IPIV) |
| void | QUARK_CORE_sswpab (Quark *quark, Quark_Task_Flags *task_flags, int i, int n1, int n2, float *A, int szeA) |
| void | QUARK_CORE_sswptr_ontile (Quark *quark, Quark_Task_Flags *task_flags, PLASMA_desc descA, float *Aij, int i1, int i2, int *ipiv, int inc, float *Akk, int ldak) |
| void | QUARK_CORE_strdalg (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int N, int NB, PLASMA_desc *A, float *C, float *S, int i, int j, int m, int grsiz, int BAND, int *PCOL, int *ACOL, int *MCOL) |
| void | QUARK_CORE_strmm (Quark *quark, Quark_Task_Flags *task_flags, int side, int uplo, int transA, int diag, int m, int n, int nb, float alpha, float *A, int lda, float *B, int ldb) |
| void | QUARK_CORE_strmm_p2 (Quark *quark, Quark_Task_Flags *task_flags, int side, int uplo, int transA, int diag, int m, int n, int nb, float alpha, float *A, int lda, float **B, int ldb) |
| void | QUARK_CORE_strsm (Quark *quark, Quark_Task_Flags *task_flags, int side, int uplo, int transA, int diag, int m, int n, int nb, float alpha, float *A, int lda, float *B, int ldb) |
| void | QUARK_CORE_strtri (Quark *quark, Quark_Task_Flags *task_flags, int uplo, int diag, int n, int nb, float *A, int lda, PLASMA_sequence *sequence, PLASMA_request *request, int iinfo) |
| void | QUARK_CORE_stslqt (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *T, int ldt) |
| void | QUARK_CORE_stsmlq (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_stsmlq_sytra1 (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_stsmlq_corner (Quark *quark, Quark_Task_Flags *task_flags, int m1, int n1, int m2, int n2, int m3, int n3, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *A3, int lda3, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_stsmqr (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_stsmqr_sytra1 (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_stsmqr_corner (Quark *quark, Quark_Task_Flags *task_flags, int m1, int n1, int m2, int n2, int m3, int n3, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *A3, int lda3, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_stsqrt (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *T, int ldt) |
| void | QUARK_CORE_ststrf (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *U, int ldu, float *A, int lda, float *L, int ldl, int *IPIV, PLASMA_sequence *sequence, PLASMA_request *request, PLASMA_bool check_info, int iinfo) |
| void | QUARK_CORE_sttmqr (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_sttqrt (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *T, int ldt) |
| void | QUARK_CORE_sttmlq (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m1, int n1, int m2, int n2, int k, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *T, int ldt) |
| void | QUARK_CORE_sttlqt (Quark *quark, Quark_Task_Flags *task_flags, int m, int n, int ib, int nb, float *A1, int lda1, float *A2, int lda2, float *T, int ldt) |
| void | QUARK_CORE_spamm (Quark *quark, Quark_Task_Flags *task_flags, int op, int side, int storev, int m, int n, int k, int l, float *A1, int lda1, float *A2, int lda2, float *V, int ldv, float *W, int ldw) |
| void | QUARK_CORE_sormlq (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m, int n, int ib, int nb, int k, float *A, int lda, float *T, int ldt, float *C, int ldc) |
| void | QUARK_CORE_sormqr (Quark *quark, Quark_Task_Flags *task_flags, int side, int trans, int m, int n, int k, int ib, int nb, float *A, int lda, float *T, int ldt, float *C, int ldc) |
| void | CORE_sasum_quark (Quark *quark) |
| void | CORE_sasum_f1_quark (Quark *quark) |
| void | CORE_sgeadd_quark (Quark *quark) |
| void | CORE_sbrdalg_quark (Quark *quark) |
| void | CORE_sgelqt_quark (Quark *quark) |
| void | CORE_sgemm_quark (Quark *quark) |
| void | CORE_sgeqrt_quark (Quark *quark) |
| void | CORE_sgessm_quark (Quark *quark) |
| void | CORE_sgetrf_quark (Quark *quark) |
| void | CORE_sgetrf_incpiv_quark (Quark *quark) |
| void | CORE_sgetrf_reclap_quark (Quark *quark) |
| void | CORE_sgetrf_rectil_quark (Quark *quark) |
| void | CORE_sgetrip_quark (Quark *quark) |
| void | CORE_sgetrip_f1_quark (Quark *quark) |
| void | CORE_sgetrip_f2_quark (Quark *quark) |
| void | CORE_ssygst_quark (Quark *quark) |
| void | CORE_ssyrfb_quark (Quark *quark) |
| void | CORE_slacpy_quark (Quark *quark) |
| void | CORE_slange_quark (Quark *quark) |
| void | CORE_slange_f1_quark (Quark *quark) |
| void | CORE_slansy_quark (Quark *quark) |
| void | CORE_slansy_f1_quark (Quark *quark) |
| void | CORE_slaset_quark (Quark *quark) |
| void | CORE_slaset2_quark (Quark *quark) |
| void | CORE_slauum_quark (Quark *quark) |
| void | CORE_spamm_quark (Quark *quark) |
| void | CORE_splgsy_quark (Quark *quark) |
| void | CORE_splrnt_quark (Quark *quark) |
| void | CORE_spotrf_quark (Quark *quark) |
| void | CORE_sshift_quark (Quark *quark) |
| void | CORE_sshiftw_quark (Quark *quark) |
| void | CORE_sssssm_quark (Quark *quark) |
| void | CORE_ssymm_quark (Quark *quark) |
| void | CORE_ssyrk_quark (Quark *quark) |
| void | CORE_ssyr2k_quark (Quark *quark) |
| void | CORE_sswpab_quark (Quark *quark) |
| void | CORE_sswptr_ontile_quark (Quark *quark) |
| void | CORE_strdalg_quark (Quark *quark) |
| void | CORE_strmm_quark (Quark *quark) |
| void | CORE_strsm_quark (Quark *quark) |
| void | CORE_strtri_quark (Quark *quark) |
| void | CORE_stslqt_quark (Quark *quark) |
| void | CORE_stsmlq_quark (Quark *quark) |
| void | CORE_stsmlq_sytra1_quark (Quark *quark) |
| void | CORE_stsmlq_corner_quark (Quark *quark) |
| void | CORE_stsmqr_quark (Quark *quark) |
| void | CORE_stsmqr_sytra1_quark (Quark *quark) |
| void | CORE_stsmqr_corner_quark (Quark *quark) |
| void | CORE_stsqrt_quark (Quark *quark) |
| void | CORE_ststrf_quark (Quark *quark) |
| void | CORE_sttmqr_quark (Quark *quark) |
| void | CORE_sttqrt_quark (Quark *quark) |
| void | CORE_sttmlq_quark (Quark *quark) |
| void | CORE_sttlqt_quark (Quark *quark) |
| void | CORE_sormlq_quark (Quark *quark) |
| void | CORE_sormqr_quark (Quark *quark) |
| void | CORE_slaswp_quark (Quark *quark) |
| void | CORE_slaswp_f2_quark (Quark *quark) |
| void | CORE_slaswp_ontile_quark (Quark *quark) |
| void | CORE_slaswp_ontile_f2_quark (Quark *quark) |
| void | CORE_slaswpc_ontile_quark (Quark *quark) |
| void | CORE_strmm_p2_quark (Quark *quark) |
| void | CORE_sgemm_f2_quark (Quark *quark) |
| void | CORE_sgemm_p2_quark (Quark *quark) |
| void | CORE_sgemm_p2f1_quark (Quark *quark) |
| void | CORE_sgemm_p3_quark (Quark *quark) |
PLASMA auxiliary routines PLASMA is a software package provided by Univ. of Tennessee, Univ. of California Berkeley and Univ. of Colorado Denver
Definition in file core_sblas.h.
| #define REAL |
Definition at line 21 of file core_sblas.h.
| void CORE_sasum | ( | int | storev, |
| int | uplo, | ||
| int | M, | ||
| int | N, | ||
| float * | A, | ||
| int | lda, | ||
| float * | work | ||
| ) |
Definition at line 28 of file core_sasum.c.
References PlasmaColumnwise, PlasmaLower, PlasmaUpper, PlasmaUpperLower, and sum().

| void CORE_sasum_f1_quark | ( | Quark * | quark | ) |
Definition at line 162 of file core_sasum.c.
References A, CORE_sasum(), quark_unpack_args_8, storev, and uplo.


| void CORE_sasum_quark | ( | Quark * | quark | ) |
Definition at line 119 of file core_sasum.c.
References A, CORE_sasum(), quark_unpack_args_7, storev, and uplo.


| void CORE_sbrdalg | ( | PLASMA_enum | uplo, |
| int | N, | ||
| int | NB, | ||
| PLASMA_desc * | pA, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | i, | ||
| int | j, | ||
| int | m, | ||
| int | grsiz | ||
| ) |
CORE_sbrdalg is a part of the bidiagonal reduction algorithm (bulgechasing). It correspond to a local driver of the kernels that should be executed on a single core.
| [in] | uplo |
|
| [in] | N | The order of the matrix A. N >= 0. |
| [in] | NB | The size of the Bandwidth of the matrix A, which correspond to the tile size. NB >= 0. |
| [in] | pA | A pointer to the descriptor of the matrix A. |
| [out] | V | float array, dimension (N). The scalar elementary reflectors are written in this array. So it is used as a workspace for V at each step of the bulge chasing algorithm. |
| [out] | TAU | float array, dimension (N). The scalar factors of the elementary reflectors are written in thisarray. So it is used as a workspace for TAU at each step of the bulge chasing algorithm. |
| [in] | i | Integer that refer to the current sweep. (outer loop). |
| [in] | j | Integer that refer to the sweep to chase.(inner loop). |
| [in] | m | Integer that refer to a sweep step, to ensure order dependencies. |
| [in] | grsiz | Integer that refer to the size of a group. group mean the number of kernel that should be executed sequentially on the same core. group size is a trade-off between locality (cache reuse) and parallelism. a small group size increase parallelism while a large group size increase cache reuse. |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 83 of file core_sbrdalg.c.
References A, CORE_sgbelr(), CORE_sgblrx(), CORE_sgbrce(), plasma_desc_t::dtyp, min, and plasma_element_size().

| void CORE_sbrdalg_quark | ( | Quark * | quark | ) |
Definition at line 161 of file core_sbrdalg.c.
References CORE_sbrdalg(), quark_unpack_args_10, TAU, uplo, and V.

| int CORE_sgbelr | ( | int | uplo, |
| int | N, | ||
| PLASMA_desc * | A, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | st, | ||
| int | ed, | ||
| int | eltsize | ||
| ) |
Definition at line 78 of file core_sgbelr.c.
References A, CORE_slarfx2(), CORE_slarfx2ce(), coreblas_error, ELTLDD, max, plasma_desc_t::mb, min, PLASMA_SUCCESS, PlasmaLeft, PlasmaLower, PlasmaRight, PlasmaUpper, TAU, and V.

| int CORE_sgblrx | ( | int | uplo, |
| int | N, | ||
| PLASMA_desc * | A, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | st, | ||
| int | ed, | ||
| int | eltsize | ||
| ) |
Definition at line 78 of file core_sgblrx.c.
References A, CORE_slarfx2(), CORE_slarfx2ce(), coreblas_error, ELTLDD, max, plasma_desc_t::mb, min, PLASMA_SUCCESS, PlasmaLeft, PlasmaLower, PlasmaRight, PlasmaUpper, TAU, and V.

| int CORE_sgbrce | ( | int | uplo, |
| int | N, | ||
| PLASMA_desc * | A, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | st, | ||
| int | ed, | ||
| int | eltsize | ||
| ) |
Definition at line 76 of file core_sgbrce.c.
References A, CORE_slarfx2(), coreblas_error, ELTLDD, max, plasma_desc_t::mb, min, PLASMA_SUCCESS, PlasmaLeft, PlasmaLower, PlasmaRight, TAU, and V.


| void CORE_sgeadd | ( | int | M, |
| int | N, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB | ||
| ) |
Definition at line 26 of file core_sgeadd.c.
References cblas_saxpy().


| void CORE_sgeadd_quark | ( | Quark * | quark | ) |
Definition at line 67 of file core_sgeadd.c.
References A, B, cblas_saxpy(), and quark_unpack_args_7.


| int CORE_sgelqt | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | TAU, | ||
| float * | WORK | ||
| ) |
CORE_sgelqt - computes a LQ factorization of a complex M-by-N tile A: A = L * Q.
The tile Q is represented as a product of elementary reflectors
Q = H(k)' . . . H(2)' H(1)', where k = min(M,N).
Each H(i) has the form
H(i) = I - tau * v * v'
where tau is a complex scalar, and v is a complex vector with v(1:i-1) = 0 and v(i) = 1; g(v(i+1:n)) is stored on exit in A(i,i+1:n), and tau in TAU(i).
| [in] | M | The number of rows of the tile A. M >= 0. |
| [in] | N | The number of columns of the tile A. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A | On entry, the M-by-N tile A. On exit, the elements on and below the diagonal of the array contain the M-by-min(M,N) lower trapezoidal tile L (L is lower triangular if M <= N); the elements above the diagonal, with the array TAU, represent the unitary tile Q as a product of elementary reflectors (see Further Details). |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,M). |
| [out] | T | The IB-by-N triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | TAU | The scalar factors of the elementary reflectors (see Further Details). |
| [out] | WORK |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 85 of file core_sgelqt.c.
References coreblas_error, lapack_const, max, min, PLASMA_SUCCESS, PlasmaForward, PlasmaNoTrans, PlasmaRight, and PlasmaRowwise.
| void CORE_sgelqt_quark | ( | Quark * | quark | ) |
Definition at line 180 of file core_sgelqt.c.
References A, CORE_sgelqt(), quark_unpack_args_9, T, and TAU.


| void CORE_sgemm | ( | int | transA, |
| int | transB, | ||
| int | M, | ||
| int | N, | ||
| int | K, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB, | ||
| float | beta, | ||
| float * | C, | ||
| int | LDC | ||
| ) |
Definition at line 28 of file core_sgemm.c.
References cblas_sgemm(), and CblasColMajor.

