

Observing this sort of dramatic increase in failure rates brings up the question of how the utility of future systems will be affected. Fault tolerance in HPC systems is typically implemented with checkpoint restart programming. Here, the application periodically stops useful work to write a checkpoint to disk. In case of a node failure, the application is restarted from the most recent checkpoint and recomputes the lost results.
The time to write a checkpoint depends on the total amount of memory in the system, the fraction of memory the application needs to checkpoint to be able to recover, and the I/O bandwidth. To be conservative, we assume that demanding applications may utilize and checkpoint their entire memory. For a system like Jaguar, with 45TB of memory and 55 GB/s of storage bandwidth, that means one system-wide checkpoint will take on the order of 13 minutes. In a balanced system model, where bandwidth and memory both grow in proportion to compute power, the time to write a checkpoint will stay constant over time. However, with failures becoming more frequent, restarting will be more frequent and application work will be recomputed more frequently. Reducing the time between checkpoints reduces the amount of work recomputed on a restart but it also increases the fraction of each checkpoint interval spent taking a checkpoint.
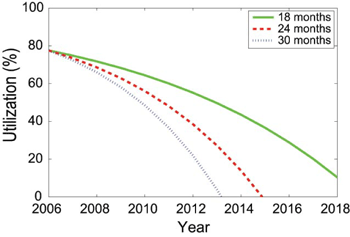
Based on the models of Figure 4 and on an optimal selection of the period between checkpoints,10 Figure 5 shows a prediction that the effective resource utilization by an application will drastically decrease over time. For example, in the case where the number of cores per chip doubles every 30 months, the utilization drops to zero by 2013, meaning the system is spending 100% of its time writing checkpoints or recovering lost work, a situation that is clearly unacceptable. In the next section we consider possible ways to stave off this projected drop in resources utilization.


