ICL@SC22


The International Conference for High Performance Computing, Networking, Storage, and Analysis
Kay Bailey Hutchison Convention Center – Dallas, Texas
November 13–18, 2022
This year SC22 was well represented by the researchers and students of the Innovative Computing Laboratory (ICL) and the Global Computing Lab (GCL). Jack Dongarra presented the highly anticipated ACM A.M. Turing Award Lecture and the much-discussed TOP500; multiple ICL researchers presented in panels and workshops; talks at the University of Tennessee booth; and various ICL faculty and students participating in the six-day event, ICL and GCL made a strong showing. Highlights included Dongarra’s lecture and the Gordon Bell Prize Finalist session featuring ICL research assistant professor George Bosilca, honored for his work on developing an “adaptive approach” that scales across systems and achieves up to a 12× performance speedup against those traditional implementations.
Several ICL researchers appeared on a wide range of panels and sessions, demonstrating ICL’s broad impact on research, distribution, and the overall direction of high performance computing. ICL member Heike Jagode was the SC22 Technical Program Vice Chair, responsible for the entire Tech Program. Yves Roberts was the Posters Vice Chair, and Jack Dongarra presented ICL-sponsored awards for HPL-MxP and HPCG benchmark leaders. ICL’s students participated in paper and poster sessions, and ICL student Daniel Berry served as an HQ lead student volunteer. Additionally, ICL was involved in numerous informal discussions over the week, ranging from chance meetings between sessions to various receptions and dinners.
In addition to Jack Dongarra’s ACM A.M. Turing Award Lecture, which featured the history of Jack’s pioneering contributions to numerical algorithms that enabled HPC software to keep pace with exponential hardware improvements for over four decades, ICL’s scholars made an impressive showing with numerous contributions to the event. In his Gordon Bell Prize Finalist Session, George Bosilca examined combining the linear algebraic contributions of mixed-precision and low-rank computations within a tile-based Cholesky solver with the on-demand casting of precisions and dynamic runtime support from PaRSEC to orchestrate tasks and data movement.
ICL faculty and researchers provided additional contributions to the conference. In an early first-day panel, ICL Director Hartwig Anzt kicked off ICL’s engagement in SC22, discussing views and ideas for addressing the most crucial problems in adopting AC in HPC. ICL research assistant professor Piotr Luszczek proposed a new benchmark for ranking high-performance (HP) computers, designed to rank based on how fast they can solve a sparse linear system of equations. Other ICL research assistant professors, such as Stanimire Tomov, demonstrated the impact of irrLU-GPU on sparse LU solvers using NVIDIA and AMD GPUs and shared results and findings. Meanwhile, Anthony Danalis served on the 4th Workshop on Programming and Performance Visualization Tools which brought together HPC application developers, tool developers, and researchers from the visualization, performance, and program analysis fields to exchange new approaches to assist developers in analyzing, understanding and optimizing programs for extreme-scale platforms. ICL research scientist Asim YarKhan circularized the SLATE project’s work toward implementing a distributed dense linear algebra library for highly scalable distributed-memory accelerator-based computer systems.





Once again, joining ICL in representing the University of Tennessee system, Global Computing Lab (GCL), sent a strong contingent of researchers, faculty, and students to SC22. GCL director Michela Taufer and research assistant professor Silvina Caino-Lores participated in workshops, presenting the need for HPC and Cloud convergence for scientific workflows’ reusability, scalability, reproducibility, and trustworthiness and proposing an efficient method to co-schedule and allocate resources for a workflow ensemble that minimizes the makespan. Additionally, GCL research assistant professor Jakob Luettgau led a “Birds of a Feather” dialogue focused on expanding the conversation related to ethical considerations in the field of HPC and its role in shaping society. Not to be left out, several GCL students hosted multiple Booth Talks throughout the event.
Official SC22 photos by Jo Ramsey, SC Photography
ACM Turing Award lecture at SC22