| void CORE_sgemm_f2_quark | ( | Quark * | quark | ) |
Definition at line 171 of file core_sgemm.c.
References A, B, C, cblas_sgemm(), CblasColMajor, and quark_unpack_args_15.

| void CORE_sgemm_p2_quark | ( | Quark * | quark | ) |
Definition at line 234 of file core_sgemm.c.
References A, B, C, cblas_sgemm(), CblasColMajor, and quark_unpack_args_13.


| void CORE_sgemm_p2f1_quark | ( | Quark * | quark | ) |
Definition at line 360 of file core_sgemm.c.
References A, B, C, cblas_sgemm(), CblasColMajor, and quark_unpack_args_14.


| void CORE_sgemm_p3_quark | ( | Quark * | quark | ) |
Definition at line 296 of file core_sgemm.c.
References A, B, C, cblas_sgemm(), CblasColMajor, and quark_unpack_args_13.


| void CORE_sgemm_quark | ( | Quark * | quark | ) |
Definition at line 106 of file core_sgemm.c.
References A, B, C, cblas_sgemm(), CblasColMajor, and quark_unpack_args_13.

| int CORE_sgeqrt | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | TAU, | ||
| float * | WORK | ||
| ) |
CORE_sgeqrt computes a QR factorization of a complex M-by-N tile A: A = Q * R.
The tile Q is represented as a product of elementary reflectors
Q = H(1) H(2) . . . H(k), where k = min(M,N).
Each H(i) has the form
H(i) = I - tau * v * v'
where tau is a complex scalar, and v is a complex vector with v(1:i-1) = 0 and v(i) = 1; v(i+1:m) is stored on exit in A(i+1:m,i), and tau in TAU(i).
| [in] | M | The number of rows of the tile A. M >= 0. |
| [in] | N | The number of columns of the tile A. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A | On entry, the M-by-N tile A. On exit, the elements on and above the diagonal of the array contain the min(M,N)-by-N upper trapezoidal tile R (R is upper triangular if M >= N); the elements below the diagonal, with the array TAU, represent the unitary tile Q as a product of elementary reflectors (see Further Details). |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,M). |
| [out] | T | The IB-by-N triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | TAU | The scalar factors of the elementary reflectors (see Further Details). |
| [out] | WORK |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 86 of file core_sgeqrt.c.
References coreblas_error, lapack_const, max, min, PLASMA_SUCCESS, PlasmaColumnwise, PlasmaForward, PlasmaLeft, and PlasmaTrans.
| void CORE_sgeqrt_quark | ( | Quark * | quark | ) |
Definition at line 181 of file core_sgeqrt.c.
References A, CORE_sgeqrt(), quark_unpack_args_9, T, and TAU.


| int CORE_sgessm | ( | int | M, |
| int | N, | ||
| int | K, | ||
| int | IB, | ||
| int * | IPIV, | ||
| float * | L, | ||
| int | LDL, | ||
| float * | A, | ||
| int | LDA | ||
| ) |
CORE_sgessm applies the factor L computed by CORE_sgetrf_incpiv to a complex M-by-N tile A.
| [in] | M | The number of rows of the tile A. M >= 0. |
| [in] | N | The number of columns of the tile A. N >= 0. |
| [in] | K | |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in] | IPIV | as returned by CORE_sgetrf_incpiv. |
| [in] | L | The NB-by-NB lower triangular tile. |
| [in] | LDL | The leading dimension of the array L. LDL >= max(1,NB). |
| [in,out] | A | On entry, the M-by-N tile A. On exit, updated by the application of L. |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,M). |
| PLASMA_SUCCESS | successful exit |
| <0 | if INFO = -k, the k-th argument had an illegal value |
Definition at line 68 of file core_sgessm.c.
References cblas_sgemm(), cblas_strsm(), CblasColMajor, CblasLeft, CblasLower, CblasNoTrans, CblasUnit, coreblas_error, max, min, and PLASMA_SUCCESS.
| void CORE_sgessm_quark | ( | Quark * | quark | ) |
Definition at line 172 of file core_sgessm.c.
References A, CORE_sgessm(), IPIV, L, and quark_unpack_args_9.


| int CORE_sgetrf | ( | int | M, |
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| int * | IPIV, | ||
| int * | INFO | ||
| ) |
Definition at line 22 of file core_sgetrf.c.
References PLASMA_SUCCESS.
| int CORE_sgetrf_incpiv | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| float * | A, | ||
| int | LDA, | ||
| int * | IPIV, | ||
| int * | INFO | ||
| ) |
CORE_sgetrf_incpiv computes an LU factorization of a general M-by-N tile A using partial pivoting with row interchanges.
The factorization has the form
A = P * L * U
where P is a permutation matrix, L is lower triangular with unit diagonal elements (lower trapezoidal if m > n), and U is upper triangular (upper trapezoidal if m < n).
This is the right-looking Level 2.5 BLAS version of the algorithm.
| [in] | M | The number of rows of the tile A. M >= 0. |
| [in] | N | The number of columns of the tile A. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A | On entry, the M-by-N tile to be factored. On exit, the factors L and U from the factorization A = P*L*U; the unit diagonal elements of L are not stored. |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,M). |
| [out] | IPIV | The pivot indices; for 1 <= i <= min(M,N), row i of the tile was interchanged with row IPIV(i). |
| [out] | INFO | See returned value. |
| PLASMA_SUCCESS | successful exit |
| <0 | if INFO = -k, the k-th argument had an illegal value |
| >0 | if INFO = k, U(k,k) is exactly zero. The factorization has been completed, but the factor U is exactly singular, and division by zero will occur if it is used to solve a system of equations. |
Definition at line 83 of file core_sgetrf_incpiv.c.
References CORE_sgessm(), coreblas_error, max, min, and PLASMA_SUCCESS.

| void CORE_sgetrf_incpiv_quark | ( | Quark * | quark | ) |
Definition at line 174 of file core_sgetrf_incpiv.c.
References A, CORE_sgetrf_incpiv(), IPIV, plasma_sequence_flush(), PLASMA_SUCCESS, and quark_unpack_args_10.


| void CORE_sgetrf_quark | ( | Quark * | quark | ) |
Definition at line 61 of file core_sgetrf.c.
References A, IPIV, plasma_sequence_flush(), PLASMA_SUCCESS, and quark_unpack_args_9.

| int CORE_sgetrf_reclap | ( | const int | M, |
| const int | N, | ||
| float * | A, | ||
| const int | LDA, | ||
| int * | IPIV, | ||
| int * | info | ||
| ) |
Definition at line 307 of file core_sgetrf_reclap.c.
References coreblas_error, max, min, and PLASMA_SUCCESS.

| void CORE_sgetrf_reclap_quark | ( | Quark * | quark | ) |
Definition at line 381 of file core_sgetrf_reclap.c.
References A, CORE_sgetrf_reclap(), IPIV, plasma_sequence_flush(), PLASMA_SUCCESS, QUARK_Get_RankInTask(), and quark_unpack_args_10.
| int CORE_sgetrf_rectil | ( | const PLASMA_desc | A, |
| int * | IPIV, | ||
| int * | info | ||
| ) |
Definition at line 653 of file core_sgetrf_rectil.c.
References coreblas_error, plasma_desc_t::m, min, plasma_desc_t::mt, plasma_desc_t::n, and plasma_desc_t::nt.

| void CORE_sgetrf_rectil_quark | ( | Quark * | quark | ) |
Definition at line 726 of file core_sgetrf_rectil.c.
References A, CORE_sgetrf_rectil(), IPIV, plasma_sequence_flush(), PLASMA_SUCCESS, QUARK_Get_RankInTask(), and quark_unpack_args_8.
| void CORE_sgetrip | ( | int | m, |
| int | n, | ||
| float * | A, | ||
| float * | W | ||
| ) |
CORE_sgetrip transposes a m-by-n matrix in place using an extra workspace of size m-by-n. Note : For square tile, workspace is not used.
| [in] | m | Number of lines of tile A |
| [in] | n | Number of columns of tile A |
| [in,out] | A | Tile of size m-by-n On exit, A = trans(A) |
| [out] | W | Workspace of size n-by-m if n != m, NULL otherwise. |
Definition at line 54 of file core_sgetrip.c.
| void CORE_sgetrip_f1_quark | ( | Quark * | quark | ) |
Definition at line 138 of file core_sgetrip.c.
References A, CORE_sgetrip(), quark_unpack_args_5, and W.


| void CORE_sgetrip_f2_quark | ( | Quark * | quark | ) |
Definition at line 178 of file core_sgetrip.c.
References A, CORE_sgetrip(), quark_unpack_args_6, and W.


| void CORE_sgetrip_quark | ( | Quark * | quark | ) |
Definition at line 101 of file core_sgetrip.c.
References A, CORE_sgetrip(), quark_unpack_args_4, and W.


| int CORE_shbelr | ( | int | uplo, |
| int | N, | ||
| PLASMA_desc * | A, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | st, | ||
| int | ed, | ||
| int | eltsize | ||
| ) |
Definition at line 78 of file core_shbelr.c.
References A, CORE_slarfx2(), CORE_slarfx2c(), coreblas_error, ELTLDD, max, plasma_desc_t::mb, min, PLASMA_SUCCESS, PlasmaLeft, PlasmaLower, PlasmaRight, PlasmaUpper, TAU, and V.

| int CORE_shblrx | ( | int | uplo, |
| int | N, | ||
| PLASMA_desc * | A, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | st, | ||
| int | ed, | ||
| int | eltsize | ||
| ) |
Definition at line 76 of file core_shblrx.c.
References A, CORE_slarfx2(), CORE_slarfx2c(), coreblas_error, ELTLDD, max, plasma_desc_t::mb, min, PLASMA_SUCCESS, PlasmaLeft, PlasmaLower, PlasmaRight, PlasmaUpper, TAU, and V.

| int CORE_shbrce | ( | int | uplo, |
| int | N, | ||
| PLASMA_desc * | A, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | st, | ||
| int | ed, | ||
| int | eltsize | ||
| ) |
Definition at line 76 of file core_shbrce.c.
References A, CORE_slarfx2(), coreblas_error, ELTLDD, max, plasma_desc_t::mb, min, PLASMA_SUCCESS, PlasmaLeft, PlasmaLower, PlasmaRight, TAU, and V.


| void CORE_slacpy | ( | PLASMA_enum | uplo, |
| int | M, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB | ||
| ) |
Definition at line 29 of file core_slacpy.c.
References lapack_const.
| void CORE_slacpy_quark | ( | Quark * | quark | ) |
Definition at line 66 of file core_slacpy.c.
References A, B, lapack_const, quark_unpack_args_7, and uplo.
| void CORE_slange | ( | int | norm, |
| int | M, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | work, | ||
| float * | normA | ||
| ) |
Definition at line 29 of file core_slange.c.
References lapack_const.
| void CORE_slange_f1_quark | ( | Quark * | quark | ) |
Definition at line 114 of file core_slange.c.
References A, lapack_const, norm, and quark_unpack_args_8.

| void CORE_slange_quark | ( | Quark * | quark | ) |
Definition at line 67 of file core_slange.c.
References A, lapack_const, norm, and quark_unpack_args_7.
| void CORE_slansy | ( | int | norm, |
| int | uplo, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | work, | ||
| float * | normA | ||
| ) |
Definition at line 29 of file core_slansy.c.
References lapack_const.

| void CORE_slansy_f1_quark | ( | Quark * | quark | ) |
Definition at line 114 of file core_slansy.c.
References A, lapack_const, norm, quark_unpack_args_8, and uplo.

| void CORE_slansy_quark | ( | Quark * | quark | ) |
Definition at line 67 of file core_slansy.c.
References A, lapack_const, norm, quark_unpack_args_7, and uplo.

| int CORE_slarfx2 | ( | PLASMA_enum | side, |
| int | N, | ||
| float | V, | ||
| float | TAU, | ||
| float * | C1, | ||
| int | LDC1, | ||
| float * | C2, | ||
| int | LDC2 | ||
| ) |
CORE_slarfx2 applies a complex elementary reflector H to a complex m by n matrix C, from either the left or the right. H is represented in the form
H = I - tau * v * v'
where tau is a complex scalar and v is a complex vector.
If tau = 0, then H is taken to be the unit matrix
This version uses inline code if H has order < 11.
| [in] | side |
|
| [in] | N | The number of columns of C1 and C2 if side = PlasmaLeft. The number of rows of C1 and C2 if side = PlasmaRight. |
| [in] | V | The float complex V in the representation of H. |
| [in] | TAU | The value tau in the representation of H. |
| [in,out] | C1 | dimension (LDC1,N), if side = PlasmaLeft dimension (LDC1,1), if side = PlasmaRight On entry, the m by n matrix C1. On exit, C1 is overwritten by the matrix H * C1 if SIDE = PlasmaLeft, or C1 * H if SIDE = PlasmaRight. |
| [in] | LDC1 | The leading dimension of the array C1. LDC1 >= max(1,N), if side == PlasmaRight. LDC1 >= 1, otherwise. |
| [in,out] | C2 | dimension (LDC2,N), if side = PlasmaLeft dimension (LDC2,1), if side = PlasmaRight On entry, the m by n matrix C2. On exit, C2 is overwritten by the matrix H * C2 if SIDE = PlasmaLeft, or C2 * H if SIDE = PlasmaRight. |
| [in] | LDC2 | The leading dimension of the array C2. LDC2 >= max(1,N), if side == PlasmaRight. LDC2 >= 1, otherwise. |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 86 of file core_slarfx_tbrd.c.
References PLASMA_SUCCESS, PlasmaLeft, T2, TAU, and V.
| int CORE_slarfx2c | ( | PLASMA_enum | uplo, |
| float | V, | ||
| float | TAU, | ||
| float * | C1, | ||
| float * | C2, | ||
| float * | C3 | ||
| ) |
CORE_slarfx2c applies a complex elementary reflector H to a diagonal corner C=[C1, C2, C3], from both the left and the right side. C = H * C * H. It is used in the case of Hermetian. If PlasmaLower, a left apply is followed by a right apply. If PlasmaUpper, a right apply is followed by a left apply. H is represented in the form
This routine is a special code for a corner C diagonal block C1 C2 C3
H = I - tau * v * v'
where tau is a complex scalar and v is a complex vector.
If tau = 0, then H is taken to be the unit matrix
This version uses inline code if H has order < 11.
| [in] | uplo | = PlasmaUpper: Upper triangle of A is stored; = PlasmaLower: Lower triangle of A is stored. |
| [in] | V | The float complex V in the representation of H. |
| [in] | TAU | The value tau in the representation of H. |
| [in,out] | C1 | On entry, the element C1. On exit, C1 is overwritten by the result H * C * H. |
| [in,out] | C2 | On entry, the element C2. On exit, C2 is overwritten by the result H * C * H. |
| [in,out] | C3 | On entry, the element C3. On exit, C3 is overwritten by the result H * C * H. |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 185 of file core_slarfx_tbrd.c.
References PLASMA_SUCCESS, PlasmaLower, T2, TAU, and V.

