LEAD Cyberinfrastructure to Track Real-Time Storms Using SPRUCE Urgent Computing

March 2008
|
LEAD Cyberinfrastructure to Track Real-Time Storms Using SPRUCE Urgent Computing
|
March 2008 |

The Linked Environments for Atmospheric Discovery (LEAD)1 2 project is pioneering new approaches for integrating, modeling, and mining complex weather data and cyberinfrastructure systems to enable faster-than-real-time forecasts of mesoscale weather systems, including those than can produce tornadoes and other severe weather. Funded by the National Science Foundation Large Information Technology Research program, LEAD is a multidisciplinary effort involving nine institutions and more than 100 scientists, students, and technical staff.
Foundational to LEAD is the idea that today’s static environments for observing, predicting, and understanding mesoscale weather are fundamentally inconsistent with the manner in which such weather actually occurs – namely, with often unpredictable rapid onset and evolution, heterogeneity, and spatial and temporal intermittency. To address this inconsistency, LEAD is creating an integrated, scalable framework in which meteorological analysis tools, forecast models, and data repositories can operate as dynamically adaptive, on-demand, Grid-enabled systems. Unlike static environments, these dynamic systems can change configuration rapidly and automatically in response to weather, react to decision-driven inputs from users, initiate other processes automatically, and steer remote observing technologies to optimize data collection for the problem at hand. Although mesoscale meteorology is the particular domain to which these innovative concepts are being applied, the methodologies and infrastructures are extensible to other domains, including medicine, ecology, hydrology, geology, oceanography, and biology.
The LEAD cyberinfrastructure is based on a service-oriented architecture (SOA) in which service components can be dynamically connected and reconfigured. A Grid portal in the top tier of this SOA acts as a client to the services exposed in the LEAD system. A number of stable community applications, such as the Weather Research and Forecasting model (WRF) 3, are preinstalled on both the LEAD infrastructure and TeraGrid 4 computing resources. Shell executable applications are wrapped into Web services by using the Generic Service Toolkit (GFac) 5. When these wrapped application services are invoked with a set of input parameters, the computation is initiated on the TeraGrid computing resources; execution is monitored through Grid computing middleware provided by the Globus Toolkit 6. As shown in Figure 1, scientists construct workflows using preregistered, GFac wrapped application services to depict dataflow graphs, where the nodes of the graph represent computations and the edges represent data dependencies. GPEL 7, a workflow enactment engine based on industry standard Business Process Execution Language 8, sequences the execution of each computational task based on control and data dependencies.
To dynamically interact and react to weather events (Figure 2), LEAD is working on adaptivity in four categories:
In the following paragraphs, we briefly elaborate on these categories.
Adaptivity in Simulations: In the simulation phase of the prediction cycle, adaptivity in the spatial resolution is essential in order to improve the accuracy of the result. Specifically, finer computational meshes are introduced in areas where the weather looks more interesting. These may be run as secondary computations that are triggered by interesting activities detected in geographic subdomains of the original forecast simulation. Or they may be part of the same simulation process execution if it has been re-engineered to use automatic adaptive mesh refinement. In any case, the fine meshes must track the evolution of the predicted and actual weather in real time. The location and extent of a fine mesh should evolve and move across the simulated landscape in the same way the real weather is constantly moving.
Adaptivity in Data Collection: If we attempt to increase the resolution of a computational mesh in a local region, we will probably need more resolution in the data gathered in that region. Fortunately, the next generation of radars being developed by Center for Collaborative Adaptive Sensing of the Atmosphere (CASA) 9 10 will be lightweight and remotely steerable. Hence, it will be possible to have a control service where a workflow can interact to retask the instruments to gain finer resolution in a specific area of interest. In other words, the simulation will have the ability to close the loop with the instruments that defined its driving data. If more resolution in an area of interest is needed, then more data can be automatically collected to make the fine mesh computationally meaningful. The relationship between LEAD and CASA is explained in detail in 11.
