

| Name | Generation | Computation | Communication | Verification | Per-processor data |
| HPL | n2 | n3 | n2 | n2 | p-1 |
| DGEMM | n2 | n3 | n2 | 1 | p-1 |
| STREAM | m | m | 1 | m | p-1 |
| PTRANS | n2 | n2 | n2 | n2 | p-1 |
| RandomAccess | m | m | m | m | p-1 |
| FFT | m | mlog2m | m | mlog2m | p-1 |
| b_eff | 1 | 1 | p2 | 1 | 1 |
There are a number of issues to be considered for benchmarks such as HPCC that have scalable input data to allow for an arbitrary sized system to be properly stressed by the benchmark run. Time to run the entire suite is a major concern for institutions with limited resource allocation budgets. Each component of HPCC has been analyzed from the scalability standpoint and Table 2 shows the major time complexity results. In following, it is assumed that:
- M is the total size of memory,
- m is the size of the test vector,
- n is the size of the test matrix,
- p is the number of processors,
- t is the time to run the test.
Clearly any complexity formula that grows faster than linearly with respect to any of the system sizes is a cause of potential problem time scalability issue. Consequently, the following tests have to be addressed:
- HPL because it has computational complexity O(n3).
- DGEMM because it has computational complexity O(n3).
- b_eff because it has communication complexity O(p2).
The computational complexity of HPL of order O(n3) may cause excessive running time because the time will grow proportionately to a high power of total memory size:
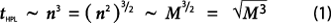
To resolve this problem, we have turned to the past TOP500 data and analyzed the ratio of Rpeak to the number of bytes for the factorized matrix for the first entry on all the lists. It turns out that there are on average 6±3 Gflop/s for each matrix byte. We can thus conclude that the performance rate of HPL remains constant over time (rHPL ~ M), which leads to:
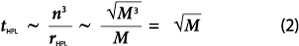
that is much better than (1).
There seems to be a similar problem with the DGEMM as it has the same computational complexity as HPL but fortunately, the n in the formula related to a single process memory size rather than the global one and thus there is no scaling problem.
Lastly, the b_eff test has a different type of problem: its communication complexity is O(p2) which is already prohibitive today as the number of processes of the largest system in the HPCC database is 131072. This complexity comes from the ping-pong component of b_eff that attempts to find the weakest link between all nodes and thus, theoretically, needs to look at the possible process pairs. The problem was remedied in the reference implementation by adapting the runtime of the test to the size of the system tested.


