Experiments to Understand HPC Time to Development

November 2006 A
|
Experiments to Understand HPC Time to Development
|
November 2006 A |
Much of the literature in the Software Engineering community concerning programmer productivity was developed with assumptions that do not necessarily hold in the High Performance Computing (HPC) community:
Due to these unique requirements, traditional software engineering approaches for improving productivity may not be directly applicable to the HPC environment.
As a way to understand these differences, we are developing a set of tools and protocols to study programmer productivity in the HPC community. Our initial efforts have been to understand the effort involved and defects made in developing such programs. We also want to develop models of workflows that accurately explain the process that HPC programmers use to build their codes. Issues such as time involved in developing serial and parallel versions of a program, testing and debugging of the code, optimizing the code for a specific parallelization model (e.g., MPI, OpenMP) and tuning for a specific machine architecture are all topics of study. If we have those models, we can then work on the more crucial problems of what tools and techniques better optimize a programmer’s performance to produce quality code more efficiently.
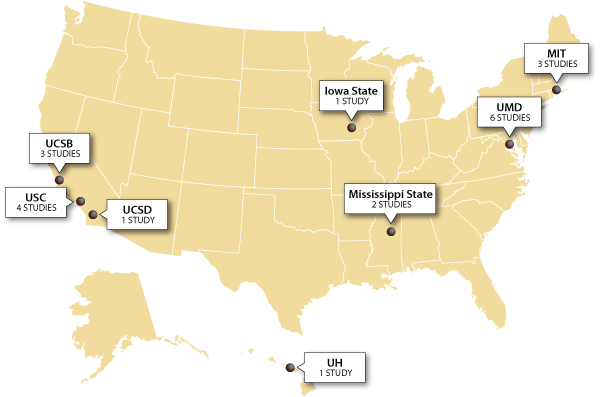
Since 2004 we have been conducting human-subject experiments at various universities across the U.S. in graduate level HPC courses (Figure 1). Graduate students in a HPC class are fairly typical of a large class of novice HPC programmers who may have years of experience in their application domain but very little in HPC-style programming. Multiple students are routinely given the same assignment to perform, and we conduct experiments to control for the skills of specific programmers (e.g., experimental meta-analysis) in different environments. Due to the relatively low costs, student studies are an excellent environment to debug protocols that might be later used on practicing HPC programmers.
Limitations of student studies include the relatively short programming assignments due to the limited time in a semester and the fact these assignments must be picked for the educational value to the students as well as their investigative value to the research team.
In this article, we present both the methodology we have developed to investigate programmer productivity issues in the HPC domain (Section 2), some initial results of studying productivity of novice HPC programmers (Section 3), and current plans for improving the process in the future (Section 4).
In each class, we obtained consent from students to be part of our study. There is a requirement at every U.S. institution that studies involving human subjects must be approved by that university’s Institutional Review Board (IRB). The nature of the assignments was left to the individual instructors for each class since instructors had individual goals for their courses and the courses themselves had different syllabi. However, based on previous discussions as part of this project, many of the instructors used the same assignments (Table 1), and we have been collecting a database of project descriptions as part of our Experiment Manager website (See Section 4). To ensure that the data from the study would not impact students’ grades (and a requirement of almost every IRB), our protocol quarantined the data collected in a class from professors and teaching assistants for that class until final grades had been assigned.
| Embarrassingly parallel: | Buffon-Laplace needle problem, Dense matrix-vector multiply |
| Nearest neighbor: | Game of life, Sharks & fishes, Grid of resistors, Laplace's equation, Quantum dynamics |
| All-to-all: | Sparse matrix-vector multiply, Sparse conjugate gradient, Matrix power via prefix |
| Shared memory: | LU decomposition, Shallow water model, Randomized selection, Breadth-first search |
| Other: | Sorting |
We need to measure the time students spend working on programming assignments with the task that they are working on at that time (e.g., serial coding, parallelization, debugging, tuning). We used three distinct methods: (1) explicit recording by subject in diaries (either paper or web-based); (2) implicit recording by instrumenting the development environment; and (3) sampling by an operating system installed tool (e.g., Hackystat 1). Each of these approaches has strengths and limitations. But significantly, they all give different answers. After conducting a series of tests using variations on these techniques, we settled on a hybrid approach that combines diaries with an instrumented programming environment that captures a time-stamped record of all compiler invocations (including capture of source code), all programs invoked by the subject as a shell command, and interactions with supported editors. Elsewhere 2, we describe the details of how we gather this information and convert it into a record of programmer effort.