| int CORE_slarfx2ce | ( | PLASMA_enum | uplo, |
| float * | V, | ||
| float * | TAU, | ||
| float * | C1, | ||
| float * | C2, | ||
| float * | C3 | ||
| ) |
CORE_slarfx2c applies a complex elementary reflector H to a diagonal corner C=[C1, C2, C3], from both the left and the right side. C = H * C * H. It is used in the case of general matrices, where it create a nnz at the NEW_NNZ position, then it eliminate it and update the reflector V and TAU. If PlasmaLower, a left apply is followed by a right apply. If PlasmaUpper, a right apply is followed by a left apply. H is represented in the form
This routine is a special code for a corner C diagonal block C1 NEW_NNZ C2 C3
H = I - tau * v * v'
where tau is a complex scalar and v is a complex vector.
If tau = 0, then H is taken to be the unit matrix
This version uses inline code if H has order < 11.
| [in] | uplo | = PlasmaUpper: Upper triangle of A is stored; = PlasmaLower: Lower triangle of A is stored. |
| [in,out] | V | On entry, the float complex V in the representation of H. On exit, the float complex V in the representation of H, updated by the elimination of the NEW_NNZ created by the left apply in case of PlasmaLower or the right apply in case of PlasmaUpper. |
| [in] | TAU | On entry, the value tau in the representation of H. On exit, the value tau in the representation of H, updated by the elimination of the NEW_NNZ created by the left apply in case of PlasmaLower or the right apply in case of PlasmaUpper. |
| [in,out] | C1 | On entry, the element C1. On exit, C1 is overwritten by the result H * C * H. |
| [in,out] | C2 | On entry, the element C2. On exit, C2 is overwritten by the result H * C * H. |
| [in,out] | C3 | On entry, the element C3. On exit, C3 is overwritten by the result H * C * H. |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 335 of file core_slarfx_tbrd.c.
References PLASMA_SUCCESS, PlasmaLower, PlasmaUpper, T2, and V.

| void CORE_slaset | ( | PLASMA_enum | uplo, |
| int | M, | ||
| int | N, | ||
| float | alpha, | ||
| float | beta, | ||
| float * | A, | ||
| int | LDA | ||
| ) |
CORE_slaset - Sets the elements of the matrix A on the diagonal to beta and on the off-diagonals to alpha
| [in] | uplo | Specifies which elements of the matrix are to be set = PlasmaUpper: Upper part of A is set; = PlasmaLower: Lower part of A is set; = PlasmaUpperLower: ALL elements of A are set. |
| [in] | M | The number of rows of the matrix A. M >= 0. |
| [in] | N | The number of columns of the matrix A. N >= 0. |
| [in] | alpha | The constant to which the off-diagonal elements are to be set. |
| [in] | beta | The constant to which the diagonal elements are to be set. |
| [in,out] | A | On entry, the M-by-N tile A. On exit, A has been set accordingly. |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,M). |
Definition at line 58 of file core_slaset.c.
References lapack_const.

| void CORE_slaset2 | ( | PLASMA_enum | uplo, |
| int | M, | ||
| int | N, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA | ||
| ) |
CORE_slaset2 - Sets the elements of the matrix A to alpha. Not LAPACK compliant! Read below.
| [in] | uplo | Specifies which elements of the matrix are to be set = PlasmaUpper: STRICT Upper part of A is set to alpha; = PlasmaLower: STRICT Lower part of A is set to alpha; = PlasmaUpperLower: ALL elements of A are set to alpha. Not LAPACK Compliant. |
| [in] | M | The number of rows of the matrix A. M >= 0. |
| [in] | N | The number of columns of the matrix A. N >= 0. |
| [in] | alpha | The constant to which the elements are to be set. |
| [in,out] | A | On entry, the M-by-N tile A. On exit, A has been set to alpha accordingly. |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,M). |
Definition at line 56 of file core_slaset2.c.
References lapack_const, PlasmaLower, and PlasmaUpper.

| void CORE_slaset2_quark | ( | Quark * | quark | ) |
Definition at line 103 of file core_slaset2.c.
References A, CORE_slaset2(), quark_unpack_args_6, and uplo.


| void CORE_slaset_quark | ( | Quark * | quark | ) |
Definition at line 95 of file core_slaset.c.
References A, lapack_const, quark_unpack_args_7, and uplo.

| void CORE_slaswp | ( | int | N, |
| float * | A, | ||
| int | LDA, | ||
| int | I1, | ||
| int | I2, | ||
| int * | IPIV, | ||
| int | INC | ||
| ) |
Definition at line 29 of file core_slaswp.c.
| void CORE_slaswp_f2_quark | ( | Quark * | quark | ) |
Definition at line 102 of file core_slaswp.c.
References A, and quark_unpack_args_9.
| int CORE_slaswp_ontile | ( | PLASMA_desc | descA, |
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc | ||
| ) |
CORE_slaswp_ontile apply the slaswp function on a matrix stored in tile layout
| [in,out] | A | The descriptor of the matrix A to permute. |
| [in] | i1 | The first element of IPIV for which a row interchange will be done. |
| [in] | i2 | The last element of IPIV for which a row interchange will be done. |
| [in] | ipiv | The pivot indices; Only the element in position i1 to i2 are accessed. The pivot are offset by A.i. |
| [in] | inc | The increment between successive values of IPIV. If IPIV is negative, the pivots are applied in reverse order. |
Definition at line 147 of file core_slaswp.c.
References A, BLKLDD, cblas_sswap(), coreblas_error, plasma_desc_t::i, plasma_desc_t::m, plasma_desc_t::mb, plasma_desc_t::mt, plasma_desc_t::n, plasma_desc_t::nt, and PLASMA_SUCCESS.


| void CORE_slaswp_ontile_f2_quark | ( | Quark * | quark | ) |
Definition at line 279 of file core_slaswp.c.
References A, CORE_slaswp_ontile(), and quark_unpack_args_8.

| void CORE_slaswp_ontile_quark | ( | Quark * | quark | ) |
Definition at line 238 of file core_slaswp.c.
References A, CORE_slaswp_ontile(), and quark_unpack_args_7.


| void CORE_slaswp_quark | ( | Quark * | quark | ) |
Definition at line 61 of file core_slaswp.c.
References A, and quark_unpack_args_7.
| int CORE_slaswpc_ontile | ( | PLASMA_desc | descA, |
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc | ||
| ) |
CORE_slaswpc_ontile apply the slaswp function on a matrix stored in tile layout
| [in,out] | A | The descriptor of the matrix A to permute. |
| [in] | i1 | The first element of IPIV for which a column interchange will be done. |
| [in] | i2 | The last element of IPIV for which a column interchange will be done. |
| [in] | ipiv | The pivot indices; Only the element in position i1 to i2 are accessed. The pivot are offset by A.i. |
| [in] | inc | The increment between successive values of IPIV. If IPIV is negative, the pivots are applied in reverse order. |
Definition at line 430 of file core_slaswp.c.
References A, BLKLDD, cblas_sswap(), coreblas_error, plasma_desc_t::j, plasma_desc_t::m, plasma_desc_t::mt, plasma_desc_t::n, plasma_desc_t::nb, and PLASMA_SUCCESS.


| void CORE_slaswpc_ontile_quark | ( | Quark * | quark | ) |
Definition at line 516 of file core_slaswp.c.
References A, CORE_slaswpc_ontile(), and quark_unpack_args_7.


| void CORE_slauum | ( | int | uplo, |
| int | N, | ||
| float * | A, | ||
| int | LDA | ||
| ) |
Definition at line 29 of file core_slauum.c.
References lapack_const.
| void CORE_slauum_quark | ( | Quark * | quark | ) |
Definition at line 57 of file core_slauum.c.
References A, lapack_const, quark_unpack_args_4, and uplo.

| int CORE_sormlq | ( | int | side, |
| int | trans, | ||
| int | M, | ||
| int | N, | ||
| int | K, | ||
| int | IB, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | C, | ||
| int | LDC, | ||
| float * | WORK, | ||
| int | LDWORK | ||
| ) |
CORE_sormlq overwrites the general complex M-by-N tile C with
SIDE = 'L' SIDE = 'R'
TRANS = 'N': Q * C C * Q TRANS = 'C': Q**T * C C * Q**T
where Q is a complex unitary matrix defined as the product of k elementary reflectors
Q = H(k) . . . H(2) H(1)
as returned by CORE_sgelqt. Q is of order M if SIDE = 'L' and of order N if SIDE = 'R'.
| [in] | side |
|
| [in] | trans |
|
| [in] | M | The number of rows of the tile C. M >= 0. |
| [in] | N | The number of columns of the tile C. N >= 0. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. If SIDE = PlasmaLeft, M >= K >= 0; if SIDE = PlasmaRight, N >= K >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in] | A | Dimension: (LDA,M) if SIDE = PlasmaLeft, (LDA,N) if SIDE = PlasmaRight, The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_sgelqt in the first k rows of its array argument A. |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,K). |
| [out] | T | The IB-by-K triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [in,out] | C | On entry, the M-by-N tile C. On exit, C is overwritten by Q*C or Q**T*C or C*Q**T or C*Q. |
| [in] | LDC | The leading dimension of the array C. LDC >= max(1,M). |
| [in,out] | WORK | On exit, if INFO = 0, WORK(1) returns the optimal LDWORK. |
| [in] | LDWORK | The dimension of the array WORK. If SIDE = PlasmaLeft, LDWORK >= max(1,N); if SIDE = PlasmaRight, LDWORK >= max(1,M). |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 108 of file core_sormlq.c.
References coreblas_error, lapack_const, max, min, PLASMA_SUCCESS, PlasmaForward, PlasmaLeft, PlasmaNoTrans, PlasmaRight, PlasmaRowwise, and PlasmaTrans.
| void CORE_sormlq_quark | ( | Quark * | quark | ) |
Definition at line 264 of file core_sormlq.c.
References A, C, CORE_sormlq(), quark_unpack_args_14, side, T, and trans.

| int CORE_sormqr | ( | int | side, |
| int | trans, | ||
| int | M, | ||
| int | N, | ||
| int | K, | ||
| int | IB, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | C, | ||
| int | LDC, | ||
| float * | WORK, | ||
| int | LDWORK | ||
| ) |
CORE_sormqr overwrites the general complex M-by-N tile C with
SIDE = 'L' SIDE = 'R'
TRANS = 'N': Q * C C * Q TRANS = 'C': Q**T * C C * Q**T
where Q is a complex unitary matrix defined as the product of k elementary reflectors
Q = H(1) H(2) . . . H(k)
as returned by CORE_sgeqrt. Q is of order M if SIDE = 'L' and of order N if SIDE = 'R'.
| [in] | side |
|
| [in] | trans |
|
| [in] | M | The number of rows of the tile C. M >= 0. |
| [in] | N | The number of columns of the tile C. N >= 0. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. If SIDE = PlasmaLeft, M >= K >= 0; if SIDE = PlasmaRight, N >= K >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in] | A | Dimension: (LDA,K) The i-th column must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_sgeqrt in the first k columns of its array argument A. |
| [in] | LDA | The leading dimension of the array A. If SIDE = PlasmaLeft, LDA >= max(1,M); if SIDE = PlasmaRight, LDA >= max(1,N). |
| [out] | T | The IB-by-K triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [in,out] | C | On entry, the M-by-N tile C. On exit, C is overwritten by Q*C or Q**T*C or C*Q**T or C*Q. |
| [in] | LDC | The leading dimension of the array C. LDC >= max(1,M). |
| [in,out] | WORK | On exit, if INFO = 0, WORK(1) returns the optimal LDWORK. |
| [in] | LDWORK | The dimension of the array WORK. If SIDE = PlasmaLeft, LDWORK >= max(1,N); if SIDE = PlasmaRight, LDWORK >= max(1,M). |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 108 of file core_sormqr.c.
References coreblas_error, lapack_const, max, min, PLASMA_SUCCESS, PlasmaColumnwise, PlasmaForward, PlasmaLeft, PlasmaNoTrans, PlasmaRight, and PlasmaTrans.
| void CORE_sormqr_quark | ( | Quark * | quark | ) |
Definition at line 257 of file core_sormqr.c.
References A, C, CORE_sormqr(), quark_unpack_args_14, side, T, and trans.

