

The scheduler implements a multi-level priority queue with three levels of queuing: "on demand," "high priority," and "best effort." After the scheduler checks the urgency level and priority of each request, it places them in the correct queue in the correct order. The dispatcher selects the next request to be executed and creates a subworkflow (DAG) for each request. These subworkflows are then submitted to the workflow manager.
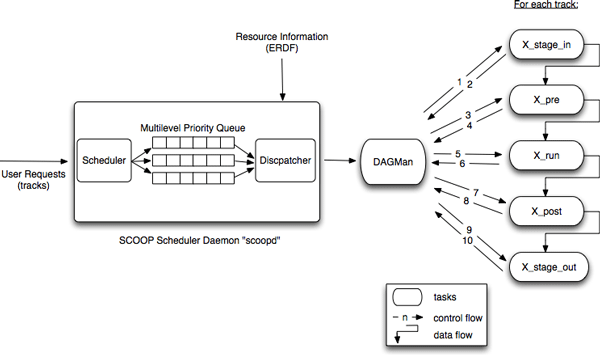
As the workflow manager, we are using an enhanced version of Condor DAGMan. This version of DAGMan enables us to visually monitor the execution of the ensemble tracks from a web-based graphical interface. The status of each sub-task of each track, as well as the execution time of each step can easily be monitored using this interface. DAGMan submits these workflows to the queues specified by the Application Manager using Condor-G. An illustration of the scheduler is shown in Figure 6.
The SCOOP scheduler queues are used mainly for internal prioritization and ordering, though the component also makes sure that the requests are mapped to the right kind of resources and queues. Once the jobs are dispatched, the quality of service received by the job is determined by the local resource policies and procedures, which are discussed in the next section.
The SCOOP system uses resources from various different grids such as the Louisiana Optical Network Initiative (LONI), SURAGrid and TeraGrid 6. All three grids have a very different mode of operation and administration. For instance the LONI grid is centrally administered and all policies are enforced on all resources. SURAGrid allows greater flexibility and control and policy making is in the hands of individual resource providers. The TeraGrid is also composed of resources that are administered by the resource providers. All three grids implement access to on-demand resources in a variety of ways. LONI machines make use of SPRUCE and preempt queues to offer on-demand resources. SURAGrid uses Loadleveler supported checkpoint restart mechanisms to provide access to on-demand resources by suspending running jobs. TeraGrid has an entire cluster dedicated for on-demand jobs. For SCOOP, so far we have primarily used the LONI and SURAGrid on-demand resources.
On the LONI machines, the processors are divided into two groups, AIX based and Linux based. The machines run their independent schedulers, and the processors on each resource are further subdivided into a preemptory pool and a dedicated pool. The preemptive queues feed the Preemptive pool of processors, and the dedicated queues feed the rest of the system. The checkpoint queues, which include all processors in both pools, can be used to submit system wide jobs. The job restart information should be saved periodically for the jobs in the checkpoint queue as they may be preempted when an urgent job arrives in the preempt queue. On the LONI systems, this is left for the user to do along with choosing an appropriate queue for submission. On the LONI AIX frames, the preempt queue is allowed a maximum of 48 processors. The rest of the available processors are in the dedicated queue called workq. Jobs in the checkpoint queue (checkpt) can run on the entire machine. Also the maximum allowed wall clock time for jobs is typically longer in the workq and shorter in the preempt queues. SURAGrid, as part of the resource agreement with resource providers, has access to 20% of the resource that some resources, such as Janus at GSU, offer as on-demand resources.