After students completed an assignment, the data was transmitted to the University of Maryland, where it was added to our Experiment Manager database. Looking at the database allows post-project analysis to be conducted to study the various hypotheses we have collected via our folklore collection process.
For example, given workflow data from a set of students, the following hypotheses that are the subjective opinion of many in the HPCS community, collected via surveys at several HPCS meetings, can be tested 3:
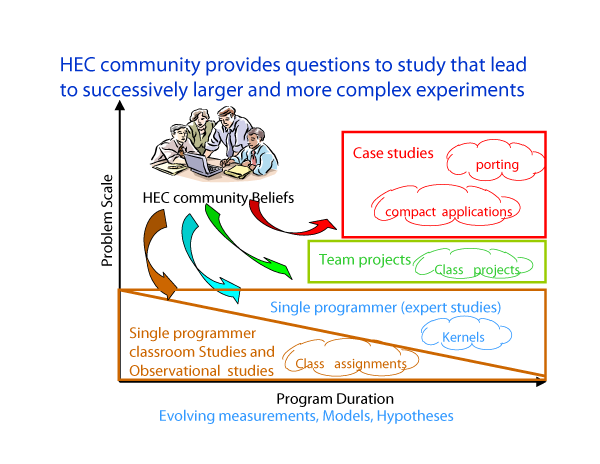
The classroom studies are the first part of a larger series of studies we are conducting (Figure 2). We first run pilot studies with students. We next conduct classroom studies, then move onto controlled studies with experienced programmers, and finally conduct experiments in situ with development teams. Each of these steps contributes to our testing of hypotheses by exploiting the unique aspects of each environment (i.e., replicated experiments in classroom studies and multi-person development with in situ teams). We can also compare our results with recent studies of existing HPC codes 4.
As part of our effort to understand development issues, our classroom experiments have moved beyond effort analysis and have started to look at the impact of defects (e.g., incorrect or excessive synchronization, incorrect data decomposition) on the development process. By understanding how, when, and the kind of defects that appear in HPC codes, tools and techniques can be developed to mitigate these risks to improve the overall workflow. As we have shown 2, automatically determining workflow is not precise, so we are working on a mixture of process activity (e.g., coding, compiling, executing) with source code analysis techniques. The process of defect analysis we are building consists of the following main activities:
Analysis:
For example, a small increase in source code, following a failed execution and following a large code insertion, could represent the pattern of the programming adding new functionality, followed by a test and then defect correction. Syntactic tools that find specific defects can be used to aid the human-based heuristic search for defects.
Verification:
We then need to analyze these results at various levels. Verification consists of the following steps, among others:
Nakamura, et al. explore this defect methodology in greater detail. 5
Early results needed to validate our process were to verify that students could indeed produce good HPC codes and that we could measure their increased performance. Table 2 is one set of data that shows that students achieved speedups of approximately three to seven on an 8-processor HPC machine. CxAy means class number x, assignment number y. This coding was used to preserve anonymity of the student population.
