
News and Announcements
Joint Laboratory for Extreme Scale Computing
ICL is now an Associate Partner of the Joint Laboratory for Extreme Scale Computing (JLESC). JLESC, founded in 2009 by the French Institute for Research in Computer Science and Automation (INRIA) and the National Center for Supercomputing Applications (NCSA) at the University of Illinois at Urbana-Champaign, is an international, virtual organization that aims to enhance the ability of member organizations and investigators to overcome software challenges found in extreme scale, high-performance computers.
JLESC engages computer scientists, engineers, application scientists, and industry leaders to ensure that the research facilitated by the joint laboratory addresses science and engineering’s most critical needs and takes advantage of the continuing evolution of computing technologies. Other partners include Argonne National Laboratory, the Barcelona Supercomputing Center, Jülich Supercomputing Center, and the RIKEN Center for Computational Science.
Conference Reports
8th JLESC Workshop

The 8th JLESC workshop was held on April 17–19 in Barcelona, Spain. This workshop brought together leading researchers in HPC from the JLESC partners—INRIA, the University of Illinois at Urbana-Champaign, Argonne National Laboratory, the Barcelona Supercomputing Center, Jülich Supercomputing Center, RIKEN AICS, and ICL—to explore the most recent and critical issues facing HPC as we enter the extreme-scale era.
As ICL’s first JLESC workshop, we sent a member of each research group to present ICL’s latest work in linear algebra libraries (LA), distributed computing (DisCo), and performance monitoring (PICL).
Representing the LA efforts and ICL as a whole, Jack Dongarra gave a presentation on “Experiments with Energy Savings and Short Precision.” Thomas Herault presented DisCo’s latest work on resilience (SMURFS project) in “Performance of (Un)cooperative Periodic Checkpointing in Shared Environments.” He wasn’t finished there, however, as he also talked about DisCo’s foray into deep learning and machine learning.
Also representing the DisCo effort, George Bosilca presented his thoughts on “Termination detection: Are we done yet?” while also serving on the panel for the discussion of (international) supercomputer users. Finally, Anthony Danalis discussed PICL’s latest efforts with the PAPI project in a presentation called, “PAPI: Measuring outside the Box.”
The 9th JLESC workshop is already set for April of 2019, and ICL/UTK will be hosting this next iteration here in Knoxville, TN.
The editor would like to thank Thomas Herault and Rosa Badia for their contributions to this article.
2018 NSF SI2 PI Workshop