| int CORE_spamm | ( | int | op, |
| int | side, | ||
| int | storev, | ||
| int | M, | ||
| int | N, | ||
| int | K, | ||
| int | L, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | V, | ||
| int | LDV, | ||
| float * | W, | ||
| int | LDW | ||
| ) |
ZPAMM performs one of the matrix-matrix operations
LEFT RIGHT
OP PlasmaW : W = A1 + op(V) * A2 or W = A1 + A2 * op(V) OP PlasmaA2 : A2 = A2 - op(V) * W or A2 = A2 - W * op(V)
where op( V ) is one of
op( V ) = V or op( V ) = V**T or op( V ) = V**T,
A1, A2 and W are general matrices, and V is:
l = k: rectangle + triangle l < k: rectangle + trapezoid l = 0: rectangle
Size of V, both rowwise and columnwise, is:
left N M x K T K x M right N K x N
LEFT (columnwise and rowwise):
| K | | M |
_ __________ _ _______________ _
| | | | | \
V: | | | V': |_____________|___\ K | | | M-L | | M | | | |__________________| _ |____| | _ \ | | | M - L | L | \ | | L _ \|____| _
RIGHT (columnwise and rowwise):
| K | | N |
_______________ _ _ __________ _
| | \ | | |
V': |_____________|___\ N V: | | | | | | | | K-L |__________________| _ K | | | |____| | _ | K - L | L | \ | | \ | | L _ \|____| _
| [in] | OP | OP specifies which operation to perform:
@arg PlasmaW : W = A1 + op(V) * A2 or W = A1 + A2 * op(V)
@arg PlasmaA2 : A2 = A2 - op(V) * W or A2 = A2 - W * op(V)
|
| [in] | SIDE | SIDE specifies whether op( V ) multiplies A2
or W from the left or right as follows:
@arg PlasmaLeft : multiply op( V ) from the left
OP PlasmaW : W = A1 + op(V) * A2
OP PlasmaA2 : A2 = A2 - op(V) * W
@arg PlasmaRight : multiply op( V ) from the right
OP PlasmaW : W = A1 + A2 * op(V)
OP PlasmaA2 : A2 = A2 - W * op(V)
|
| [in] | STOREV | Indicates how the vectors which define the elementary
reflectors are stored in V:
@arg PlasmaColumnwise
@arg PlasmaRowwise
|
| [in] | M | The number of rows of the A1, A2 and W If SIDE is PlasmaLeft, the number of rows of op( V ) |
| [in] | N | The number of columns of the A1, A2 and W If SIDE is PlasmaRight, the number of columns of op( V ) |
| [in] | K | If SIDE is PlasmaLeft, the number of columns of op( V ) If SIDE is PlasmaRight, the number of rows of op( V ) |
| [in] | L | The size of the triangular part of V |
| [in] | A1 | On entry, the M-by-N tile A1. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M). |
| [in,out] | A2 | On entry, the M-by-N tile A2. On exit, if OP is PlasmaA2 A2 is overwritten |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M). |
| [in] | V | The matrix V as described above. If SIDE is PlasmaLeft : op( V ) is M-by-K If SIDE is PlasmaRight: op( V ) is K-by-N |
| [in] | LDV | The leading dimension of the array V. |
| [in,out] | W | On entry, the M-by-N matrix W. On exit, W is overwritten either if OP is PlasmaA2 or PlasmaW. If OP is PlasmaA2, W is an input and is used as a workspace. |
| [in] | LDW | The leading dimension of array WORK. |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 174 of file core_spamm.c.
References CblasLower, CblasUpper, coreblas_error, L, PLASMA_SUCCESS, PlasmaA2, PlasmaColumnwise, PlasmaLeft, PlasmaNoTrans, PlasmaRight, PlasmaRowwise, PlasmaTrans, PlasmaW, trans, and uplo.
| void CORE_spamm_quark | ( | Quark * | quark | ) |
Definition at line 600 of file core_spamm.c.
References CORE_spamm(), L, quark_unpack_args_15, side, storev, V, and W.


| int CORE_sparfb | ( | int | side, |
| int | trans, | ||
| int | direct, | ||
| int | storev, | ||
| int | M1, | ||
| int | N1, | ||
| int | M2, | ||
| int | N2, | ||
| int | K, | ||
| int | L, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | V, | ||
| int | LDV, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | WORK, | ||
| int | LDWORK | ||
| ) |
CORE_sparfb applies a complex upper triangular block reflector H or its transpose H' to a complex rectangular matrix formed by coupling two tiles A1 and A2. Matrix V is:
COLUMNWISE ROWWISE | K | | N2-L | L | __ _____________ __ __ _________________ __ | | | | | \ | | | | | \ L
M2-L | | | K |_______________|_____\ __ | | | M2 | | __ |____| | | | K-L \ | | __ |______________________| __ L \ | | __ \|______| __ | N2 |
| L | K-L |
| [in] | side |
|
| [in] | trans |
|
| [in] | direct | Indicates how H is formed from a product of elementary reflectors
|
| [in] | storev | Indicates how the vectors which define the elementary reflectors are stored:
|
| [in] | M1 | The number of columns of the tile A1. M1 >= 0. |
| [in] | N1 | The number of rows of the tile A1. N1 >= 0. |
| [in] | M2 | The number of columns of the tile A2. M2 >= 0. |
| [in] | N2 | The number of rows of the tile A2. N2 >= 0. |
| [in] | K | The order of the matrix T (= the number of elementary reflectors whose product defines the block reflector). |
| [in] | L | The size of the triangular part of V |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,N1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,N2). |
| [in] | V | (LDV,K) if STOREV = 'C' (LDV,M2) if STOREV = 'R' and SIDE = 'L' (LDV,N2) if STOREV = 'R' and SIDE = 'R' Matrix V. |
| [in] | LDV | The leading dimension of the array V. If STOREV = 'C' and SIDE = 'L', LDV >= max(1,M2); if STOREV = 'C' and SIDE = 'R', LDV >= max(1,N2); if STOREV = 'R', LDV >= K. |
| [out] | T | The triangular K-by-K matrix T in the representation of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= K. |
| [in,out] | WORK | |
| [in] | LDWORK | The dimension of the array WORK. |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 131 of file core_sparfb.c.
References cblas_saxpy(), cblas_strmm(), CblasColMajor, CblasLeft, CblasNonUnit, CblasRight, CblasUpper, CORE_spamm(), coreblas_error, PLASMA_ERR_NOT_SUPPORTED, PLASMA_SUCCESS, PlasmaA2, PlasmaBackward, PlasmaColumnwise, PlasmaForward, PlasmaLeft, PlasmaNoTrans, PlasmaRight, PlasmaRowwise, PlasmaTrans, and PlasmaW.
| int CORE_spemv | ( | int | trans, |
| int | storev, | ||
| int | M, | ||
| int | N, | ||
| int | L, | ||
| float | ALPHA, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | X, | ||
| int | INCX, | ||
| float | BETA, | ||
| float * | Y, | ||
| int | INCY, | ||
| float * | WORK | ||
| ) |
SPEMV performs one of the matrix-vector operations
y = alpha*op( A )*x + beta*y
where op( A ) is one of
op( A ) = A or op( A ) = A**T or op( A ) = A**T,
alpha and beta are scalars, x and y are vectors and A is a pentagonal matrix (see further details).
| [in] | storev | @arg PlasmaColumnwise : array A stored columwise
@arg PlasmaRowwise : array A stored rowwise
|
| [in] | trans | @arg PlasmaNoTrans : y := alpha*A*x + beta*y.
@arg PlasmaTrans : y := alpha*A**T*x + beta*y.
@arg PlasmaTrans : y := alpha*A**T*x + beta*y.
|
| [in] | M | Number of rows of the matrix A. M must be at least zero. |
| [in] | N | Number of columns of the matrix A. N must be at least zero. |
| [in] | L | Order of triangle within the matrix A (L specifies the shape of the matrix A; see further details). |
| [in] | ALPHA | Scalar alpha. |
| [in] | A | Array of size LDA-by-N. On entry, the leading M by N part of the array A must contain the matrix of coefficients. |
| [in] | LDA | Leading dimension of array A. |
| [in] | X | On entry, the incremented array X must contain the vector x. |
| [in] | INCX | Increment for the elements of X. INCX must not be zero. |
| [in] | BETA | Scalar beta. |
| [in,out] | Y | On entry, the incremented array Y must contain the vector y. |
| [out] | INCY | Increment for the elements of Y. INCY must not be zero. |
| [in] | WORK | Workspace array of size at least L. |
| N |
_ ___________ _
| |
A: | | M-L | | | | M _ |..... | \ : | L \ : | _ \:_____| _
| L | N-L |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 118 of file core_spemv.c.
References cblas_saxpy(), cblas_scopy(), cblas_sgemv(), cblas_sscal(), cblas_strmv(), CblasColMajor, coreblas_error, L, max, min, PLASMA_SUCCESS, PlasmaColumnwise, PlasmaLower, PlasmaNonUnit, PlasmaNoTrans, PlasmaRowwise, PlasmaTrans, and PlasmaUpper.

| void CORE_splgsy | ( | float | bump, |
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | bigM, | ||
| int | m0, | ||
| int | n0, | ||
| unsigned long long int | seed | ||
| ) |
Definition at line 64 of file core_splgsy.c.
References A, NBELEM, Rnd64_A, Rnd64_C, and RndF_Mul.
| void CORE_splgsy_quark | ( | Quark * | quark | ) |
Definition at line 172 of file core_splgsy.c.
References A, CORE_splgsy(), and quark_unpack_args_9.


| void CORE_splrnt | ( | int | m, |
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | bigM, | ||
| int | m0, | ||
| int | n0, | ||
| unsigned long long int | seed | ||
| ) |
Definition at line 64 of file core_splrnt.c.
References A, NBELEM, Rnd64_A, Rnd64_C, and RndF_Mul.
| void CORE_splrnt_quark | ( | Quark * | quark | ) |
Definition at line 116 of file core_splrnt.c.
References A, CORE_splrnt(), and quark_unpack_args_8.


| void CORE_spotrf | ( | int | uplo, |
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| int * | INFO | ||
| ) |
Definition at line 29 of file core_spotrf.c.
References lapack_const.
| void CORE_spotrf_quark | ( | Quark * | quark | ) |
Definition at line 65 of file core_spotrf.c.
References A, lapack_const, plasma_sequence_flush(), PLASMA_SUCCESS, quark_unpack_args_7, plasma_sequence_t::status, and uplo.


| void CORE_sshift | ( | int | s, |
| int | m, | ||
| int | n, | ||
| int | L, | ||
| float * | A | ||
| ) |
CORE_sshift Shift a cycle of block. Same as core_sshiftw but you don't need to provide the workspace. As a matter of fact, the cycle cannot be split anymore to keep data coherency.
| [in] | s | Start value in the cycle |
| [in] | m | Number of lines of tile A |
| [in] | n | Number of columns of tile A |
| [in] | L | Length of each block of data to move |
| [in,out] | A | Matrix of size m-by-n with each element of size L. On exit, A = A', where A' contains the permutations |
Definition at line 175 of file core_sshift.c.
References CORE_sshiftw(), and W.

| void CORE_sshift_quark | ( | Quark * | quark | ) |
Definition at line 208 of file core_sshift.c.
References A, CORE_sshiftw(), L, quark_unpack_args_6, and W.


| void CORE_sshiftw | ( | int | s, |
| int | cl, | ||
| int | m, | ||
| int | n, | ||
| int | L, | ||
| float * | A, | ||
| float * | W | ||
| ) |
CORE_sshiftw Shift a linear chain of block using a supplied workspace by following the cycle defined by: k_(i+1) = (k_i * m) % q;
| [in] | s | Start value in the cycle |
| [in] | cl | Cycle length if cl == 0, all the permutations from the cycle are done else the cycle is split onto several threads and the number of permutation to do has to be specified to not get overlap |
| [in] | m | Number of lines of tile A |
| [in] | n | Number of columns of tile A |
| [in] | L | Length of each block of data to move |
| [in,out] | A | Matrix of size m-by-n with each element of size L. On exit, A = A', where A' contains the permutations |
| [in] | W | Array of size L. On entry, must contain: W(:) = A(s*L:s*L+L-1) |
Definition at line 66 of file core_sshift.c.
References L.
| void CORE_sshiftw_quark | ( | Quark * | quark | ) |
Definition at line 130 of file core_sshift.c.
References A, CORE_sshiftw(), L, quark_unpack_args_7, and W.


| int CORE_sssssm | ( | int | M1, |
| int | N1, | ||
| int | M2, | ||
| int | N2, | ||
| int | K, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | L1, | ||
| int | LDL1, | ||
| float * | L2, | ||
| int | LDL2, | ||
| int * | IPIV | ||
| ) |
CORE_ststrf computes an LU factorization of a complex matrix formed by an upper triangular M1-by-N1 tile U on top of a M2-by-N2 tile A (N1 == N2) using partial pivoting with row interchanges.
This is the right-looking Level 2.5 BLAS version of the algorithm.
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. |
| [in] | K | The number of columns of the tiles L1 and L2. K >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of L. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of L. |
| [in] | LDA2 | The leading dimension of the array A2. LDA2 >= max(1,M2). |
| [in] | L1 | The IB-by-K lower triangular tile as returned by CORE_ststrf. |
| [in] | LDL1 | The leading dimension of the array L1. LDL1 >= max(1,IB). |
| [in] | L2 | The M2-by-N2 tile as returned by CORE_ststrf. |
| [in] | LDL2 | The leading dimension of the array L2. LDL2 >= max(1,M2). |
| [in] | IPIV | as returned by CORE_ststrf. |
| PLASMA_SUCCESS | successful exit |
| <0 | if INFO = -k, the k-th argument had an illegal value |
Definition at line 90 of file core_sssssm.c.
References cblas_sgemm(), cblas_sswap(), cblas_strsm(), CblasColMajor, CblasLeft, CblasLower, CblasNoTrans, CblasUnit, coreblas_error, max, min, and PLASMA_SUCCESS.
| void CORE_sssssm_quark | ( | Quark * | quark | ) |
Definition at line 219 of file core_sssssm.c.
References CORE_sssssm(), IPIV, and quark_unpack_args_15.

| void CORE_sswpab | ( | int | i, |
| int | n1, | ||
| int | n2, | ||
| float * | A, | ||
| float * | work | ||
| ) |
CORE_sswpab swaps two adjacent contiguous blocks of data.
n1 n2
+————-+——————————-+
become : n2 n1 +——————————-+————-+
| [in,out] | A | Array of size i+n1+n2. On entry, a block of size n1 followed by a block of size n2. On exit, the block of size n1 follows the block of size n2. |
| [in] | i | First block starts at A[i]. |
| [in] | n1 | Size of the first block to swap. |
| [in] | n2 | Size of the second block to swap. |
| [out] | work | Workspace array of size min(n1, n2). |
Definition at line 63 of file core_sswpab.c.