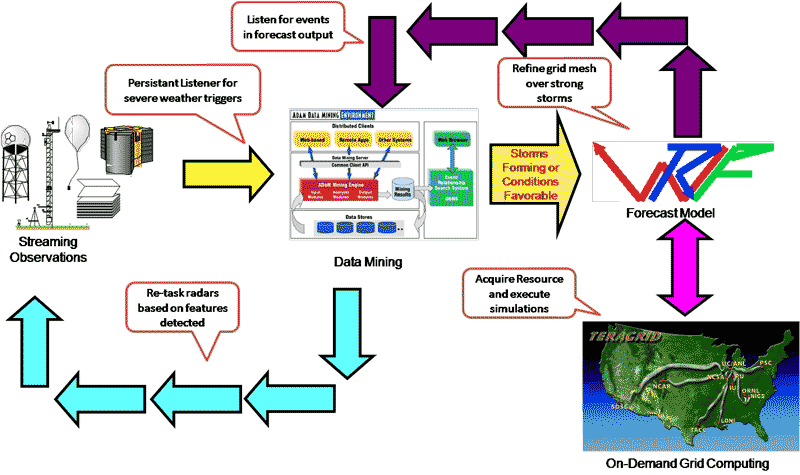
Adaptivity in Use of Computational Resources: Two features of storm prediction computations are critical. First, the prediction must occur before the storm happens. This faster-than-real-time constraint means that very large computational resources must be allocated as predicated by severe weather. If additional computation is needed to resolve potential areas of storm activity, then even more computational power must be allocated. Second, the predictions and assessment of uncertainty in the predictions can benefit from running ensembles of simulation runs that perform identical, or nearly identical, computations but start from slightly different initial conditions. As the simulations evolve, the computations that fail to track the evolving weather could be eliminated, freeing up computational resources. These resources in turn may be used by a simulation instance that needs more power. An evaluation thread must be examining the results from each computation and performing the ensemble analysis needed to gather a prediction. In all cases, the entire collection of available resources must be carefully brokered and adaptively managed to make the predictions work.
Adaptivity in LEAD Cyberinfrastructure: LEAD workflow infrastructure must respond to the dynamic behavior of the computational and grid resources in order to meet the requirement of “faster than real time” prediction. So a timely co-ordination of different components of the Cyberinfrastructure to meet soft, real-time guarantees is required. Co-ordination across the layers to allocate, monitor and adapt in real-time, while meeting strict performance and reliability guarantees and co-allocation of real-time data streams and computational resources, is required.
To summarize, LEAD has enormous demands: large data transfer, real-time data streams, and huge computational needs. But, arguably, most significant is the need to meet strict deadlines. On-demand computations cannot wait in a job queue for Grid resources to become available.
However, neither can the scientific community afford to keep multimillion dollar computational resources idle until required by an emergency. Instead, we must develop technologies that can support urgent computation. Scientists need mechanisms to find, evaluate, select, and launch elevated-priority applications on high-performance computing resources. Such applications might reorder, preempt, or terminate existing jobs in order to access the needed cycles in time.
To this end, LEAD is collaborating with SPRUCE, the Special PRiority and Urgent Computing Environment TeraGrid Science Gateway 12. SPRUCE provides resources quickly and efficiently to high-priority applications that must get computational power without delay.
SPRUCE facilitates urgent computing by addressing five important concepts: session activation, priority policies, participation flexibility, allocation and usage policies, and verification drills.
SPRUCE uses a token-based authorization system for allocation and tracking of urgent sessions. As a raw technology, SPRUCE has no dictated priority policies; resource providers have full control and flexibility to choose possible urgency mechanisms they are comfortable with and to implement these mechanisms as the providers see fit. To build a complete solution for urgent computing, SPRUCE must be combined with allocation and activation policies, local participation policies for each resource, and procedures to support “warm-standby” drills. These application drills not only verify end-to-end correctness but also generate performance and reliability logs that can aid in resource selection.
Many possible authorization mechanisms could be used to let users initiate an urgent computing session, including digital certificates, signed files, proxy authentication, and shared-secret passwords. In time-critical situations, however, simpler is better. Complex digital authentication and authorization schemes could easily become a stumbling block to quick response. Hence, simple transferable tokens were chosen for SPRUCE. This design is based on existing emergency response systems proven in the field, such as the priority telephone access system supported by the U.S. Government Emergency Telecommunications Service in the Department of Homeland Security 13. Users of the priority telephone access system, such as officials at hospitals, fire departments, and 911 centers, carry a wallet-sized card with an authorization number. This number can be used to place high-priority phone calls that jump to the top of the queue for both land- and cell-based traffic even if circuits are completely jammed because of a disaster.