| Data set | Programming Model | Speedup on 8 processors |
| Speedup measured relative to serial version: | ||
| C1A1 | MPI | mean 4.74, sd 1.97, n=2 |
| C3A3 | MPI | mean 2.8, sd 1.9, n=3 |
| C3A3 | OpenMP | mean 6.7, sd 9.1, n=2 |
| Speedup measured relative to parallel version run on 1 processor: | ||
| C0A1 | MPI | mean 5.0, sd 2.1, n=13 |
| C1A1 | MPI | mean 4.8, sd 2.0, n=3 |
| C3A3 | MPI | mean 5.6, sd 2.5, n=5 |
| C3A3 | OpenMP | mean 5.7, sd 3.0, n=4 |
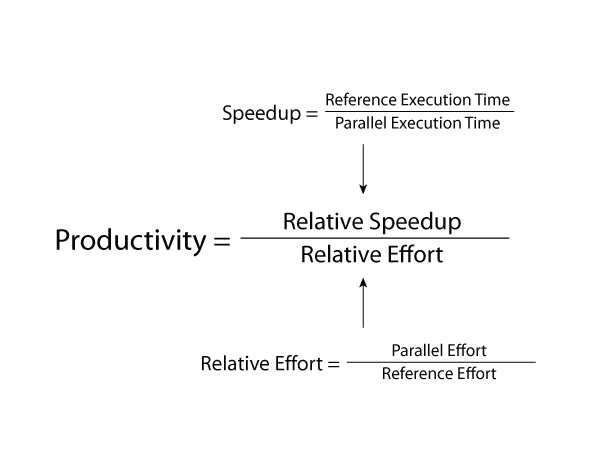
Additional classroom results include the following:
| Program → | 1 | 2* | 3 | 4 | 5 |
| Serial effort (hrs) | 3 | 7 | 5 | 15 | |
| Total effort (hrs) | 16 | 29 | 10 | 34.5 | 22 |
| Serial Exec (sec) | 123.2 | 75.2 | 101.5 | 80.1 | 31.1 |
| Parallel Exec (sec) | 47.7 | 15.8 | 12.8 | 11.2 | 8.5 |
| Speedup | 1.58 | 4.76 | 5.87 | 6.71 | 8.90 |
| Relative Effort | 2.29 | 4.14 | 1.43 | 4.93 | 3.14 |
| Productivity | 0.69 | 1.15 | 4.11 | 1.36 | 2.83 |
| *- Reference serial implementation | |||||
Table 3 shows the results for one group of students programming the Game of Life (a simple nearest neighbor cellular automaton problem where the next generation of “life” depends upon surrounding cells in a grid and a popular first parallel program for HPC classes) 8. The data shows that our definition of productivity had a negative correlation compared to both total effort and HPC execution time, and a positive correlation compared to relative speedup. While the sample size is too small for a test of significance, the relationships all indicate that productivity does behave as we would want a productivity measure to behave for HPC programs, i.e., good productivity means lower total effort, lower HPC execution time and higher speedup.
| Serial | MPI | OpenMP | Co-Array Fortran | StarP | XMT | |
| Nearest-Neighbor Type Problems | ||||||
| Game of Life | C3A3 | C3A3 C0A1 C1A1 |
C3A3 | |||
| Grid of Resistors | C2A2 | C2A2 | C2A2 | C2A2 | ||
| Sharks & Fishes | C6A2 | C6A2 | C6A2 | |||
| Laplace’s Eq. | C2A3 | C2A3 | ||||
| SWIM | C0A2 | |||||
| Broadcast Type Problems |
||||||
| LU Decomposition | C4A1 | |||||
| Parallel Mat-vec | C3A4 | |||||
| Quantum Dynamics | C7A1 | |||||
| Embarrassingly Parallel Type Problems | ||||||
| Buffon-Laplace Needle | C2A1 C3A1 |
C2A1 C3A1 |
C2A1 C3A1 |
|||
| Other | ||||||
| Parallel Sorting | C3A2 | C3A2 | C3A2 | |||
| Array Compaction | C5A1 | |||||
| Randomized Selection | C5A2 | |||||
Table 4 shows the distribution of programming assignments across different programming models for the first seven classes (using the same CxAy coding used in Table 2). Multiple instances of the same programming assignment lend the results to meta-analysis to be able to consider larger populations of students 2.
| Dataset | Programming Model | Application | Lines of Code |
| C3A3 | Serial | Game of Life | mean 175, sd 88, n=10 |
| MPI | mean 433, sd 486, n=13 | ||
| OpenMP | mean 292, sd 383, n=14 | ||
| C2A2 | Serial | Resistors | 42 (given) |
| MPI | mean 174, sd 75, n=9 | ||
| OpenMP | mean 49, sd 3.2, n=10 |
For example, we can use this data to partially answer an earlier stated hypothesis (Hyp. 4: An MPI implementation will require more code than an OpenMP implementation). Table 5 shows the relevant data giving credibility to this hypothesis (but this early data is not statistically significant yet).