| void CORE_sswpab_quark | ( | Quark * | quark | ) |
Definition at line 107 of file core_sswpab.c.
References A, CORE_sswpab(), and quark_unpack_args_5.


| int CORE_sswptr_ontile | ( | PLASMA_desc | descA, |
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc, | ||
| float * | Akk, | ||
| int | ldak | ||
| ) |
CORE_sswptr_ontile apply the slaswp function on a matrix stored in tile layout, followed by a strsm on the first tile of the panel.
| [in,out] | A | The descriptor of the matrix A to permute. |
| [in] | i1 | The first element of IPIV for which a row interchange will be done. |
| [in] | i2 | The last element of IPIV for which a row interchange will be done. |
| [in] | ipiv | The pivot indices; Only the element in position i1 to i2 are accessed. The pivot are offset by A.i. |
| [in] | inc | The increment between successive values of IPIV. If IPIV is negative, the pivots are applied in reverse order. |
Definition at line 325 of file core_slaswp.c.
References A, BLKLDD, cblas_strsm(), CblasColMajor, CblasLeft, CblasLower, CblasNoTrans, CblasUnit, CORE_slaswp_ontile(), coreblas_error, plasma_desc_t::m, plasma_desc_t::mb, plasma_desc_t::mt, plasma_desc_t::n, plasma_desc_t::nt, and PLASMA_SUCCESS.


| void CORE_sswptr_ontile_quark | ( | Quark * | quark | ) |
Definition at line 385 of file core_slaswp.c.
References A, CORE_sswptr_ontile(), and quark_unpack_args_8.

| void CORE_ssygst_quark | ( | Quark * | quark | ) |
Definition at line 67 of file core_ssygst.c.
References A, B, itype, lapack_const, plasma_sequence_flush(), PLASMA_SUCCESS, quark_unpack_args_10, plasma_sequence_t::status, and uplo.


| void CORE_ssymm | ( | int | side, |
| int | uplo, | ||
| int | M, | ||
| int | N, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB, | ||
| float | beta, | ||
| float * | C, | ||
| int | LDC | ||
| ) |
Definition at line 28 of file core_ssymm.c.
References cblas_ssymm(), and CblasColMajor.


| void CORE_ssymm_quark | ( | Quark * | quark | ) |
Definition at line 77 of file core_ssymm.c.
References A, B, C, cblas_ssymm(), CblasColMajor, quark_unpack_args_12, side, and uplo.


| void CORE_ssyr2k | ( | int | uplo, |
| int | trans, | ||
| int | N, | ||
| int | K, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB, | ||
| float | beta, | ||
| float * | C, | ||
| int | LDC | ||
| ) |
Definition at line 28 of file core_ssyr2k.c.
References cblas_ssyr2k(), and CblasColMajor.


| void CORE_ssyr2k_quark | ( | Quark * | quark | ) |
Definition at line 76 of file core_ssyr2k.c.
References A, B, C, CORE_ssyr2k(), quark_unpack_args_12, trans, and uplo.


| void CORE_ssyrfb_quark | ( | Quark * | quark | ) |
Definition at line 215 of file core_ssyrfb.c.
References A, C, CORE_ssyrfb(), quark_unpack_args_13, T, and uplo.

| void CORE_ssyrk | ( | int | uplo, |
| int | trans, | ||
| int | N, | ||
| int | K, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA, | ||
| float | beta, | ||
| float * | C, | ||
| int | LDC | ||
| ) |
Definition at line 28 of file core_ssyrk.c.
References cblas_ssyrk(), and CblasColMajor.

| void CORE_ssyrk_quark | ( | Quark * | quark | ) |
Definition at line 72 of file core_ssyrk.c.
References A, C, cblas_ssyrk(), CblasColMajor, quark_unpack_args_10, trans, and uplo.

| void CORE_strdalg | ( | PLASMA_enum | uplo, |
| int | N, | ||
| int | NB, | ||
| PLASMA_desc * | pA, | ||
| float * | V, | ||
| float * | TAU, | ||
| int | i, | ||
| int | j, | ||
| int | m, | ||
| int | grsiz | ||
| ) |
CORE_strdalg is a part of the tridiagonal reduction algorithm (bulgechasing) It correspond to a local driver of the kernels that should be executed on a single core.
| [in] | uplo |
|
| [in] | N | The order of the matrix A. N >= 0. |
| [in] | NB | The size of the Bandwidth of the matrix A, which correspond to the tile size. NB >= 0. |
| [in] | pA | A pointer to the descriptor of the matrix A. |
| [out] | V | float array, dimension (N). The scalar elementary reflectors are written in this array. So it is used as a workspace for V at each step of the bulge chasing algorithm. |
| [out] | TAU | float array, dimension (N). The scalar factors of the elementary reflectors are written in thisarray. So it is used as a workspace for TAU at each step of the bulge chasing algorithm. |
| [in] | i | Integer that refer to the current sweep. (outer loop). |
| [in] | j | Integer that refer to the sweep to chase.(inner loop). |
| [in] | m | Integer that refer to a sweep step, to ensure order dependencies. |
| [in] | grsiz | Integer that refer to the size of a group. group mean the number of kernel that should be executed sequentially on the same core. group size is a trade-off between locality (cache reuse) and parallelism. a small group size increase parallelism while a large group size increase cache reuse. |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 82 of file core_strdalg.c.
References A, CORE_shbelr(), CORE_shblrx(), CORE_shbrce(), plasma_desc_t::dtyp, min, and plasma_element_size().

| void CORE_strdalg_quark | ( | Quark * | quark | ) |
Definition at line 160 of file core_strdalg.c.
References CORE_strdalg(), quark_unpack_args_10, TAU, uplo, and V.

| void CORE_strmm | ( | int | side, |
| int | uplo, | ||
| int | transA, | ||
| int | diag, | ||
| int | M, | ||
| int | N, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB | ||
| ) |
Definition at line 28 of file core_strmm.c.
References cblas_strmm(), and CblasColMajor.

| void CORE_strmm_p2_quark | ( | Quark * | quark | ) |
Definition at line 132 of file core_strmm.c.
References A, B, cblas_strmm(), CblasColMajor, diag, quark_unpack_args_11, side, and uplo.


| void CORE_strmm_quark | ( | Quark * | quark | ) |
Definition at line 76 of file core_strmm.c.
References A, B, cblas_strmm(), CblasColMajor, diag, quark_unpack_args_11, side, and uplo.


| void CORE_strsm | ( | int | side, |
| int | uplo, | ||
| int | transA, | ||
| int | diag, | ||
| int | M, | ||
| int | N, | ||
| float | alpha, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB | ||
| ) |
Definition at line 28 of file core_strsm.c.
References cblas_strsm(), and CblasColMajor.

| void CORE_strsm_quark | ( | Quark * | quark | ) |
Definition at line 75 of file core_strsm.c.
References A, B, cblas_strsm(), CblasColMajor, diag, quark_unpack_args_11, side, and uplo.

| void CORE_strtri | ( | int | uplo, |
| int | diag, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| int * | info | ||
| ) |
Definition at line 29 of file core_strtri.c.
References lapack_const.
| void CORE_strtri_quark | ( | Quark * | quark | ) |
Definition at line 67 of file core_strtri.c.
References A, diag, lapack_const, plasma_sequence_flush(), PLASMA_SUCCESS, quark_unpack_args_8, plasma_sequence_t::status, and uplo.


| int CORE_stslqt | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | TAU, | ||
| float * | WORK | ||
| ) |
CORE_stslqt computes a LQ factorization of a rectangular matrix formed by coupling side-by-side a complex M-by-M lower triangular tile A1 and a complex M-by-N tile A2:
| A1 A2 | = L * Q
The tile Q is represented as a product of elementary reflectors
Q = H(k)' . . . H(2)' H(1)', where k = min(M,N).
Each H(i) has the form
H(i) = I - tau * v * v'
where tau is a complex scalar, and v is a complex vector with v(1:i-1) = 0 and v(i) = 1; g(v(i+1:n)) is stored on exit in A2(i,1:n), and tau in TAU(i).
| [in] | M | The number of rows of the tile A1 and A2. M >= 0. The number of columns of the tile A1. |
| [in] | N | The number of columns of the tile A2. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M-by-M tile A1. On exit, the elements on and below the diagonal of the array contain the M-by-M lower trapezoidal tile L; the elements above the diagonal are not referenced. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M). |
| [in,out] | A2 | On entry, the M-by-N tile A2. On exit, all the elements with the array TAU, represent the unitary tile Q as a product of elementary reflectors (see Further Details). |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M). |
| [out] | T | The IB-by-N triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | TAU | The scalar factors of the elementary reflectors (see Further Details). |
| [out] | WORK |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 107 of file core_stslqt.c.
References cblas_saxpy(), cblas_scopy(), cblas_sgemv(), cblas_sger(), cblas_strmv(), CblasColMajor, CORE_stsmlq(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaNonUnit, PlasmaNoTrans, PlasmaRight, PlasmaTrans, and PlasmaUpper.
| void CORE_stslqt_quark | ( | Quark * | quark | ) |
Definition at line 247 of file core_stslqt.c.
References CORE_stslqt(), quark_unpack_args_11, T, and TAU.

| int CORE_stsmlq | ( | int | side, |
| int | trans, | ||
| int | M1, | ||
| int | N1, | ||
| int | M2, | ||
| int | N2, | ||
| int | K, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | V, | ||
| int | LDV, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | WORK, | ||
| int | LDWORK | ||
| ) |
CORE_stsmlq overwrites the general complex M1-by-N1 tile A1 and M2-by-N2 tile A2 with
SIDE = 'L' SIDE = 'R'
TRANS = 'N': Q * | A1 | | A1 A2 | * Q | A2 |
TRANS = 'C': Q**T * | A1 | | A1 A2 | * Q**T | A2 |
where Q is a complex unitary matrix defined as the product of k elementary reflectors
Q = H(k)' . . . H(2)' H(1)'
as returned by CORE_STSLQT.
| [in] | side |
|
| [in] | trans |
|
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. M2 = M1 if side == PlasmaRight. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. N2 = N1 if side == PlasmaLeft. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STSLQT in the first k rows of its array argument V. |
| [in] | LDV | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-M1 if side == PlasmaLeft LDWORK-by-IB if side == PlasmaRight |
| [in] | LDWORK | The leading dimension of the array WORK. LDWORK >= max(1,IB) if side == PlasmaLeft LDWORK >= max(1,N1) if side == PlasmaRight |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 124 of file core_stsmlq.c.
References CORE_sparfb(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaForward, PlasmaLeft, PlasmaNoTrans, PlasmaRight, PlasmaRowwise, and PlasmaTrans.
| int CORE_stsmlq_corner | ( | int | m1, |
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | m3, | ||
| int | n3, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | A3, | ||
| int | lda3, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt, | ||
| float * | WORK, | ||
| int | ldwork | ||
| ) |
CORE_stsmlq_corner: see CORE_stsmlq
This kernel applies left and right transformations as depicted below: |I -VTV'| * | A1 A2 | * |I - VT'V'| | A2' A3 | where A1 and A3 are symmetric matrices. Only the lower part is referenced. This is an adhoc implementation, can be further optimized...
| [in] | side |
|
| [in] | trans |
|
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. M2 = M1 if side == PlasmaRight. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. N2 = N1 if side == PlasmaLeft. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STSLQT in the first k rows of its array argument V. |
| [in] | LDV | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-M1 if side == PlasmaLeft LDWORK-by-IB if side == PlasmaRight |
| [in] | LDWORK | The leading dimension of the array WORK. LDWORK >= max(1,IB) if side == PlasmaLeft LDWORK >= max(1,N1) if side == PlasmaRight |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 125 of file core_stsmlq_corner.c.
References CORE_stsmlq(), coreblas_error, PLASMA_SUCCESS, PlasmaLeft, PlasmaNoTrans, PlasmaRight, PlasmaTrans, side, and trans.

| void CORE_stsmlq_corner_quark | ( | Quark * | quark | ) |
This kernel applies right and left transformations as depicted below: |I -VTV'| * | A1 A2| * |I - VT'V'| | A2' A3 | where A1 and A3 are symmetric matrices. Only the upper part is referenced. This is an adhoc implementation, can be further optimized...
Definition at line 266 of file core_stsmlq_corner.c.
References CORE_stsmlq_corner(), quark_unpack_args_21, T, and V.


| void CORE_stsmlq_quark | ( | Quark * | quark | ) |
Definition at line 303 of file core_stsmlq.c.
References CORE_stsmlq(), quark_unpack_args_18, side, T, trans, and V.
| int CORE_stsmlq_sytra1 | ( | int | side, |
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt, | ||
| float * | WORK, | ||
| int | ldwork | ||
| ) |
CORE_stsmlq_sytra1: see CORE_stsmlq
This kernel applies a Right transformation on | A1' A2 | and does not handle the transpose of A1. Needs therefore to make the explicit transpose of A1 before and after the application of the block of reflectors Can be further optimized by changing accordingly the underneath kernel ztsrfb!
| [in] | side |
|
| [in] | trans |
|
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. M2 = M1 if side == PlasmaRight. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. N2 = N1 if side == PlasmaLeft. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STSLQT in the first k rows of its array argument V. |
| [in] | LDV | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-M1 if side == PlasmaLeft LDWORK-by-IB if side == PlasmaRight |
| [in] | LDWORK | The leading dimension of the array WORK. LDWORK >= max(1,IB) if side == PlasmaLeft LDWORK >= max(1,N1) if side == PlasmaRight |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 125 of file core_stsmlq_sytra1.c.
References CORE_stsmlq(), coreblas_error, and PLASMA_SUCCESS.

| void CORE_stsmlq_sytra1_quark | ( | Quark * | quark | ) |
This kernel applies a Right transformation on | A1' A2 | and does not handle the transpose of A1. Needs therefore to make the explicit transpose of A1 before and after the application of the block of reflectors Can be further optimized by changing accordingly the underneath kernel ztsrfb!
Definition at line 218 of file core_stsmlq_sytra1.c.
References CORE_stsmlq_sytra1(), quark_unpack_args_18, side, T, trans, and V.