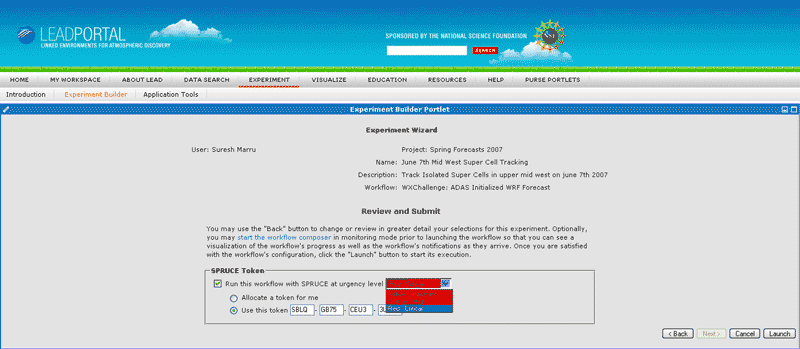
The SPRUCE tokens (see Figure 3) are unique 16-character strings that are issued to scientists who have permission to initiate an urgent computing session. When a token is created, several important attributes are set, such as resource list, maximum urgency, sessions lifetime, expiration date, and project name. A token represents a unique “session” that can include multiple jobs and that lasts for a clearly defined period. It can also be associated with a group of users, who can be added or removed from the token at any time, providing flexible coordination.
The SPRUCE eventflow is designed for application teams that provide computer-aided decision support or instrument control. A principal investigator (PI) organizes each application team and selects the computational “first responders,” senior staff who may initiate an urgent computing session. First responders are responsible for evaluating the situation in light of the policies for using urgent computing.
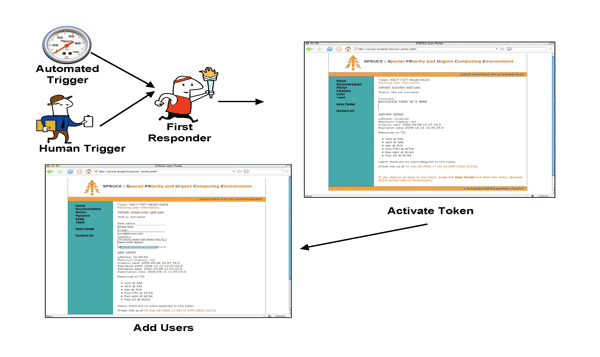
As illustrated in Figure 4, the SPRUCE eventflow begins as the result of a trigger, which may be automatic (e.g., an automated warning from weather advisory RSS feed) or human-generated (e.g., a phone call to the PI). SPRUCE token holders are expected to use tokens with discretion and according to coordinated policies, similar to the way that citizens are expected to use good judgment before dialing 911. Token usage will be monitored and reviewed. Administrators can revoke tokens at any time. The first responder begins interaction with the SPRUCE system by initiating a session. Token activation can be done through a Web-based user portal or via a Web service interface. Systems built from the Web service interface can be automated and incorporated into domain-specific toolsets, avoiding human intervention. The initiator of the SPRUCE session can indicate which scientist or set of scientists will be able to request elevated priority while submitting urgent jobs. This set may later be augmented or edited.
Once a token is activated and the application team has been specified, scientists can organize their computation and submit jobs. Naturally, there is no time to port the application to new platforms or architectures or to try a new compiler. Applications must be prepared for immediate use—they must be in “warm standby.” All of the application development, testing, and tuning must be complete prior to freezing the code and marking it ready for urgent computation. In the same way that emergency equipment, personnel, and procedures are periodically tested for preparedness and flawless operation, SPRUCE proposes to have applications and policies in warm-standby mode, being periodically tested and their date of last validation logged.
From this pool of warm-standby Grid resources, the team must identify where to submit their urgent jobs. One computing facility site may provide only a slightly increased priority to SPRUCE jobs, while another site may kill all the running jobs and allow an extremely urgent computation to use an entire supercomputer. Current job load and data movement requirements can also affect resource selection. Moreover, how a given application performs on each of the computational resources must also be considered. The SPRUCE advisor, currently under development, determines which resources offer the greatest probability to meet the given deadline. To accomplish this task, the advisor considers a wide variety of information, including the deadline, historical information (e.g., warm-standby logs, local site policies), live data (e.g., current network/ queue/resource status), and application-specific data (e.g., the set of warm-standby resources, performance model, input/output data repositories). To determine the likelihood of an urgent computation meeting a deadline on a given resource, the advisor calculates an upper bound on the total turnaround time for the job. More details on this implementation can be found in 14.