The 2018 National Science Foundation (NSF) Software Infrastructure for Sustained Innovation (SI²) Principal Investigator (PI) workshop was held on April 30 and May 1 at the The Westin in Washington, DC. This year’s workshop, which also happens to be the last SI² workshop hosted by the NSF, was co-located with the 18th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing (CCGrid’18).
Around 180 participants showed up for the workshop, where SI² PIs were expected to give a brief talk to introduce their project and present a poster during one of the four poster sessions.
ICL’s Heike Jagode presented the latest work on the SI2-SSE: PAPI Unifying Layer for Software-Defined Events (PULSE) project, which focuses on enabling cross-layer and integrated monitoring of whole application performance by extending PAPI with the capability to expose performance metrics from key software components found in the HPC software stack.
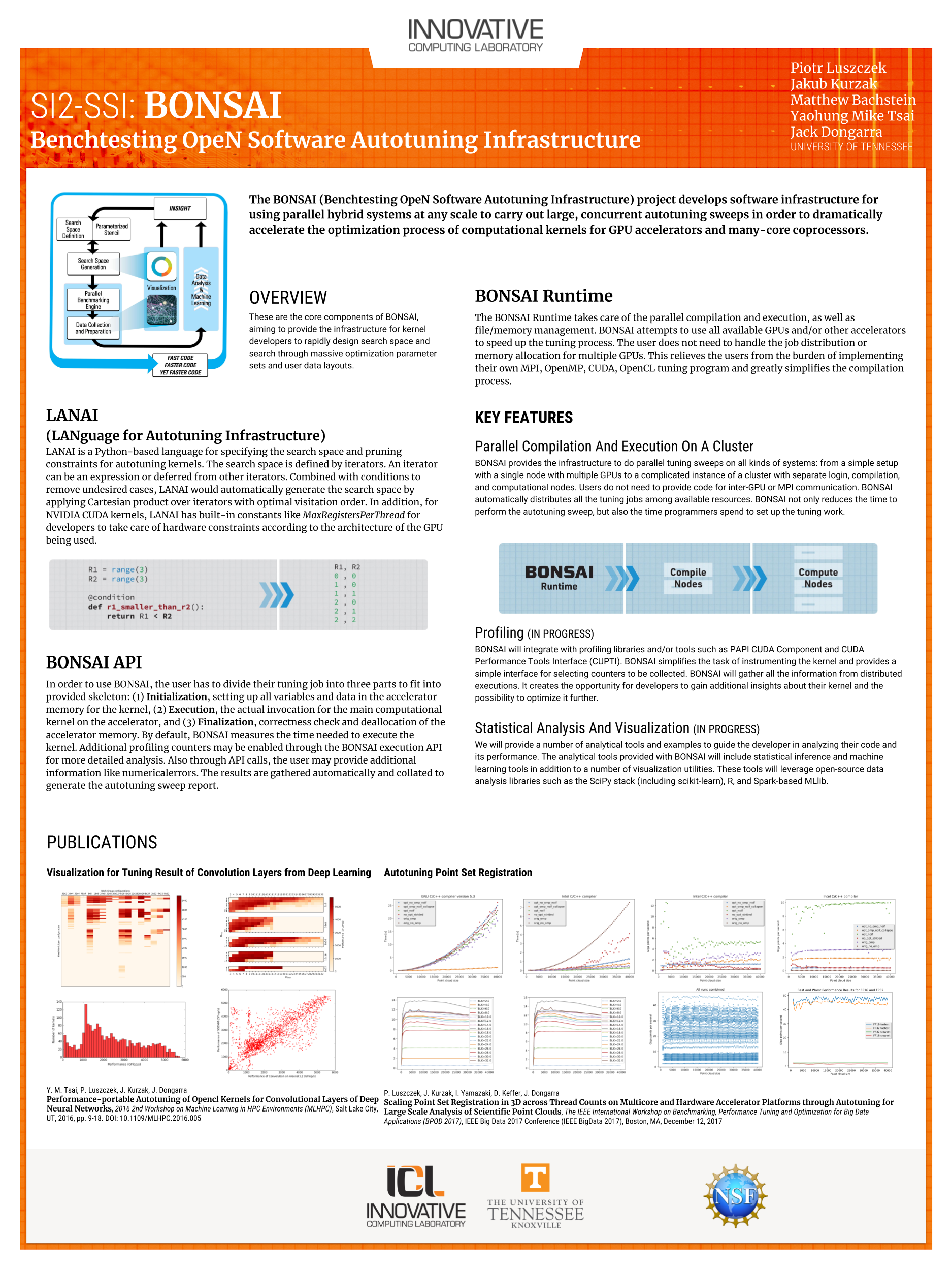
Piotr Luszczek showed off his team’s work on SI2-SSE: An Open Software Infrastructure for Parallel Autotuning of Computational Kernels (BONSAI). BONSAI aims to develop software infrastructure for using scalable, parallel hybrid systems to carry out large, concurrent autotuning sweeps in order to dramatically accelerate the optimization process of computational kernels for GPU accelerators and many-core coprocessors.
George Bosilca was on deck to show the DisCo team’s latest work for the SI2-SSI: Task Based Environment for Scientific Simulation at Extreme Scale (TESSE) project. TESSE uses an application-driven design to create a general-purpose, production-quality software framework that attacks the twin challenges of programmer productivity and portable performance for advanced scientific applications on massively-parallel, hybrid, many-core systems of today and tomorrow.


George also presented ICL’s latest work in the SI2-SSI: Evolve: Enhancing the Open MPI Software for Next Generation Architectures and Applications project. Evolve, a collaborative effort between ICL and the University of Houston, expands the capabilities of Open MPI to support the NSF’s critical software infrastructure missions. Core challenges include: extending the software to scale to 10,000–100,000 processes; ensuring support for accelerators; enabling highly asynchronous execution of communication and I/O operations; and ensuring resilience.
Azzam presented a poster for the SI2-SSE: MAtrix, TEnsor, and Deep-learning Optimized Routines (MATEDOR) project. MATEDOR will perform the research required to define a standard interface for batched operations and to provide a performance-portable software library that demonstrates batching routines for a significant number of kernels. This research is critical, given that the performance opportunities inherent in solving many small batched matrices often yield more than a 10× speedup over the current classical approaches.
Vince Weaver—now a professor at the University of Maine—presented work on the SI2-SSI: Collaborative Proposal: Performance Application Programming Interface for Extreme-Scale Environments (PAPI-EX) project. PAPI’s new powercap component enables power measurement without root privilege as well as power control. This new component exposes running average power limit (RAPL) functionality to enable users to read and write power parameters via PAPI_read() and PAPI_write().