| int CORE_stsmqr | ( | int | side, |
| int | trans, | ||
| int | M1, | ||
| int | N1, | ||
| int | M2, | ||
| int | N2, | ||
| int | K, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | V, | ||
| int | LDV, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | WORK, | ||
| int | LDWORK | ||
| ) |
CORE_stsmqr overwrites the general complex M1-by-N1 tile A1 and M2-by-N2 tile A2 with
SIDE = 'L' SIDE = 'R'
TRANS = 'N': Q * | A1 | | A1 A2 | * Q | A2 |
TRANS = 'C': Q**T * | A1 | | A1 A2 | * Q**T | A2 |
where Q is a complex unitary matrix defined as the product of k elementary reflectors
Q = H(1) H(2) . . . H(k)
as returned by CORE_STSQRT.
| [in] | side |
|
| [in] | trans |
|
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. M2 = M1 if side == PlasmaRight. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. N2 = N1 if side == PlasmaLeft. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STSQRT in the first k columns of its array argument V. |
| [in] | LDV | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-N1 if side == PlasmaLeft LDWORK-by-IB if side == PlasmaRight |
| [in] | LDWORK | The leading dimension of the array WORK. LDWORK >= max(1,IB) if side == PlasmaLeft LDWORK >= max(1,M1) if side == PlasmaRight |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 124 of file core_stsmqr.c.
References CORE_sparfb(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaColumnwise, PlasmaForward, PlasmaLeft, PlasmaNoTrans, PlasmaRight, and PlasmaTrans.
| int CORE_stsmqr_corner | ( | int | m1, |
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | m3, | ||
| int | n3, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | A3, | ||
| int | lda3, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt, | ||
| float * | WORK, | ||
| int | ldwork | ||
| ) |
CORE_stsmqr_corner: see CORE_stsmqr
This kernel applies left and right transformations as depicted below: |I -VT'V'| * | A1 A2'| * |I - VTV'| | A2 A3 | where A1 and A3 are symmetric matrices. Only the lower part is referenced. This is an adhoc implementation, can be further optimized...
| [in] | side |
|
| [in] | trans |
|
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. M2 = M1 if side == PlasmaRight. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. N2 = N1 if side == PlasmaLeft. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STSQRT in the first k columns of its array argument V. |
| [in] | LDV | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-N1 if side == PlasmaLeft LDWORK-by-IB if side == PlasmaRight |
| [in] | LDWORK | The leading dimension of the array WORK. LDWORK >= max(1,IB) if side == PlasmaLeft LDWORK >= max(1,M1) if side == PlasmaRight |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 125 of file core_stsmqr_corner.c.
References CORE_stsmqr(), coreblas_error, PLASMA_SUCCESS, PlasmaLeft, PlasmaNoTrans, PlasmaRight, PlasmaTrans, side, and trans.

| void CORE_stsmqr_corner_quark | ( | Quark * | quark | ) |
Definition at line 254 of file core_stsmqr_corner.c.
References CORE_stsmqr_corner(), quark_unpack_args_21, T, and V.


| void CORE_stsmqr_quark | ( | Quark * | quark | ) |
Definition at line 298 of file core_stsmqr.c.
References CORE_stsmqr(), quark_unpack_args_18, side, T, trans, and V.
| int CORE_stsmqr_sytra1 | ( | int | side, |
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt, | ||
| float * | WORK, | ||
| int | ldwork | ||
| ) |
CORE_stsmqr_sytra1: see CORE_stsmqr
This kernel applies a left transformation on | A1'| | A2 |
Needs therefore to make the explicit transpose of A1 before and after the application of the block of reflectors Can be further optimized by changing accordingly the underneath kernel ztsrfb!
| [in] | side |
|
| [in] | trans |
|
| [in] | m1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | n1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | m2 | The number of rows of the tile A2. M2 >= 0. M2 = M1 if side == PlasmaRight. |
| [in] | n2 | The number of columns of the tile A2. N2 >= 0. N2 = N1 if side == PlasmaLeft. |
| [in] | k | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | ib | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | lda1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | lda2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STSQRT in the first k columns of its array argument V. |
| [in] | ldv | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | ldt | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-N1 if side == PlasmaLeft LDWORK-by-IB if side == PlasmaRight |
| [in] | ldwork | The leading dimension of the array WORK. LDWORK >= max(1,IB) if side == PlasmaLeft LDWORK >= max(1,M1) if side == PlasmaRight |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 127 of file core_stsmqr_sytra1.c.
References CORE_stsmqr(), coreblas_error, and PLASMA_SUCCESS.

| void CORE_stsmqr_sytra1_quark | ( | Quark * | quark | ) |
Definition at line 212 of file core_stsmqr_sytra1.c.
References CORE_stsmqr_sytra1(), quark_unpack_args_18, side, T, trans, and V.


| int CORE_stsqrt | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | TAU, | ||
| float * | WORK | ||
| ) |
CORE_stsqrt computes a QR factorization of a rectangular matrix formed by coupling a complex N-by-N upper triangular tile A1 on top of a complex M-by-N tile A2:
| A1 | = Q * R | A2 |
| [in] | M | The number of columns of the tile A2. M >= 0. |
| [in] | N | The number of rows of the tile A1. The number of columns of the tiles A1 and A2. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the N-by-N tile A1. On exit, the elements on and above the diagonal of the array contain the N-by-N upper trapezoidal tile R; the elements below the diagonal are not referenced. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,N). |
| [in,out] | A2 | On entry, the M-by-N tile A2. On exit, all the elements with the array TAU, represent the unitary tile Q as a product of elementary reflectors (see Further Details). |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M). |
| [out] | T | The IB-by-N triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | TAU | The scalar factors of the elementary reflectors (see Further Details). |
| [out] | WORK |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 97 of file core_stsqrt.c.
References cblas_saxpy(), cblas_scopy(), cblas_sgemv(), cblas_sger(), cblas_strmv(), CblasColMajor, CORE_stsmqr(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaLeft, PlasmaNonUnit, PlasmaNoTrans, PlasmaTrans, and PlasmaUpper.
| void CORE_stsqrt_quark | ( | Quark * | quark | ) |
Definition at line 238 of file core_stsqrt.c.
References CORE_stsqrt(), quark_unpack_args_11, T, and TAU.

| int CORE_ststrf | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| int | NB, | ||
| float * | U, | ||
| int | LDU, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | L, | ||
| int | LDL, | ||
| int * | IPIV, | ||
| float * | WORK, | ||
| int | LDWORK, | ||
| int * | INFO | ||
| ) |
CORE_ststrf computes an LU factorization of a complex matrix formed by an upper triangular NB-by-N tile U on top of a M-by-N tile A using partial pivoting with row interchanges.
This is the right-looking Level 2.5 BLAS version of the algorithm.
| [in] | M | The number of rows of the tile A. M >= 0. |
| [in] | N | The number of columns of the tile A. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in] | NB | |
| [in,out] | U | On entry, the NB-by-N upper triangular tile. On exit, the new factor U from the factorization |
| [in] | LDU | The leading dimension of the array U. LDU >= max(1,NB). |
| [in,out] | A | On entry, the M-by-N tile to be factored. On exit, the factor L from the factorization |
| [in] | LDA | The leading dimension of the array A. LDA >= max(1,M). |
| [in,out] | L | On entry, the IB-by-N lower triangular tile. On exit, the interchanged rows form the tile A in case of pivoting. |
| [in] | LDL | The leading dimension of the array L. LDL >= max(1,IB). |
| [out] | IPIV | The pivot indices; for 1 <= i <= min(M,N), row i of the tile U was interchanged with row IPIV(i) of the tile A. |
| [in,out] | WORK | |
| [in] | LDWORK | The dimension of the array WORK. |
| [out] | INFO |
| PLASMA_SUCCESS | successful exit |
| <0 | if INFO = -k, the k-th argument had an illegal value |
| >0 | if INFO = k, U(k,k) is exactly zero. The factorization has been completed, but the factor U is exactly singular, and division by zero will occur if it is used to solve a system of equations. |
Definition at line 99 of file core_ststrf.c.
References cblas_isamax(), cblas_scopy(), cblas_sger(), cblas_sscal(), cblas_sswap(), CblasColMajor, CORE_sssssm(), coreblas_error, max, min, and PLASMA_SUCCESS.
| void CORE_ststrf_quark | ( | Quark * | quark | ) |
Definition at line 258 of file core_ststrf.c.
References A, CORE_ststrf(), IPIV, L, plasma_sequence_flush(), PLASMA_SUCCESS, and quark_unpack_args_17.
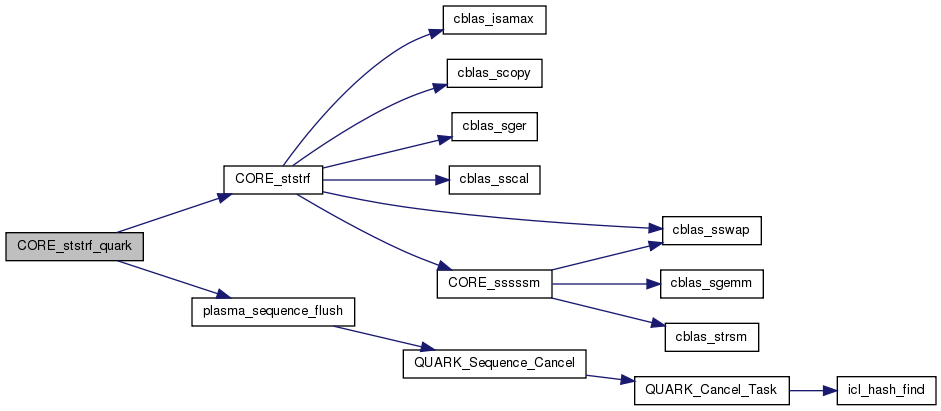

| int CORE_sttlqt | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | TAU, | ||
| float * | WORK | ||
| ) |
CORE_sttlqt computes a LQ factorization of a rectangular matrix formed by coupling side-by-side a complex M-by-M lower triangular tile A1 and a complex M-by-N lower triangular tile A2:
| A1 A2 | = L * Q
The tile Q is represented as a product of elementary reflectors
Q = H(k)' . . . H(2)' H(1)', where k = min(M,N).
Each H(i) has the form
H(i) = I - tau * v * v'
where tau is a complex scalar, and v is a complex vector with v(1:i-1) = 0 and v(i) = 1; g(v(i+1:n)) is stored on exit in A2(i,1:n), and tau in TAU(i).
| [in] | M | The number of rows of the tile A1 and A2. M >= 0. The number of columns of the tile A1. |
| [in] | N | The number of columns of the tile A2. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M-by-M tile A1. On exit, the elements on and below the diagonal of the array contain the M-by-M lower trapezoidal tile L; the elements above the diagonal are not referenced. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,N). |
| [in,out] | A2 | On entry, the M-by-N lower triangular tile A2. On exit, the elements on and below the diagonal of the array with the array TAU, represent the unitary tile Q as a product of elementary reflectors (see Further Details). |
| [in] | LDA2 | The leading dimension of the array A2. LDA2 >= max(1,M). |
| [out] | T | The IB-by-N triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | TAU | The scalar factors of the elementary reflectors (see Further Details). |
| [in,out] | WORK |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 100 of file core_sttlqt.c.
References cblas_saxpy(), cblas_scopy(), cblas_sgemv(), cblas_sger(), cblas_strmv(), CblasColMajor, CORE_slaset(), CORE_sparfb(), CORE_spemv(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaForward, PlasmaNonUnit, PlasmaNoTrans, PlasmaRight, PlasmaRowwise, PlasmaUpper, and PlasmaUpperLower.
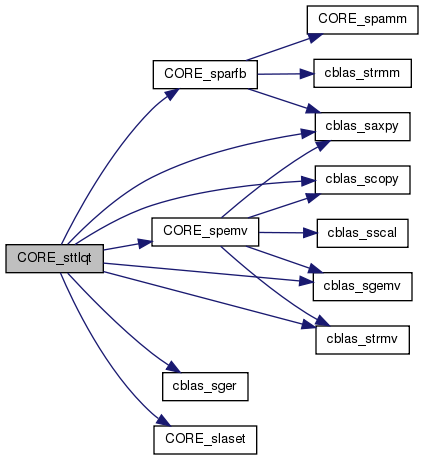

| void CORE_sttlqt_quark | ( | Quark * | quark | ) |
Definition at line 273 of file core_sttlqt.c.
References CORE_sttlqt(), quark_unpack_args_11, T, and TAU.
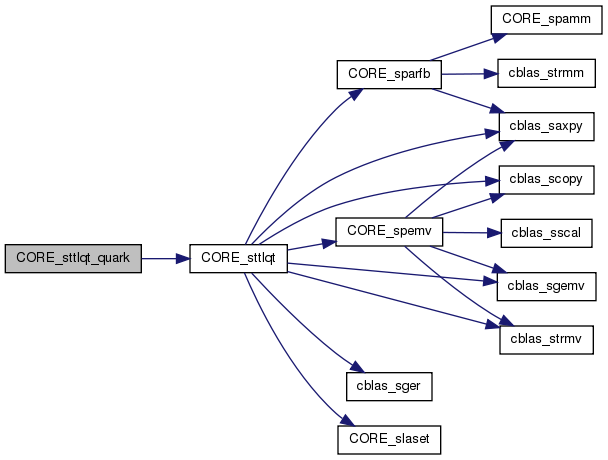