Once the resource is chosen based on the advisor, the job is submitted. SPRUCE provides support for both Globus-based urgent submissions and direct submission to local job-queuing systems. Currently SPRUCE supports all the major resource managers such as Torque, LoadLeveler, and LSF and schedulers such as Moab, Maui, PBS Pro, SGE, and Catalina. The system can support any scheduler with little effort. By extending the Resource Specification Language (RSL) of the Globus Toolkit, which is used to identify user-specific resource requests, the ability to indicate a level of urgency for jobs is incorporated. A new “urgency” parameter is defined for three levels: critical (red), high (orange), and important (yellow). These urgency levels are guidelines that help resource providers enable varying site-local response protocols to differentiate potentially competing jobs. Users with valid SPRUCE tokens can simply submit their original Globus submission script with one additional RSL parameter (of the form “urgency =
At the core of the SPRUCE architecture is the invariant that urgent jobs may be submitted only while a right-of-way token is active. In order to support this, a remote authentication step is inserted into the job submission tool-chain for each resource supporting urgent computation. Since the SPRUCE portal contains the updated information regarding active sessions and users permitted to submit urgent jobs, it is also the natural point for authentication. When an urgent computing job is submitted, the urgent priority parameter triggers authentication. This authentication is not related to a user’s access to resource, which has already been handled by the traditional Grid certificate or by logging into the Unix-based resource. Rather, it is a “Mother, may I” request for permission to queue a high-priority job. This request is sent to the SPRUCE portal, where it is checked against active tokens, resource names, maximum priority, and associated users. Permission is granted if an appropriate right-of-way token is active and the job parameters are within the constraints set for the token. All transactions, successful and unsuccessful, are logged.
All of the above works only when the resource providers support a set of urgent computing policy responses corresponding to different levels of requested urgencies. These policies can vary for every site based on comfort level. The SPRUCE architecture does not define or assume any particular policy for how sites respond to urgent computing requests. This approach complicates some usage scenarios, but it is unavoidable given the way we build Grids from distributed resources of independent autonomous centers and given the diversity of resources and operating systems available for computing. The SPRUCE architecture cannot simply standardize the strategy for responding to urgent computation. Instead, we are left with many possible choices for supporting urgent computation depending on the systems software and middleware as well as on constraints based on accounting of CPU cycles, machine usability, and user acceptance. Given the current technology for Linux clusters and more tightly integrated systems such as the Cray XT3 and the IBM Blue Gene, the following responses to an urgent computing request are possible:
Another factor in choosing the response policy is accounting and stakeholder accountability. Certain machines are funded for specific activities, and only a small amount of discretionary time is permitted. Furthermore, in order to improve fairness, some form of compensation (e.g., refunding CPU hours or a one-time higher priority rescheduling) could be provided to jobs that are killed to make room for an urgent job. Another idea is to provide discounted CPU cycles for jobs that are willing to be terminated to make room for urgent computations. In any case, resource providers are encouraged to map all three levels of urgency—critical, high, and important—to clearly defined responses.
The SPRUCE portal provides a single-point of administration and authorization for urgent computing across an entire Grid. It consists of three parts:
Both the user interface and the authentication service communicate with the SPRUCE server via a Web services interface. External portals and workflows can become SPRUCE-enabled simply by incorporating the necessary Web service invocations. Users who prefer to use a Web-based interface can use the SPRUCE user portal. All users may monitor basic statistics such as the remaining lifetime of the token and the tokens with which they are currently associated. These interfaces need minimum additional training, making SPRUCE appropriate for emergency situations.
LEAD applied some of its technology, in real time, for on-demand forecasting of severe weather during the 2007 National Oceanic and Atmospheric Administration (NOAA) Hazardous Weather Test Bed (HWT) 16, which is a multi-institutional program designed to study future analysis and prediction technologies in the context of daily operations. The HWT 2007 spring experiment wes a collaboration among university faculty and students, government scientists, NOAA and private forecasters to further our understanding and use of storm-scale, numerical weather prediction in weather forecasting. LEAD researchers and scientists in coordination with the SPRUCE Urgent Computing team were in a unique position to work with HWT participants to expose this technology to real-time forecasters, students, and research scientists. The 2007 effort addressed two important LEAD-related challenges: (1) the use of storm-resolving ensembles for specifying uncertainty in model initial conditions and quantifying uncertainty in model output, and (2) the application of dynamically adaptive, on-demand forecasts that are created automatically, or by humans, in response to existing or anticipated atmospheric conditions. A key aspect of the spring experiments was that the daily forecasts were evaluated not only by operational forecasters in the NOAA Storm Prediction Center (SPC) but by dozens of faculty and researchers who visited the Hazardous Weather Test Bed in Norman, Oklahoma during the seven-week period. SPC used a formal procedure to evaluate the daily forecasts (additional details may be found in 17).