A full write-up of the A.C.M. Turing Award lecture and Recording are available thanks to HPC-Wire, who were in attendance.
ICL Research Identified as Gordon Bell Prize Finalist
On Thursday, November 17, the Association for Computing Machinery’s 2022 Gordon Bell Prize was announced at the SC22 conference in Dallas, Texas, in recognition of the year’s most innovative work in computer science. Among the finalists was a team of researchers at Innovative Computing Laboratory, who have been developing methods to increase computing performance by distinguishing between components within extensive simulations that require high precision and those that can be calculated less precisely. Focusing on large-scale climate simulations, the team increased performance by 12 over the state-of-the-art reference implementation. Their work -Reshaping Geostatistical Modeling and Prediction for Extreme-Scale Environmental Applications – combined contributions from ICL and KAUST.
The Gordon Bell Prize is awarded yearly to recognize outstanding achievement in high-performance computing. The award aims to track the progress over time of parallel computing, with particular emphasis on rewarding innovation in applying high-performance computing to applications in science, engineering, and large-scale data analytics. The Gordon Bell Prizes typically recognize simulations on the world’s largest computers.
After proving their method’s effectiveness and scalability, the research team was granted access to Fugaku — a supercomputer located at Japan’s RIKEN Center for Computational Science. To do this, they tested it on other HPC systems with various architectures, including the High-Performance Computing Center Stuttgart’s (HLRS’s) Hawk supercomputer. Their adaptive approach scaled on multiple systems and leveraged the Fujitsu A64FX nodes of Fugaku to achieve up to 12X performance speedup against the highly optimized dense Cholesky implementation.
Leading ICL’s contribution to the project, George Bosilca expressed genuine excitement about the access to Fugaku afforded by the project. ICL, using PaRSEC, provided the computational power necessary for the method.
November 2022 TOP500


Unveiled at this year’s ISC High Performance Computing (ISC-HPC) conference on November 14, 2022, the 60th edition of the TOP500 saw little change in the Top 10. Frontier machine at Oak Ridge National Laboratory (ORNL) continues to hold the No. 1 position it first earned in June 2022. Its HPL benchmark score is 1,102. Pflop/s, exceeding the performance of Fugaku at No. 2 by almost 3x. LUMI, an HPE-built system at a EuroHPC site in Finland, is at No. 3. The new No. 4 system, Leonardo, is installed at a different EuroHPC site in CINECA, Italy.
Summit, an IBM-built system at the Oak Ridge National Laboratory (ORNL) in Tennessee, USA, is now listed at the No. 5 spot worldwide with a performance of 148.8 Pflop/s on the HPL benchmark, which is used to rank the TOP500 list.
Click here to see how the rest of the TOP500 panned out.
| Rank | System | Cores | Rmax (PFlop/s) | Rpeak (PFlop/s) | Power (kW) |
| 1 | Frontier – HPE Cray EX235a, AMD Optimized 3rd Generation EPYC 64C 2GHz, AMD Instinct MI250X, Slingshot-11, HPE DOE/SC/Oak Ridge National Laboratory United States |
8,730,112 | 1,102.00 | 1,685.65 | 21,100 |
| 2 | Supercomputer Fugaku – Supercomputer Fugaku, A64FX 48C 2.2GHz, Tofu interconnect D, Fujitsu RIKEN Center for Computational Science Japan |
7,630,848 | 442.01 | 537.21 | 29,899 |
| 3 | LUMI – HPE Cray EX235a, AMD Optimized 3rd Generation EPYC 64C 2GHz, AMD Instinct MI250X, Slingshot-11, HPE EuroHPC/CSC Finland |
2,220,288 | 309.10 | 428.70 | 6,016 |
| 4 | Leonardo – BullSequana XH2000, Xeon Platinum 8358 32C 2.6GHz, NVIDIA A100 SXM4 64 GB, Quad-rail NVIDIA HDR100 Infiniband, Atos EuroHPC/CINECA Italy |
1,463,616 | 174.70 | 255.75 | 5,610 |
| 5 | Summit – IBM Power System AC922, IBM POWER9 22C 3.07GHz, NVIDIA Volta GV100, Dual-rail Mellanox EDR Infiniband, IBM DOE/SC/Oak Ridge National Laboratory United States |
2,414,592 | 148.60 | 200.79 | 10,096 |
HPCG and HPL-MxP Results



HPCG Results
The TOP500 list has incorporated the High-Performance Conjugate Gradient (HPCG) benchmark results, which provide an alternative metric for assessing supercomputer performance. This score is meant to complement the HPL measurement to give a fuller understanding of the machine.
The winner is Fugaku, with a score of 16.0 HPCG-petaflops. Unlike the last list, Frontier has submitted HPCG data and achieved an HPCG score of 14.054 HPCG-petaflops. This puts it at the No. 2 spot above LUMI, which scored 3.408 HPCG-petaflops.

