In each class, we obtained consent from students to be part of our study. There is a requirement at every U.S. institution that studies involving human subjects must be approved by that university’s Institutional Review Board (IRB). The nature of the assignments was left to the individual instructors for each class since instructors had individual goals for their courses and the courses themselves had different syllabi. However, based on previous discussions as part of this project, many of the instructors used the same assignments (Table 1), and we have been collecting a database of project descriptions as part of our Experiment Manager website (See Section 4). To ensure that the data from the study would not impact students’ grades (and a requirement of almost every IRB), our protocol quarantined the data collected in a class from professors and teaching assistants for that class until final grades had been assigned.
| Embarrassingly parallel: | Buffon-Laplace needle problem, Dense matrix-vector multiply |
| Nearest neighbor: | Game of life, Sharks & fishes, Grid of resistors, Laplace's equation, Quantum dynamics |
| All-to-all: | Sparse matrix-vector multiply, Sparse conjugate gradient, Matrix power via prefix |
| Shared memory: | LU decomposition, Shallow water model, Randomized selection, Breadth-first search |
| Other: | Sorting |
We need to measure the time students spend working on programming assignments with the task that they are working on at that time (e.g., serial coding, parallelization, debugging, tuning). We used three distinct methods: (1) explicit recording by subject in diaries (either paper or web-based); (2) implicit recording by instrumenting the development environment; and (3) sampling by an operating system installed tool (e.g., Hackystat 1). Each of these approaches has strengths and limitations. But significantly, they all give different answers. After conducting a series of tests using variations on these techniques, we settled on a hybrid approach that combines diaries with an instrumented programming environment that captures a time-stamped record of all compiler invocations (including capture of source code), all programs invoked by the subject as a shell command, and interactions with supported editors. Elsewhere 2, we describe the details of how we gather this information and convert it into a record of programmer effort.
After students completed an assignment, the data was transmitted to the University of Maryland, where it was added to our Experiment Manager database. Looking at the database allows post-project analysis to be conducted to study the various hypotheses we have collected via our folklore collection process.
For example, given workflow data from a set of students, the following hypotheses that are the subjective opinion of many in the HPCS community, collected via surveys at several HPCS meetings, can be tested 3:
- Hyp 1: The average time to fix a defect due to race conditions will be longer in a shared memory program compared to a message-passing program. To test this hypothesis we can measure the time to fix defects due to race conditions.
- Hyp. 2: On average, shared memory programs will require less effort than message passing, but the shared memory outliers will be greater than the message passing outliers. To test this hypothesis we measure the total development time.
- Hyp. 3: There will be more students who submit incorrect shared memory programs compared to message-passing programs. To test this hypothesis we can measure the number of students who submit incorrect solutions.
- Hyp. 4: An MPI implementation will require more code than an OpenMP implementation. To test this hypothesis we can measure the size of code for each implementation.
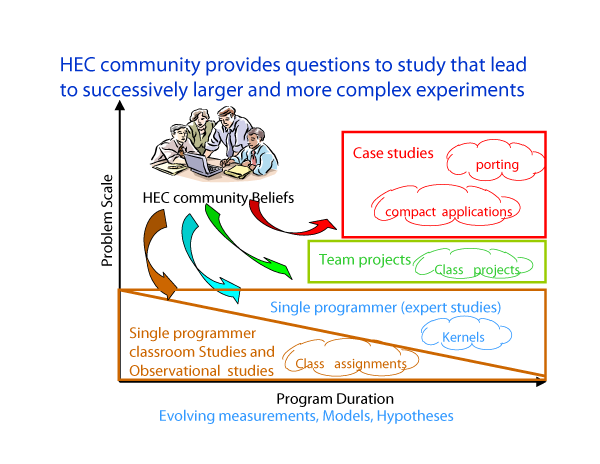
The classroom studies are the first part of a larger series of studies we are conducting (Figure 2). We first run pilot studies with students. We next conduct classroom studies, then move onto controlled studies with experienced programmers, and finally conduct experiments in situ with development teams. Each of these steps contributes to our testing of hypotheses by exploiting the unique aspects of each environment (i.e., replicated experiments in classroom studies and multi-person development with in situ teams). We can also compare our results with recent studies of existing HPC codes 4.