The LEAD participation in the HWT 2007 spring experiments is described in detail in [18]. Briefly, the effort sought an initial assessment of the following:
LEAD Scientists conducted on-demand, dynamically adaptive forecasts over regions of expected hazardous weather, as determined by severe weather watches and/or mesoscale discussions among scientists and forecasters at the SPC. The LEAD on-demand forecasts began in the first week of May and continued until June 8, 2007. LEAD scientists Drs. Dan Weber and Keith Brewster, interacted directly with the SPC forecasters and HWT participants to obtain the daily model domain location recommendations and launched the daily forecasts using the LEAD Portal. The 9-hour WRF forecasts consisted of 1000 km x 1000 km regions placed in an area of elevated risk of severe weather occurrence during the 1500-0000 UTC forecast period. The on-demand forecasting process depicted in Figure 5 illustrates the forecasters’ interaction with the weather to create a customized forecast process not possible with the current real-time Numrical Weather Prediction NWP scheme.
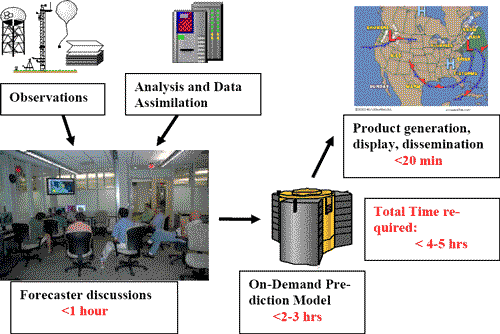
The on-demand forecasts were initialized by using the 15 UTC LEAD ARPS Data Assimilation System ADAS [19] analysis or 3-hour North American Model-NAM forecast initialized at 1200 UTC interpolated to a horizontal grid spacing of 2-km. The ADAS analysis included radar data and other observations to update the 3-hour NAM forecast from the 12 UTC initial time. One advantage to this on-demand forecast system configuration is the potential rapid turnaround for a convective scale forecast using NAM forecasts updated with mid-morning observations. The period selected, from 1500 UTC to 0000 UTC, overlaps with part of the 2007 HWT forecast and verification period for the larger-scale, numerical forecasts using 2 km and 4 km grid spacing.
Each day, one or more six- to nine-hour nested grid forecasts at 2 km grid spacing were launched automatically over regions of expected severe weather, as determined by mesoscale discussions at SPC and/or tornado watches, and one six- to nine-hour nested grid forecast, per day, at 2 km grid spacing was launched manually when and where deemed most appropriate. The production workflows were submitted to the computing resources at the National Center for Supercomputing Applications (NCSA). Because of the load on that machine, including other 2007 HWT computing resource needs, the workflow often waited for several hours in queues, before 80 processors were available to be allocated to the workflow. Moreover, the on-demand forecasts were launched based only on the severity of the weather. If we need a quick turnaround, computing resources have to be pre-reserved and idled, wasting CPU cycles and decreasing the throughput on a busy resource.
In order to tackle this problem, LEAD and SPRUCE researchers collaborated with the University of Chicago/Argonne National Laboratory (UC/ANL) TeraGrid resources to perform real-time, on-demand severe weather modeling. Additionally, the UC/ANL IA64 machine currently supports preemption for urgent jobs with highest priority. As an incentive to use the platform even though jobs may be killed, users are given a 10% discount from the standard CPU service unit billing. Deciding which jobs are preempted is determined by an internal scheduler algorithm that considers several aspects, such as the elapsed time for the existing job, number of nodes, and jobs per user. LEAD was given a limited number of tokens for use throughout the tornado season. The LEAD web portal allows users to configure and run a variety of complex forecast workflows. The user initiates workflows by selecting forecast simulation parameters and a region of the country where severe weather is expected. This selection is done graphically through a “mash-up” of Google maps and the current weather. We deployed SPRUCE directly into the existing LEAD workflow by adding a SPRUCE Web service call and interface to the LEAD portal. Figure 6 shows how LEAD users can simply enter a SPRUCE token at the required urgency level to activate a session and then submit urgent weather simulations.