| int CORE_sttmlq | ( | int | side, |
| int | trans, | ||
| int | M1, | ||
| int | N1, | ||
| int | M2, | ||
| int | N2, | ||
| int | K, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | V, | ||
| int | LDV, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | WORK, | ||
| int | LDWORK | ||
| ) |
CORE_sttmlq overwrites the general complex M1-by-N1 tile A1 and M2-by-N2 tile A2 (N1 == N2) with
SIDE = 'L' SIDE = 'R'
TRANS = 'N': Q * | A1 | | A1 | * Q | A2 | | A2 |
TRANS = 'C': Q**T * | A1 | | A1 | * Q**T | A2 | | A2 |
where Q is a complex unitary matrix defined as the product of k elementary reflectors
Q = H(1) H(2) . . . H(k)
as returned by CORE_sttqrt.
| [in] | side |
|
| [in] | trans |
|
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STTQRT in the first k rows of its array argument V. |
| [in] | LDV | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-N1. |
| [in] | LDWORK | The dimension of the array WORK. LDWORK >= max(1,IB). |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 116 of file core_sttmlq.c.
References CORE_sparfb(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaForward, PlasmaLeft, PlasmaNoTrans, PlasmaRight, PlasmaRowwise, and PlasmaTrans.
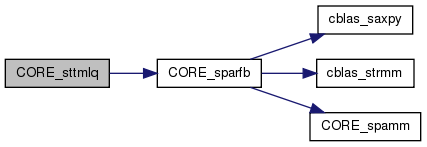
| void CORE_sttmlq_quark | ( | Quark * | quark | ) |
Definition at line 299 of file core_sttmlq.c.
References CORE_sttmlq(), quark_unpack_args_18, side, T, trans, and V.
| int CORE_sttmqr | ( | int | side, |
| int | trans, | ||
| int | M1, | ||
| int | N1, | ||
| int | M2, | ||
| int | N2, | ||
| int | K, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | V, | ||
| int | LDV, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | WORK, | ||
| int | LDWORK | ||
| ) |
CORE_sttmqr overwrites the general complex M1-by-N1 tile A1 and M2-by-N2 tile A2 (N1 == N2) with
SIDE = 'L' SIDE = 'R'
TRANS = 'N': Q * | A1 | | A1 | * Q | A2 | | A2 |
TRANS = 'C': Q**T * | A1 | | A1 | * Q**T | A2 | | A2 |
where Q is a complex unitary matrix defined as the product of k elementary reflectors
Q = H(1) H(2) . . . H(k)
as returned by CORE_sttqrt.
| [in] | side |
|
| [in] | trans |
|
| [in] | M1 | The number of rows of the tile A1. M1 >= 0. |
| [in] | N1 | The number of columns of the tile A1. N1 >= 0. |
| [in] | M2 | The number of rows of the tile A2. M2 >= 0. |
| [in] | N2 | The number of columns of the tile A2. N2 >= 0. |
| [in] | K | The number of elementary reflectors whose product defines the matrix Q. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the M1-by-N1 tile A1. On exit, A1 is overwritten by the application of Q. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,M1). |
| [in,out] | A2 | On entry, the M2-by-N2 tile A2. On exit, A2 is overwritten by the application of Q. |
| [in] | LDA2 | The leading dimension of the tile A2. LDA2 >= max(1,M2). |
| [in] | V | The i-th row must contain the vector which defines the elementary reflector H(i), for i = 1,2,...,k, as returned by CORE_STTQRT in the first k rows of its array argument V. |
| [in] | LDV | The leading dimension of the array V. LDV >= max(1,K). |
| [out] | T | The IB-by-N1 triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | WORK | Workspace array of size LDWORK-by-N1. |
| [in] | LDWORK | The dimension of the array WORK. LDWORK >= max(1,IB). |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 116 of file core_sttmqr.c.
References CORE_sparfb(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaColumnwise, PlasmaForward, PlasmaLeft, PlasmaNoTrans, PlasmaRight, and PlasmaTrans.
| void CORE_sttmqr_quark | ( | Quark * | quark | ) |
Definition at line 291 of file core_sttmqr.c.
References CORE_sttmqr(), quark_unpack_args_18, side, T, trans, and V.
| int CORE_sttqrt | ( | int | M, |
| int | N, | ||
| int | IB, | ||
| float * | A1, | ||
| int | LDA1, | ||
| float * | A2, | ||
| int | LDA2, | ||
| float * | T, | ||
| int | LDT, | ||
| float * | TAU, | ||
| float * | WORK | ||
| ) |
CORE_sttqrt computes a QR factorization of a rectangular matrix formed by coupling a complex N-by-N upper triangular tile A1 on top of a complex M-by-N upper trapezoidal tile A2:
| A1 | = Q * R | A2 |
The tile Q is represented as a product of elementary reflectors
Q = H(1) H(2) . . . H(k), where k = min(M,N).
Each H(i) has the form
H(i) = I - tau * v * v'
where tau is a complex scalar, and v is a complex vector with v(1:i-1) = 0 and v(i) = 1; v(i+1:m) is stored on exit in A2(1:m,i), and tau in TAU(i).
| [in] | M | The number of rows of the tile A2. M >= 0. |
| [in] | N | The number of columns of the tile A1 and A2. N >= 0. |
| [in] | IB | The inner-blocking size. IB >= 0. |
| [in,out] | A1 | On entry, the N-by-N tile A1. On exit, the elements on and above the diagonal of the array contain the N-by-N upper trapezoidal tile R; the elements below the diagonal are not referenced. |
| [in] | LDA1 | The leading dimension of the array A1. LDA1 >= max(1,N). |
| [in,out] | A2 | On entry, the M-by-N upper triangular tile A2. On exit, the elements on and above the diagonal of the array with the array TAU, represent the unitary tile Q as a product of elementary reflectors (see Further Details). |
| [in] | LDA2 | The leading dimension of the array A2. LDA2 >= max(1,M). |
| [out] | T | The IB-by-N triangular factor T of the block reflector. T is upper triangular by block (economic storage); The rest of the array is not referenced. |
| [in] | LDT | The leading dimension of the array T. LDT >= IB. |
| [out] | TAU | The scalar factors of the elementary reflectors (see Further Details). |
| [in,out] | WORK |
| PLASMA_SUCCESS | successful exit |
| <0 | if -i, the i-th argument had an illegal value |
Definition at line 100 of file core_sttqrt.c.
References cblas_saxpy(), cblas_scopy(), cblas_sgemv(), cblas_sger(), cblas_strmv(), CblasColMajor, CORE_slaset(), CORE_sparfb(), CORE_spemv(), coreblas_error, max, min, PLASMA_SUCCESS, PlasmaColumnwise, PlasmaForward, PlasmaLeft, PlasmaNonUnit, PlasmaNoTrans, PlasmaTrans, PlasmaUpper, and PlasmaUpperLower.

| void CORE_sttqrt_quark | ( | Quark * | quark | ) |
Definition at line 273 of file core_sttqrt.c.
References CORE_sttqrt(), quark_unpack_args_11, T, and TAU.

| void QUARK_CORE_sasum | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_enum | storev, | ||
| PLASMA_enum | uplo, | ||
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | szeA, | ||
| float * | work, | ||
| int | szeW | ||
| ) |
Definition at line 95 of file core_sasum.c.
References CORE_sasum_quark(), INOUT, INPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sasum_f1 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_enum | storev, | ||
| PLASMA_enum | uplo, | ||
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | szeA, | ||
| float * | work, | ||
| int | szeW, | ||
| float * | fake, | ||
| int | szeF | ||
| ) |
Definition at line 136 of file core_sasum.c.
References CORE_sasum_f1_quark(), DAG_CORE_ASUM, GATHERV, INOUT, INPUT, OUTPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sbrdalg | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | uplo, | ||
| int | N, | ||
| int | NB, | ||
| PLASMA_desc * | A, | ||
| float * | C, | ||
| float * | S, | ||
| int | i, | ||
| int | j, | ||
| int | m, | ||
| int | grsiz, | ||
| int | BAND, | ||
| int * | PCOL, | ||
| int * | ACOL, | ||
| int * | MCOL | ||
| ) |
Definition at line 127 of file core_sbrdalg.c.
References CORE_sbrdalg_quark(), INPUT, LOCALITY, NODEP, OUTPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_sgeadd | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb | ||
| ) |
Definition at line 43 of file core_sgeadd.c.
References CORE_sgeadd_quark(), DAG_CORE_GEADD, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_sgelqt | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 154 of file core_sgelqt.c.
References CORE_sgelqt_quark(), DAG_CORE_GELQT, INOUT, OUTPUT, QUARK_Insert_Task(), SCRATCH, and VALUE.

| void QUARK_CORE_sgemm | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | transA, | ||
| int | transB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 46 of file core_sgemm.c.
References CORE_sgemm_quark(), DAG_CORE_GEMM, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgemm2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | transA, | ||
| int | transB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 74 of file core_sgemm.c.
References CORE_sgemm_quark(), DAG_CORE_GEMM, GATHERV, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgemm_f2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | transA, | ||
| int | transB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc, | ||
| float * | fake1, | ||
| int | szefake1, | ||
| int | flag1, | ||
| float * | fake2, | ||
| int | szefake2, | ||
| int | flag2 | ||
| ) |
Definition at line 135 of file core_sgemm.c.
References CORE_sgemm_f2_quark(), DAG_CORE_GEMM, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgemm_p2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | transA, | ||
| int | transB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float ** | B, | ||
| int | ldb, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 202 of file core_sgemm.c.
References CORE_sgemm_p2_quark(), DAG_CORE_GEMM, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgemm_p2f1 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | transA, | ||
| int | transB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float ** | B, | ||
| int | ldb, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc, | ||
| float * | fake1, | ||
| int | szefake1, | ||
| int | flag1 | ||
| ) |
Definition at line 326 of file core_sgemm.c.
References CORE_sgemm_p2f1_quark(), DAG_CORE_GEMM, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgemm_p3 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | transA, | ||
| int | transB, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float | beta, | ||
| float ** | C, | ||
| int | ldc | ||
| ) |
Definition at line 264 of file core_sgemm.c.
References CORE_sgemm_p3_quark(), DAG_CORE_GEMM, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgeqrt | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 155 of file core_sgeqrt.c.
References CORE_sgeqrt_quark(), DAG_CORE_GEQRT, INOUT, OUTPUT, QUARK_Insert_Task(), SCRATCH, and VALUE.

| void QUARK_CORE_sgessm | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| int * | IPIV, | ||
| float * | L, | ||
| int | ldl, | ||
| float * | A, | ||
| int | lda | ||
| ) |
Definition at line 145 of file core_sgessm.c.
References CORE_sgessm_quark(), DAG_CORE_GESSM, INOUT, INPUT, QUARK_Insert_Task(), QUARK_REGION_L, and VALUE.
| void QUARK_CORE_sgetrf | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| int * | IPIV, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| PLASMA_bool | check_info, | ||
| int | iinfo | ||
| ) |
Definition at line 33 of file core_sgetrf.c.
References CORE_sgetrf_quark(), DAG_CORE_GETRF, INOUT, LOCALITY, OUTPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgetrf_incpiv | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| int * | IPIV, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| PLASMA_bool | check_info, | ||
| int | iinfo | ||
| ) |
Definition at line 145 of file core_sgetrf_incpiv.c.
References CORE_sgetrf_incpiv_quark(), DAG_CORE_GETRF, INOUT, OUTPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_sgetrf_reclap | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| int * | IPIV, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| PLASMA_bool | check_info, | ||
| int | iinfo, | ||
| int | nbthread | ||
| ) |
Definition at line 351 of file core_sgetrf_reclap.c.
References CORE_sgetrf_reclap_quark(), DAG_CORE_GETRF, INOUT, OUTPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgetrf_rectil | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_desc | A, | ||
| float * | Amn, | ||
| int | size, | ||
| int * | IPIV, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| PLASMA_bool | check_info, | ||
| int | iinfo, | ||
| int | nbthread | ||
| ) |
Definition at line 699 of file core_sgetrf_rectil.c.
References CORE_sgetrf_rectil_quark(), DAG_CORE_GETRF, INOUT, plasma_desc_t::n, OUTPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sgetrip | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | szeA | ||
| ) |
Definition at line 82 of file core_sgetrip.c.
References CORE_sgetrip_quark(), DAG_CORE_GETRIP, INOUT, QUARK_Insert_Task(), SCRATCH, and VALUE.

| void QUARK_CORE_sgetrip_f1 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | szeA, | ||
| float * | fake, | ||
| int | szeF, | ||
| int | paramF | ||
| ) |
Definition at line 115 of file core_sgetrip.c.
References CORE_sgetrip_f1_quark(), DAG_CORE_GETRIP, INOUT, QUARK_Insert_Task(), SCRATCH, and VALUE.

| void QUARK_CORE_sgetrip_f2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | szeA, | ||
| float * | fake1, | ||
| int | szeF1, | ||
| int | paramF1, | ||
| float * | fake2, | ||
| int | szeF2, | ||
| int | paramF2 | ||
| ) |
Definition at line 153 of file core_sgetrip.c.
References CORE_sgetrip_f2_quark(), DAG_CORE_GETRIP, INOUT, QUARK_Insert_Task(), SCRATCH, and VALUE.

| void QUARK_CORE_slacpy | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_enum | uplo, | ||
| int | m, | ||
| int | n, | ||
| int | mb, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb | ||
| ) |
Definition at line 42 of file core_slacpy.c.
References CORE_slacpy_quark(), DAG_CORE_LACPY, INPUT, OUTPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_slange | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | norm, | ||
| int | M, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| int | szeA, | ||
| int | szeW, | ||
| float * | result | ||
| ) |
Definition at line 42 of file core_slange.c.
References CORE_slange_quark(), DAG_CORE_LANGE, INPUT, max, OUTPUT, QUARK_Insert_Task(), SCRATCH, and VALUE.
| void QUARK_CORE_slange_f1 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | norm, | ||
| int | M, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| int | szeA, | ||
| int | szeW, | ||
| float * | result, | ||
| float * | fake, | ||
| int | szeF | ||
| ) |
Definition at line 87 of file core_slange.c.
References CORE_slange_f1_quark(), DAG_CORE_LANGE, GATHERV, INPUT, max, OUTPUT, QUARK_Insert_Task(), SCRATCH, and VALUE.
| void QUARK_CORE_slansy | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | norm, | ||
| int | uplo, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| int | szeA, | ||
| int | szeW, | ||
| float * | result | ||
| ) |
Definition at line 42 of file core_slansy.c.
References CORE_slansy_quark(), DAG_CORE_LANSY, INPUT, max, OUTPUT, QUARK_Insert_Task(), SCRATCH, and VALUE.
| void QUARK_CORE_slansy_f1 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | norm, | ||
| int | uplo, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| int | szeA, | ||
| int | szeW, | ||
| float * | result, | ||
| float * | fake, | ||
| int | szeF | ||
| ) |
Definition at line 87 of file core_slansy.c.
References CORE_slansy_f1_quark(), DAG_CORE_LANSY, GATHERV, INPUT, max, OUTPUT, QUARK_Insert_Task(), SCRATCH, and VALUE.