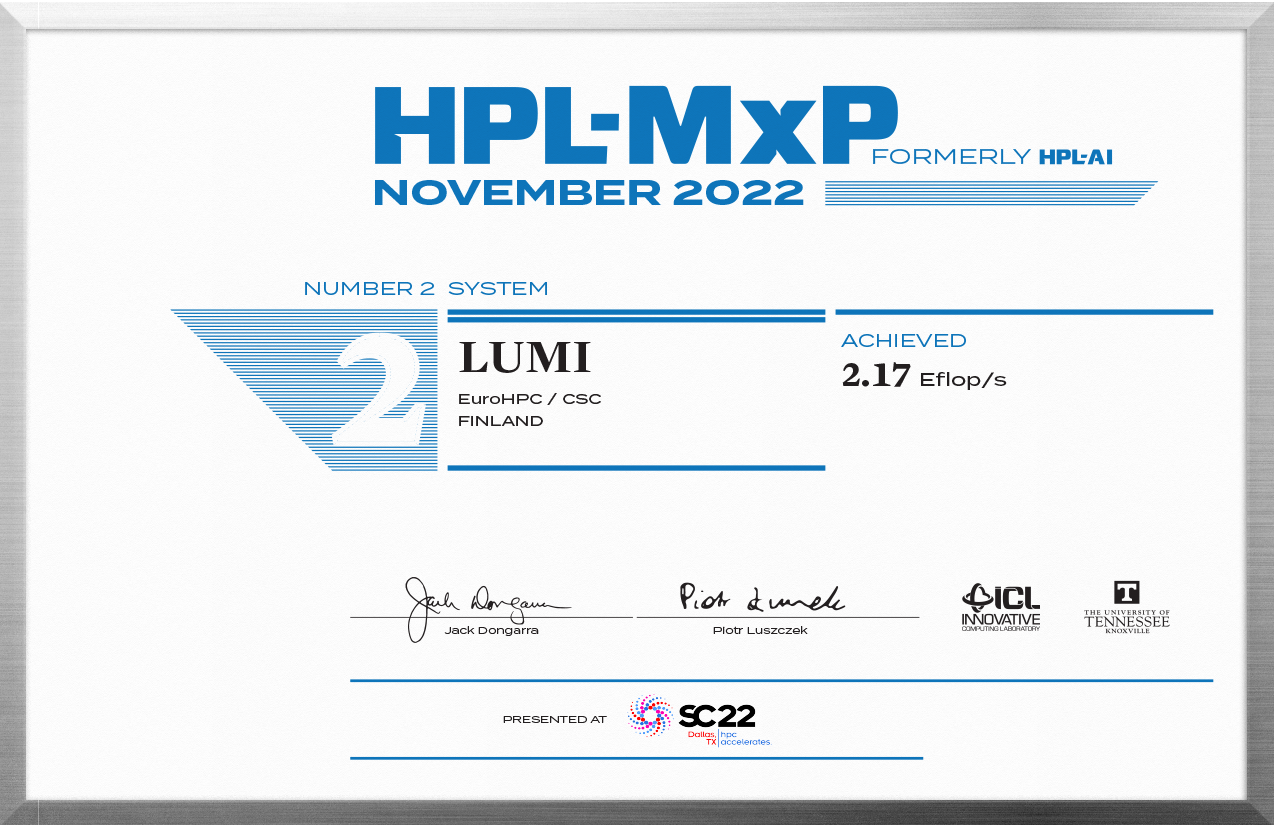

HPL-MxP Results (formally HPL-AI)
The HPL-MxP benchmark highlights the convergence of HPC and artificial intelligence (AI) workloads based on machine learning and deep learning by solving linear equations using novel, mixed-precision algorithms that exploit modern hardware.
This year’s winner is Frontier, with a 7.9 EFlop/s score on the HPL-AI benchmark test. Lumi was in second place with a score of 2.2 Eflop/s, followed by the Fugaku machine with a score of 2.0 Eflop/s
SC22 ICL Alumni Dinner



