

The SPRUCE eventflow is designed for application teams that provide computer-aided decision support or instrument control. A principal investigator (PI) organizes each application team and selects the computational “first responders,” senior staff who may initiate an urgent computing session. First responders are responsible for evaluating the situation in light of the policies for using urgent computing.
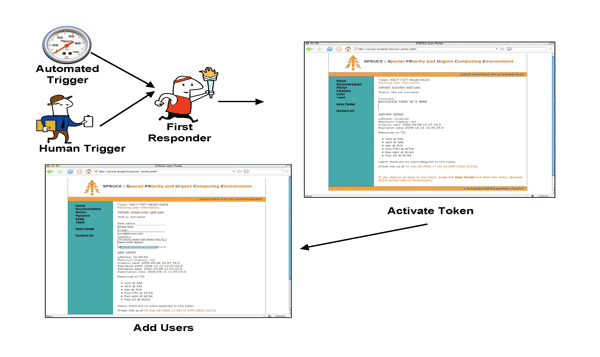
As illustrated in Figure 4, the SPRUCE eventflow begins as the result of a trigger, which may be automatic (e.g., an automated warning from weather advisory RSS feed) or human-generated (e.g., a phone call to the PI). SPRUCE token holders are expected to use tokens with discretion and according to coordinated policies, similar to the way that citizens are expected to use good judgment before dialing 911. Token usage will be monitored and reviewed. Administrators can revoke tokens at any time. The first responder begins interaction with the SPRUCE system by initiating a session. Token activation can be done through a Web-based user portal or via a Web service interface. Systems built from the Web service interface can be automated and incorporated into domain-specific toolsets, avoiding human intervention. The initiator of the SPRUCE session can indicate which scientist or set of scientists will be able to request elevated priority while submitting urgent jobs. This set may later be augmented or edited.
Once a token is activated and the application team has been specified, scientists can organize their computation and submit jobs. Naturally, there is no time to port the application to new platforms or architectures or to try a new compiler. Applications must be prepared for immediate use—they must be in “warm standby.” All of the application development, testing, and tuning must be complete prior to freezing the code and marking it ready for urgent computation. In the same way that emergency equipment, personnel, and procedures are periodically tested for preparedness and flawless operation, SPRUCE proposes to have applications and policies in warm-standby mode, being periodically tested and their date of last validation logged.
From this pool of warm-standby Grid resources, the team must identify where to submit their urgent jobs. One computing facility site may provide only a slightly increased priority to SPRUCE jobs, while another site may kill all the running jobs and allow an extremely urgent computation to use an entire supercomputer. Current job load and data movement requirements can also affect resource selection. Moreover, how a given application performs on each of the computational resources must also be considered. The SPRUCE advisor, currently under development, determines which resources offer the greatest probability to meet the given deadline. To accomplish this task, the advisor considers a wide variety of information, including the deadline, historical information (e.g., warm-standby logs, local site policies), live data (e.g., current network/ queue/resource status), and application-specific data (e.g., the set of warm-standby resources, performance model, input/output data repositories). To determine the likelihood of an urgent computation meeting a deadline on a given resource, the advisor calculates an upper bound on the total turnaround time for the job. More details on this implementation can be found in 14.