| void QUARK_CORE_slaset | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_enum | uplo, | ||
| int | n1, | ||
| int | n2, | ||
| float | alpha, | ||
| float | beta, | ||
| float * | tileA, | ||
| int | ldtilea | ||
| ) |
Definition at line 71 of file core_slaset.c.
References CORE_slaset_quark(), DAG_CORE_LASET, OUTPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_slaset2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_enum | uplo, | ||
| int | n1, | ||
| int | n2, | ||
| float | alpha, | ||
| float * | tileA, | ||
| int | ldtilea | ||
| ) |
Definition at line 82 of file core_slaset2.c.
References CORE_slaset2_quark(), OUTPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_slaswp | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc | ||
| ) |
Definition at line 37 of file core_slaswp.c.
References CORE_slaswp_quark(), DAG_CORE_LASWP, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_slaswp_f2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc, | ||
| float * | fake1, | ||
| int | szefake1, | ||
| int | flag1, | ||
| float * | fake2, | ||
| int | szefake2, | ||
| int | flag2 | ||
| ) |
Definition at line 74 of file core_slaswp.c.
References CORE_slaswp_f2_quark(), DAG_CORE_LASWP, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_slaswp_ontile | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_desc | descA, | ||
| float * | A, | ||
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc, | ||
| float * | fakepanel | ||
| ) |
Definition at line 214 of file core_slaswp.c.
References CORE_slaswp_ontile_quark(), DAG_CORE_LASWP, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_slaswp_ontile_f2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_desc | descA, | ||
| float * | A, | ||
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc, | ||
| float * | fake1, | ||
| int | szefake1, | ||
| int | flag1, | ||
| float * | fake2, | ||
| int | szefake2, | ||
| int | flag2 | ||
| ) |
Definition at line 252 of file core_slaswp.c.
References CORE_slaswp_ontile_f2_quark(), DAG_CORE_LASWP, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_slaswpc_ontile | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_desc | descA, | ||
| float * | A, | ||
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc, | ||
| float * | fakepanel | ||
| ) |
Definition at line 492 of file core_slaswp.c.
References CORE_slaswpc_ontile_quark(), DAG_CORE_LASWP, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_slauum | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | uplo, | ||
| int | n, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda | ||
| ) |
Definition at line 37 of file core_slauum.c.
References CORE_slauum_quark(), DAG_CORE_LAUUM, INOUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_sormlq | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| int | k, | ||
| float * | A, | ||
| int | lda, | ||
| float * | T, | ||
| int | ldt, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 231 of file core_sormlq.c.
References CORE_sormlq_quark(), DAG_CORE_UNMLQ, INOUT, INPUT, QUARK_Insert_Task(), QUARK_REGION_U, SCRATCH, and VALUE.
| void QUARK_CORE_sormqr | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| float * | T, | ||
| int | ldt, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 224 of file core_sormqr.c.
References CORE_sormqr_quark(), DAG_CORE_UNMQR, INOUT, INPUT, QUARK_Insert_Task(), QUARK_REGION_L, SCRATCH, and VALUE.
| void QUARK_CORE_spamm | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | op, | ||
| int | side, | ||
| int | storev, | ||
| int | m, | ||
| int | n, | ||
| int | k, | ||
| int | l, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | W, | ||
| int | ldw | ||
| ) |
Definition at line 569 of file core_spamm.c.
References CORE_spamm_quark(), INOUT, INPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_splgsy | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| float | bump, | ||
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | bigM, | ||
| int | m0, | ||
| int | n0, | ||
| unsigned long long int | seed | ||
| ) |
Definition at line 147 of file core_splgsy.c.
References CORE_splgsy_quark(), DAG_CORE_PLGSY, OUTPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_splrnt | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| float * | A, | ||
| int | lda, | ||
| int | bigM, | ||
| int | m0, | ||
| int | n0, | ||
| unsigned long long int | seed | ||
| ) |
Definition at line 92 of file core_splrnt.c.
References CORE_splrnt_quark(), DAG_CORE_PLRNT, OUTPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_spotrf | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | uplo, | ||
| int | n, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| int | iinfo | ||
| ) |
Definition at line 40 of file core_spotrf.c.
References CORE_spotrf_quark(), DAG_CORE_POTRF, INOUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_sshift | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | s, | ||
| int | m, | ||
| int | n, | ||
| int | L, | ||
| float * | A | ||
| ) |
Definition at line 187 of file core_sshift.c.
References CORE_sshift_quark(), DAG_CORE_SHIFT, GATHERV, INOUT, QUARK_Insert_Task(), SCRATCH, and VALUE.

| void QUARK_CORE_sshiftw | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | s, | ||
| int | cl, | ||
| int | m, | ||
| int | n, | ||
| int | L, | ||
| float * | A, | ||
| float * | W | ||
| ) |
Definition at line 108 of file core_sshift.c.
References CORE_sshiftw_quark(), DAG_CORE_SHIFTW, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sssssm | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | L1, | ||
| int | ldl1, | ||
| float * | L2, | ||
| int | ldl2, | ||
| int * | IPIV | ||
| ) |
Definition at line 184 of file core_sssssm.c.
References CORE_sssssm_quark(), DAG_CORE_SSSSM, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_sswpab | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | i, | ||
| int | n1, | ||
| int | n2, | ||
| float * | A, | ||
| int | szeA | ||
| ) |
Definition at line 85 of file core_sswpab.c.
References CORE_sswpab_quark(), DAG_CORE_SWPAB, INOUT, min, QUARK_Insert_Task(), SCRATCH, and VALUE.
| void QUARK_CORE_sswptr_ontile | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_desc | descA, | ||
| float * | Aij, | ||
| int | i1, | ||
| int | i2, | ||
| int * | ipiv, | ||
| int | inc, | ||
| float * | Akk, | ||
| int | ldak | ||
| ) |
Definition at line 359 of file core_slaswp.c.
References CORE_sswptr_ontile_quark(), DAG_CORE_TRSM, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_ssygst | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | itype, | ||
| int | uplo, | ||
| int | N, | ||
| float * | A, | ||
| int | LDA, | ||
| float * | B, | ||
| int | LDB, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| int | iinfo | ||
| ) |
Definition at line 39 of file core_ssygst.c.
References CORE_ssygst_quark(), INOUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_ssymm | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | uplo, | ||
| int | m, | ||
| int | n, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 46 of file core_ssymm.c.
References CORE_ssymm_quark(), DAG_CORE_SYMM, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_ssyr2k | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | uplo, | ||
| int | trans, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | LDB, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 45 of file core_ssyr2k.c.
References CORE_ssyr2k_quark(), DAG_CORE_SYR2K, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_ssyrfb | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| PLASMA_enum | uplo, | ||
| int | n, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| float * | T, | ||
| int | ldt, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
This kernel is just a workaround for now... will be deleted eventually and replaced by the one above (Piotr's Task)
Definition at line 183 of file core_ssyrfb.c.
References CORE_ssyrfb_quark(), INOUT, INPUT, PlasmaUpper, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_L, QUARK_REGION_U, SCRATCH, and VALUE.

| void QUARK_CORE_ssyrk | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | uplo, | ||
| int | trans, | ||
| int | n, | ||
| int | k, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float | beta, | ||
| float * | C, | ||
| int | ldc | ||
| ) |
Definition at line 44 of file core_ssyrk.c.
References CORE_ssyrk_quark(), DAG_CORE_SYRK, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_strdalg | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | uplo, | ||
| int | N, | ||
| int | NB, | ||
| PLASMA_desc * | A, | ||
| float * | C, | ||
| float * | S, | ||
| int | i, | ||
| int | j, | ||
| int | m, | ||
| int | grsiz, | ||
| int | BAND, | ||
| int * | PCOL, | ||
| int * | ACOL, | ||
| int * | MCOL | ||
| ) |
Definition at line 126 of file core_strdalg.c.
References CORE_strdalg_quark(), INPUT, LOCALITY, NODEP, OUTPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_strmm | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | uplo, | ||
| int | transA, | ||
| int | diag, | ||
| int | m, | ||
| int | n, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb | ||
| ) |
Definition at line 47 of file core_strmm.c.
References CORE_strmm_quark(), DAG_CORE_TRMM, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_strmm_p2 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | uplo, | ||
| int | transA, | ||
| int | diag, | ||
| int | m, | ||
| int | n, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float ** | B, | ||
| int | ldb | ||
| ) |
Definition at line 103 of file core_strmm.c.
References CORE_strmm_p2_quark(), DAG_CORE_TRMM, INOUT, INPUT, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_strsm | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | uplo, | ||
| int | transA, | ||
| int | diag, | ||
| int | m, | ||
| int | n, | ||
| int | nb, | ||
| float | alpha, | ||
| float * | A, | ||
| int | lda, | ||
| float * | B, | ||
| int | ldb | ||
| ) |
Definition at line 46 of file core_strsm.c.
References CORE_strsm_quark(), DAG_CORE_TRSM, INOUT, INPUT, LOCALITY, QUARK_Insert_Task(), and VALUE.
| void QUARK_CORE_strtri | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | uplo, | ||
| int | diag, | ||
| int | n, | ||
| int | nb, | ||
| float * | A, | ||
| int | lda, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| int | iinfo | ||
| ) |
Definition at line 40 of file core_strtri.c.
References CORE_strtri_quark(), INOUT, QUARK_Insert_Task(), and VALUE.

| void QUARK_CORE_stslqt | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 218 of file core_stslqt.c.
References CORE_stslqt_quark(), DAG_CORE_TSLQT, INOUT, LOCALITY, OUTPUT, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_L, SCRATCH, and VALUE.

| void QUARK_CORE_stsmlq | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 263 of file core_stsmlq.c.
References CORE_stsmlq_quark(), DAG_CORE_TSMLQ, INOUT, INPUT, LOCALITY, PlasmaLeft, QUARK_Insert_Task(), SCRATCH, and VALUE.
| void QUARK_CORE_stsmlq_corner | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | m3, | ||
| int | n3, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | A3, | ||
| int | lda3, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 219 of file core_stsmlq_corner.c.
References CORE_stsmlq_corner_quark(), INOUT, INPUT, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_U, SCRATCH, and VALUE.

| void QUARK_CORE_stsmlq_sytra1 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 174 of file core_stsmlq_sytra1.c.
References CORE_stsmlq_sytra1_quark(), INOUT, INPUT, PlasmaLeft, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_U, SCRATCH, and VALUE.

| void QUARK_CORE_stsmqr | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 258 of file core_stsmqr.c.
References CORE_stsmqr_quark(), DAG_CORE_TSMQR, INOUT, INPUT, LOCALITY, PlasmaLeft, QUARK_Insert_Task(), SCRATCH, and VALUE.
| void QUARK_CORE_stsmqr_corner | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | m3, | ||
| int | n3, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | A3, | ||
| int | lda3, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 214 of file core_stsmqr_corner.c.
References CORE_stsmqr_corner_quark(), INOUT, INPUT, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_L, SCRATCH, and VALUE.

| void QUARK_CORE_stsmqr_sytra1 | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 173 of file core_stsmqr_sytra1.c.
References CORE_stsmqr_sytra1_quark(), INOUT, INPUT, PlasmaLeft, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_L, SCRATCH, and VALUE.

| void QUARK_CORE_stsqrt | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 209 of file core_stsqrt.c.
References CORE_stsqrt_quark(), DAG_CORE_TSQRT, INOUT, LOCALITY, OUTPUT, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_U, SCRATCH, and VALUE.

| void QUARK_CORE_ststrf | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | U, | ||
| int | ldu, | ||
| float * | A, | ||
| int | lda, | ||
| float * | L, | ||
| int | ldl, | ||
| int * | IPIV, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request, | ||
| PLASMA_bool | check_info, | ||
| int | iinfo | ||
| ) |
Definition at line 220 of file core_ststrf.c.
References CORE_ststrf_quark(), DAG_CORE_TSTRF, INOUT, LOCALITY, OUTPUT, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_U, SCRATCH, and VALUE.

| void QUARK_CORE_sttlqt | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 244 of file core_sttlqt.c.
References CORE_sttlqt_quark(), DAG_CORE_TTLQT, INOUT, LOCALITY, OUTPUT, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_L, SCRATCH, and VALUE.

| void QUARK_CORE_sttmlq | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 259 of file core_sttmlq.c.
References CORE_sttmlq_quark(), DAG_CORE_TTMLQ, INOUT, INPUT, PlasmaLeft, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_L, SCRATCH, and VALUE.
| void QUARK_CORE_sttmqr | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | side, | ||
| int | trans, | ||
| int | m1, | ||
| int | n1, | ||
| int | m2, | ||
| int | n2, | ||
| int | k, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | V, | ||
| int | ldv, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 251 of file core_sttmqr.c.
References CORE_sttmqr_quark(), DAG_CORE_TTMQR, INOUT, INPUT, PlasmaLeft, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_U, SCRATCH, and VALUE.
| void QUARK_CORE_sttqrt | ( | Quark * | quark, |
| Quark_Task_Flags * | task_flags, | ||
| int | m, | ||
| int | n, | ||
| int | ib, | ||
| int | nb, | ||
| float * | A1, | ||
| int | lda1, | ||
| float * | A2, | ||
| int | lda2, | ||
| float * | T, | ||
| int | ldt | ||
| ) |
Definition at line 244 of file core_sttqrt.c.
References CORE_sttqrt_quark(), DAG_CORE_TTQRT, INOUT, LOCALITY, OUTPUT, QUARK_Insert_Task(), QUARK_REGION_D, QUARK_REGION_U, SCRATCH, and VALUE.

 1.8.1
1.8.1 