With SC22 once again featuring in-person attendance, members of ICL and other related attendees were able to meet up for dinner in Dallas. The group included current and alums ICL employees and current GCL members, with roughly twenty-five attendees. Held at Bob’s Steak and Chop House on Nov 16th, with an initial cocktail reception, the dinner provided an atmosphere of camaraderie and cooperation. Inside the Omni Dallas Hotel, Bob’s Steak and Chop House was a brisk walk from the SC22 Kay Bailey Hutchison Convention Center. Alumni each took a moment to re-introduce themselves and discuss their current endeavors. It was an excellent opportunity for attendees to talk about future collaborations and maintain relationships with those now working in the industry outside of ICL.
Recent Releases
PAPI 7.0.0 Released
PAPI 7.0.0 was announced on November 15th and is now available. This release offers several new components, including “intel_gpu” with monitoring capabilities on Intel GPUs; “sysdetect” (along with a new user API) for detecting details of the available hardware on a given compute system; a significant revision of the “rocm” component for AMD GPUs; the extension of the “cuda” component to enable performance monitoring on NVIDIA’s compute capabilities 7.0 and beyond. PAPI 7.0.0 ships with a standalone “libsde” library and a new C++ API for software developers to define software-defined events from within their applications.
For specific and detailed information on changes made for this release, see ChangeLogP700.txt for filenames or keywords of interest and change summaries, or go directly to the PAPI git repository.
Some Major Changes for PAPI 7.0.0 include:
- A new “intel_gpu” component with monitoring capabilities support for Intel GPUs, which offers two collection modes: (1) “Time-based Collection Mode,” where metrics can be read at any given time during the execution of kernels. (2) “Kernel-based Collection Mode,” where performance counter data is available once the kernel execution is finished.
- A new “sysdetect” component for detecting a machine’s architectural details, including the hardware’s topology, specific aspects about the memory hierarchy, number and type of GPUs and CPUs on a node, thread affinity to NUMA nodes and GPU devices, etc.
- A significant redesign of the “rocm” component for advanced monitoring features for the latest AMD GPUs.
- Support for NVIDIA compute capability 7.0.
- A significant redesign of the “sde” component into two separate entities: (1) a standalone library “libsde” with a new API for software developers to define software-based metrics from within their applications, and (2) the PAPI “sde” component that enables monitoring of these new software-based events.
- A new C++ interface for “libsde” enables software developers to define software-defined events from within their C++ applications.
- New Counter Analysis Toolkit (CAT) benchmarks and refinements of PAPI’s CAT data analysis, expressly, the extension of PAPI’s CAT with MPI and “distributed memory”-aware benchmarks and analysis to stress all cores per node.
- Support FUGAKU’s A64FX Arm architecture, including monitoring capabilities for memory bandwidth and other node-wide metrics.
The PAPI team would like to express special Thanks to Vince Weaver, Stephane Eranian (for libpfm4), William Cohen, Steve Kaufmann, Peinan Zhang, John Rodgers, Yamada Masahiko, Thomas Richter, and Phil Mucci.
PAPI 7.0.0 can be downloaded here: http://icl.cs.utk.edu/papi/software.
Ginkgo Minor Release 1.5.0
The Ginkgo team is proud to announce the new Ginkgo minor release, 1.5.0. This release brings many significant new features, including MPI-based multi-node support for all matrix formats and most solvers, full DPC++/SYCL support, functionality, and interfaces for GPU-resident sparse direct solvers, and an interface for wrapping solvers with scaling and reordering applied. Ginkgo 1.5.0 features a new algebraic Multigrid solver/preconditioner with improved mixed-precision support. Ginkgo 1.5.0 also addresses the need for support for device matrix assembly and many more improvements and fixes.
Check out the Ginkgo release page for a full run-down of the release and access.



