In a pilot study at the University of Hawaii in Spring of 2006, students worked on the Gauss-Seidel iteration problem using C and PThreads in a development environment that included automated collection of editing, testing, and command line data using Hackystat. We were able to automatically infer the "serial coding" workflow state as the editing of a file not containing any parallel constructs (such as MPI, OpenMP, or PThread calls), and the "parallel coding" workflow state as the editing of a file containing these constructs. We were also able to automatically infer the "testing" state as the occurrence of unit test invocation using the CUTest tool. In our pilot study, we were not able to automatically infer the debugging or optimization workflow states, as students were not provided with tools to support either of these activities that we could instrument.
Our analysis of these results leads us to conclude that workflow inference may be possible in an HPC context. We hypothesize that it may actually be easier to infer these kinds of workflow states in a professional setting, since more sophisticated tool support is often available that can help support inferencing regarding the intent of a development activity. Our analyses also cause us to question whether the five states that we initially selected are appropriate for all HPC development contexts. It may be that there is no "one size fits all" set of workflow states, and that we will need to define a custom set of states for different HPC organizations in order to achieve our goals.
Additional early classroom results are given in Hochstein, et al. 11.
As stated earlier, we have collected effort data from student developments and begun to collect data from professional HPC programmers in three ways; manually from the participants, automatically from timestamps at each system command, and automatically via the Hackystat tool, sampling the active task at regular intervals. All three methods provide different values for “effort,” and we developed models to integrate and filter each method to provide an accurate picture of effort.
Our collection methods evolved one at a time. To simplify the process of students (and other HPC professionals) providing needed information, we developed an experiment management package (Experiment Manager) to more easily collect and analyze this data during the development process. It includes effort, defect and workflow data, as well as copies of every source program during development. Tracking effort and defects should provide a good data set for building models of productivity and reliability of HEC codes.
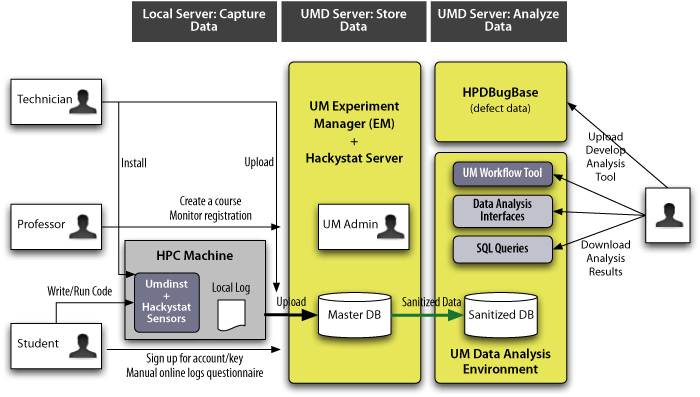
The Experiment Manager (pictured in Figure 5) has three components:
For the near future, our efforts will focus on the following tasks:
Over the past three years we have been developing a methodology for running HPC experiments in a classroom setting and obtaining results we believe are applicable to HPC programming in general. We are starting to look at larger developments and at large university and government HPC projects in order to increase the confidence on the early results we have obtained with students.
Our development of the Experiment Manager system allows us to more easily expand our capabilities in this area. This allows many others to run such experiments on their own in a way that allows for the appropriate controls of the experiment so that results across classes and organization at geographically diverse locations can be compared in order to get a thorough understanding of the HPC development model.