The editor would like to thank Heike Jagode and Piotr Luszczek for their contributions to this article.
BDEC: Next Generation

The latest Big Data and Extreme Scale Computing (BDEC) workshop, dubbed “BDEC: Next Generation” or “BDEC: NG,” was held in Chicago, IL on March 26–28. BDEC: NG marks the 10th entry in a series premised on the idea that we must begin to systematically map out and account for the ways in which the major issues associated with big data intersect with, impinge upon, and potentially change the national (and international) plans that are now being laid out for achieving exascale computing.
Where the original BDEC workshops focused on high-performance computing (HPC) and big data effects on science (and computational science in particular), BDEC: NG expands the scope of the traditional role of big data within scientific computing—from the usual simulation and modeling to data analytics used to search the noise for phenomena that might require additional study and to verify existing models and simulations.
A reorientation of the BDEC effort—in the form of BDEC: NG—is essential for planning a new road map for the changing landscape of big data and exascale computing. Previous BDEC efforts cultivated and solidified an international cooperative, and BDEC: NG will leverage these relationships.
The editor would like to thank Terry Moore for his contribution to this article.
Interview

Tony Castaldo
Where are you from, originally?
From a military Air Force background. I was born in Washington, DC, and we were immediately transferred to Hawaii; leaving Hawaii when I was in the first grade. My father was stationed for five and six year tours, and after Hawaii we were stationed in San Antonio, then Illinois, and then my father retired, and my family moved back to San Antonio. I got a job and remained in Illinois to finish the last two years of high school.
Can you summarize your educational background?
Mostly unintentional. In high school my interest in mathematics led me to programming. I joined the military and taught myself more programming; after that I used the GI Bill to finish an associates degree in computer programming. I programmed boot-level assembly for embedded devices and OS and assembly level code for about twenty-five years. After the dot crash (I had cashed out more than a year before, out of analytic alarm) contracting gigs dried up, and I decided to return to college for a few years to let the market recover. It was great fun and turned into ten years. I finished a Bachelor’s and Master’s in Mathematics, then a Master’s and PhD in CS, and then became a full-time research assistant professor (with Clint Whaley, my PhD advisor).
Where did you work before joining ICL?
Many places; most places for a year or two at a time, as an on-and-off contractor. I have worked full-time at a large bank (processing credit card authorizations), a communications device manufacturer (boot-level device code, communications, and compression algorithms), and a large hospital (IBM mainframe systems programmer). My immediately prior job was with Minimal Metrics, a contract software company owned by Phil Mucci.
How did you first hear about the lab, and what made you want to work here?
In CS graduate school my advisor was Clint Whaley; working on the ATLAS linear algebra package. Clint was contacted by Philip Mucci, and I ended up on a contract with Phil to adapt ATLAS to install on a new kind of hardware setup. That was successful, and I continued to contract with Phil, and some years later I agreed to join a venture with him to develop a commercial project based on Perfminer. We failed to raise venture capital before we ran out of money. We both began looking for other work. Both Clint and Phil had told me about ICL, and Phil noticed the job opening and sent it to me. I am a fan of lower-level software tools and statistical analysis and also a fan of the academic environment and open-source code in general. I worked longer with Clint Whaley than any other person in my life, and I enjoyed it immensely. ICL seemed like a good fit.
What is your focus here at ICL? What are you working on?
Exascale PAPI, supporting a DoD Project. At the moment, my introductory project is automatic discovery (by benchmarks and statistical methods) of PAPI events that track common hardware events (e.g., which events count mispredicted branches). I expect to move on to more project-oriented tasks in the near future.
What are your interests/hobbies outside of work?
I am currently teaching myself to write fantasy fiction, and I’ve completed two books (unpublished). I read extensively, primarily non-fiction that leans scientific. Last year I read Piketty’s Capital and Seyfried’s Cancer as a Metabolic Disease (a new approach to the biology and treatment of cancer). I read science of any form extensively.
Tell us something about yourself that might surprise people.
I don’t believe in the Big Bang, Inflation, String Theory, Dark Matter, or Dark Energy. I suspect they are all the naming of unresolved problems in physics to pretend they are solved, except for a few pesky details nobody can figure out, like theoretical particles nobody can find. Of course I am on the outside looking in, and I’d be happy to see proof I am wrong!
If you weren’t working at ICL, where would you like to be working and why?
I suppose I should say if I were not working at ICL, I would like to be working at ICL!
Pretty much any applied scientific research interests me, if it has real world impact. From the subatomic to (statistically justified versions of) economics, biology, sociology, psychology, and alternative energy. So, wherever cool work can be done. I don’t really have specific career goals or ambition to achieve anything specific. When looking for work, I am more inclined to look for interesting problems or ideas, where I believe I can contribute to the effort.






