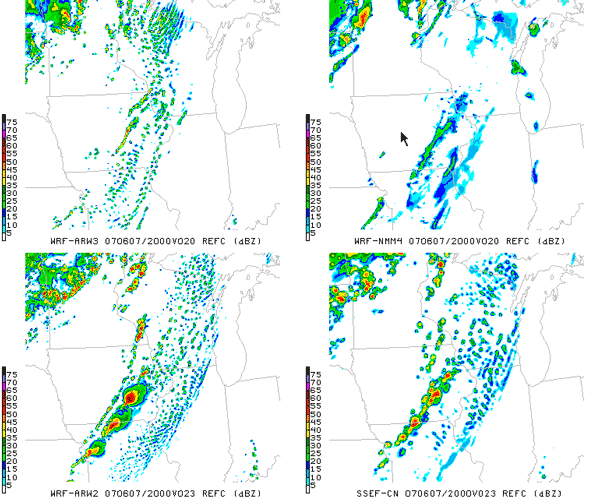
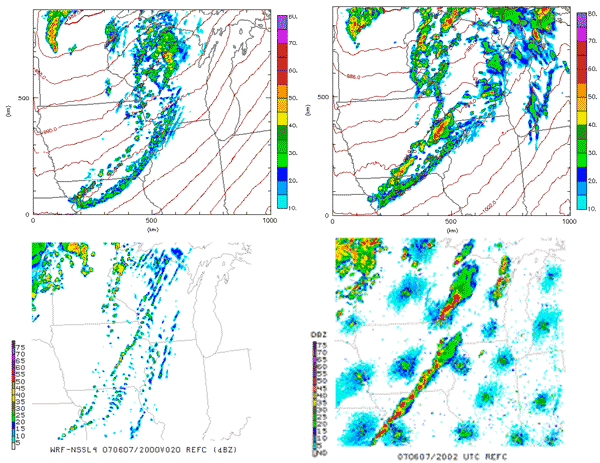
When isolated supercells were detected in upper midwest on June 7th, LEAD developers helped scientists get quick turnaround using SPRUCE critical priority queues on UC/ANL resources, preempting currently running jobs. The scientists subsequently analyzed the forecasts and compared the 20 UTC radar images for the HWT 2 km and 4 km forecasts (Figure 7). The LEAD on-demand shows distinct differences from other HWT numerical predictions (Figure 8) using the previous day’s 21Z SREF data for the ARW2 and ARW4, the resolution and initial condition for the ARW3, and the 15 UTC data and resolution for the LEAD-ADAS urgent computing workflow execution.
Based on a comparison of just the two LEAD forecasts, the ADAS initialized forecast does a better job of handling the main line of convection during the period; in contrast, the NAM-initialized forecast is a little slow in initiating convection on that line in Iowa and produces less intense convection. However, the ADAS-initialized forecast produces some spurious convection early in the run that started in northeast Iowa and quickly moved northeast; the remains of that can be seen in the Upper Peninsula of Michigan at 20 UTC. It is possible that the ADAS analysis resulted in the net convective inhibition being too weak in those areas for this case. At 00 UTC, both LEAD forecasts had a weak secondary boundary to the southeast of the main line running from near Chicago across northern Illinois into northern Missouri. In the ADAS run this appears to be convection on an outflow boundary from the main line, whereas in the NAM-initialized run it seemed to have developed on its own as a weak line. It can be seen from this one example that each method of initialization of the model has its own unique characteristics and it is expected that, in time the best of each can be discerned and an intelligently constructed consensus will produce a superior forecast to what is currently available.
During spring 2007, LEAD cyberinfrastructure integrated with the SPRUCE Urgent Computing tools demonstrated on-demand, dynamically adaptive forecasts —those launched at the discretion of forecasters and over regions of expected hazardous weather as determined by severe weather watches and mesoscale discussions at the NOAA Storm Prediction Center. This collaboration was successful and used preemption capabilities on UC/ANL TeraGrid resources to meet the deadlines for critical runs.
For the 2008 Hazardous Weather Test Bed, we plan to repeat the experiment from 2007, adding 3-6 hours to the length of each on-demand forecasts to cover the evening active thunderstorm period as well as the afternoon. Additionally, we will study the processes by which forecasters determine when and where to (manually) launch on-demand forecasts. We also will continue to evaluate the tradeoffs between varying versus persistent model configurations. We strongly believe that by using urgent computing, the community can test and explore new ways to use applications and resources for critical situations.