|
PLASMA
2.4.5
PLASMA - Parallel Linear Algebra for Scalable Multi-core Architectures
|
|
PLASMA
2.4.5
PLASMA - Parallel Linear Algebra for Scalable Multi-core Architectures
|
#include "common.h"
Go to the source code of this file.
Macros | |
| #define | A(m, n) BLKADDR(A, PLASMA_Complex32_t, m, n) |
| #define | L(m, n) BLKADDR(L, PLASMA_Complex32_t, m, n) |
| #define | IPIV(m, n) &(IPIV[(int64_t)A.mb*((int64_t)(m)+(int64_t)A.mt*(int64_t)(n))]) |
Functions | |
| void | plasma_pcgetrf_incpiv (plasma_context_t *plasma) |
| void | plasma_pcgetrf_incpiv_quark (PLASMA_desc A, PLASMA_desc L, int *IPIV, PLASMA_sequence *sequence, PLASMA_request *request) |
PLASMA auxiliary routines PLASMA is a software package provided by Univ. of Tennessee, Univ. of California Berkeley and Univ. of Colorado Denver
Definition in file pcgetrf_incpiv.c.
| #define A | ( | m, | |
| n | |||
| ) | BLKADDR(A, PLASMA_Complex32_t, m, n) |
Definition at line 19 of file pcgetrf_incpiv.c.
| #define IPIV | ( | m, | |
| n | |||
| ) | &(IPIV[(int64_t)A.mb*((int64_t)(m)+(int64_t)A.mt*(int64_t)(n))]) |
Definition at line 21 of file pcgetrf_incpiv.c.
| #define L | ( | m, | |
| n | |||
| ) | BLKADDR(L, PLASMA_Complex32_t, m, n) |
Definition at line 20 of file pcgetrf_incpiv.c.
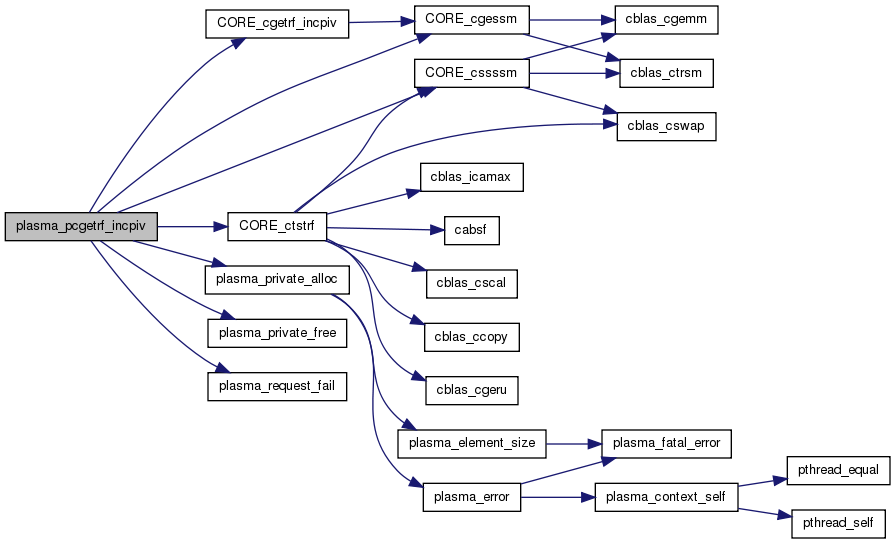
| void plasma_pcgetrf_incpiv | ( | plasma_context_t * | plasma | ) |
Parallel tile LU factorization - static scheduling
Definition at line 25 of file pcgetrf_incpiv.c.
References A, BLKLDD, CORE_cgessm(), CORE_cgetrf_incpiv(), CORE_cssssm(), CORE_ctstrf(), plasma_desc_t::dtyp, IPIV, L, plasma_desc_t::m, plasma_desc_t::mb, min, plasma_desc_t::mt, plasma_desc_t::n, plasma_desc_t::nb, plasma_desc_t::nt, PLASMA_IB, plasma_private_alloc(), plasma_private_free(), PLASMA_RANK, plasma_request_fail(), PLASMA_SIZE, PLASMA_SUCCESS, plasma_unpack_args_5, ss_abort, ss_aborted, ss_cond_set, ss_cond_wait, ss_finalize, ss_init, and plasma_sequence_t::status.
