

 Figure 5. Sample kiviat diagram of results for three different interconnects that connect the same processors.
|
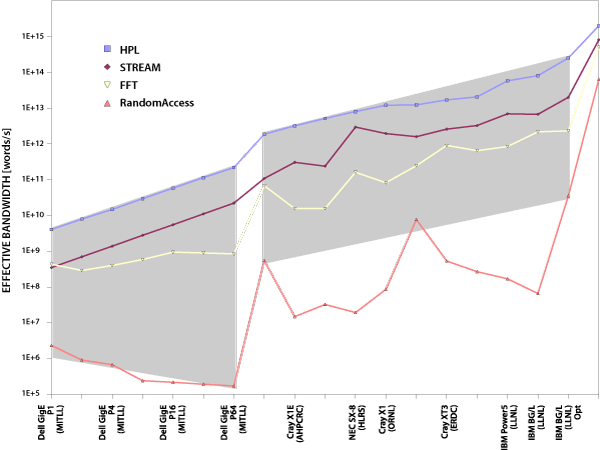 Figure 6. Sample interpretation of the HPCC results.
|
The reference implementation of the benchmark may be obtained free of charge at the benchmark's web site 11. The reference implementation should be used for the base run: it is written in portable subset of ANSI C 12 using hybrid programming model that mixes OpenMP 13 14 threading with MPI 15 16 17 messaging. The installation of the software requires creating a script file for Unix's make(1) utility. The distribution archive comes with script files for many common computer architectures. Usually, few changes to one of these files will produce the script file for a given platform. The HPCC rules allow only standard system compilers and libraries to be used through their supported and documented interface and the build procedure should be described at submission time. This ensures repeatability of the results and serves as an educational tool for end users that wish to use the similar build process for their applications.
After, a successful compilation the benchmark is ready to run. However, it is recommended that changes be made to the benchmark's input file that describes the sizes of data to use during the run. The sizes should reflect the available memory on the system and the number of processors available for computations.
There must be one baseline run submitted for each computer system entered in the archive. There may also exist an optimized run for each computer system. The baseline run should use the reference implementation of HPCC and, in a sense, it represents the scenario when an application requires use of legacy code - a code that can not be changed. The optimized run allows developers to perform more aggressive optimizations and use system-specific programming techniques (e.g., languages, messaging libraries, etc.) but at the same time still gives the verification process enjoyed by the base run.
All of the submitted results are publicly available after they have been confirmed by email. In addition to the various displays of results and raw data export the HPCC website also offers a kiviat chart display to visually compare systems using multiple performance numbers at once. A sample chart that uses actual HPCC results' data is shown in Figure 5.
Figure 6 show performance results of currently operating clusters and supercomputer installations. Most of the results come from the HPCC public database.