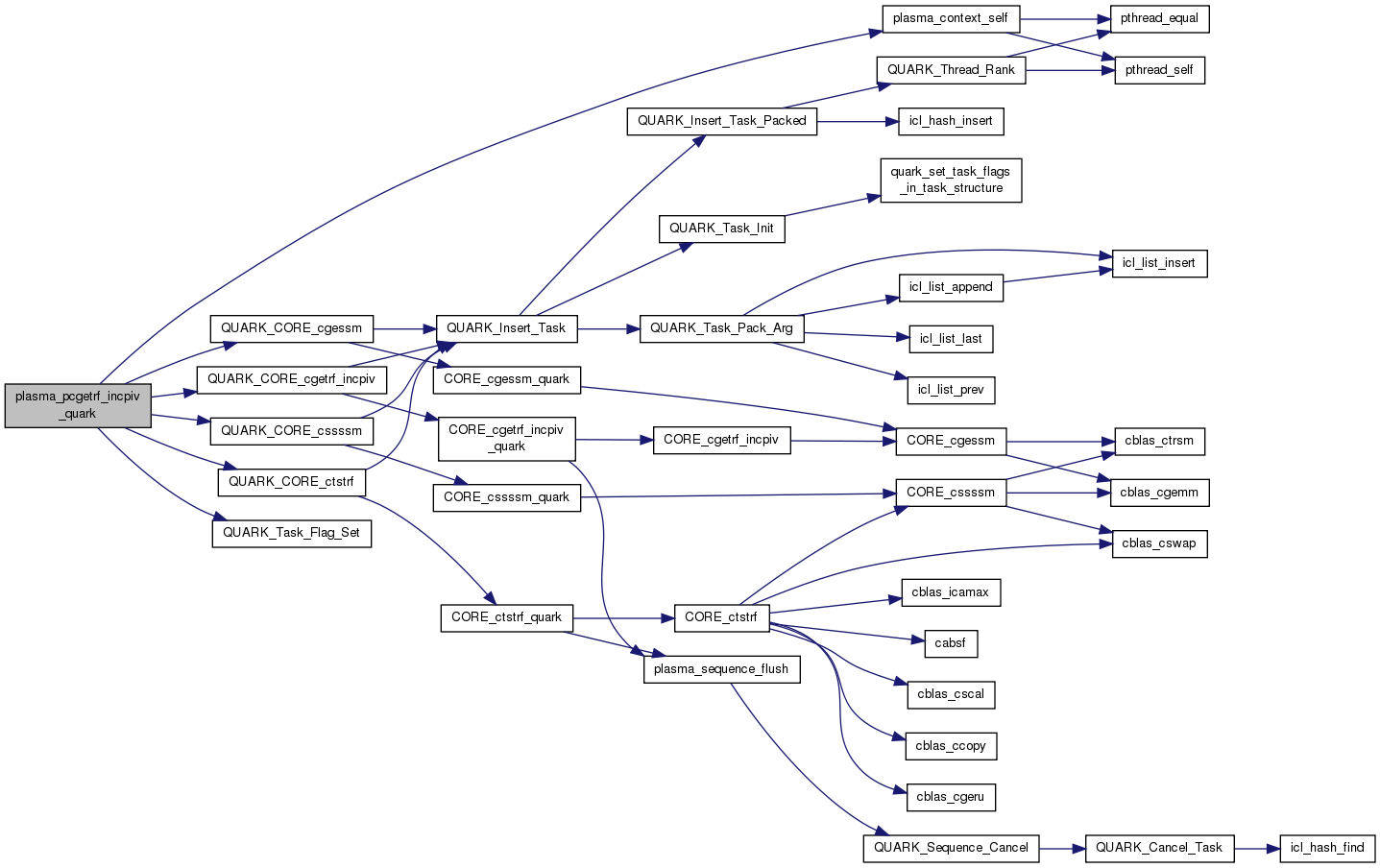
| void plasma_pcgetrf_incpiv_quark | ( | PLASMA_desc | A, |
| PLASMA_desc | L, | ||
| int * | IPIV, | ||
| PLASMA_sequence * | sequence, | ||
| PLASMA_request * | request | ||
| ) |
Parallel tile LU factorization - dynamic scheduling
Definition at line 143 of file pcgetrf_incpiv.c.
References A, BLKLDD, IPIV, L, plasma_desc_t::m, plasma_desc_t::mb, min, plasma_desc_t::mt, plasma_desc_t::n, plasma_desc_t::nb, plasma_desc_t::nt, plasma_context_self(), PLASMA_IB, PLASMA_SUCCESS, plasma_context_struct::quark, QUARK_CORE_cgessm(), QUARK_CORE_cgetrf_incpiv(), QUARK_CORE_cssssm(), QUARK_CORE_ctstrf(), plasma_sequence_t::quark_sequence, QUARK_Task_Flag_Set(), Quark_Task_Flags_Initializer, plasma_sequence_t::status, and TASK_SEQUENCE.
 1.8.1
1.8.1 
