

Why should the high-performance computing community even care about (low) power consumption? The reasons are at least two-fold: (1) efficiency, particularly with respect to cost, and (2) reliability.
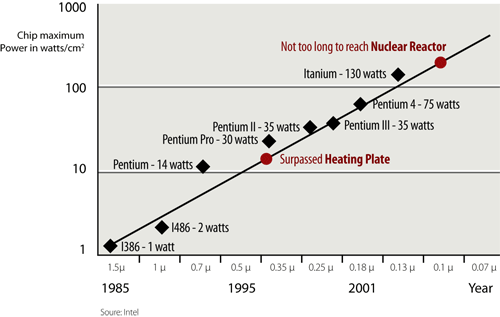
For decades, we have focused on performance, performance, and occasionally, price/performance, as evidenced by the Top500 Supercomputer List1 as well as the Gordon Bell Awards for Performance and Price/Performance at SC.2 So, to achieve better performance per compute node, microprocessor vendors have not only doubled the number of transistors (and speed) every 18-24 months, but they have also doubled the power densities, as shown in Figure 1. Consequently, keeping a large-scale high-performance computing (HPC) system functioning properly requires continual cooling in a large machine room, or even a new building, thus resulting in substantial operational costs. For instance, given that the cooling bill alone at Lawrence Livermore National Laboratory (LLNL) is $6M/year and given that for every watt (W) of power consumed by an HPC system at LLNL, 0.7 W of cooling is needed to dissipate the power; the annual cost to both power and cool HPC systems at LLNL amounts to a total of $14.6M per year, and this does not even include the costs of acquisition, integration, upgrading, and maintenance.3 Furthermore, when nodes consume and dissipate more power, they must be spaced out and aggressively cooled; otherwise, such power causes the temperature of a system to increase rapidly enough that for every 10º C increase in temperature, the failure rate doubles, as per Arrhenius’ equation as applied to microelectronics.4
Our own informal empirical data from late 2000 to early 2002 indirectly supports Arrenhius’ equation. In the winter, when the temperature inside our warehouse-based work environment at Los Alamos National Laboratory (LANL) hovered around 21-23º C, our 128-CPU Beowulf cluster — Little Blue Penguin (LBP) — failed approximately once per week. In contrast, the LBP cluster failed roughly twice per week in the summer when the temperature in the warehouse reached 30-32º C. Such failures led to expensive operational and maintenance costs relative to technical staff working to fix the failures and the cost of replacement parts. Furthermore, there is the lost productivity of technical staff due to the failures.
Perhaps more disconcerting is how our warehouse environment affected the results of the Linpack benchmark when running on a dense Beowulf cluster back in 2002: The cluster produced an answer outside the residual (i.e., a silent error) after only ten minutes of execution. Yet when the same cluster was placed in an 18-19º C machine-cooled room, it produced the correct answer. This experience loosely corroborated a prediction made by Graham, et al — “In the near future, soft errors will occur not just in memory but also in logic circuits.”5
Power (and its affect on reliability) is even more of an issue for larger-scale HPC systems, such as those shown in Table 1. Despite having exotic cooling facilities in place, the reliability of these large-scale HPC systems is measured in hours,6 and in all cases, the leading source of outage is hardware, with the cause often being attributed to excessive heat. Consequently, as noted by Eric Schmidt, CEO of Google, what matters most to Google “is not speed but power — low power, because data centers can consume as much electricity as a city.”7 That is, though speed is important, power consumption (and hence, reliability) is more so. By analogy, what Google, and arguably application scientists in HPC, desires is the fuel-efficient, highly reliable, low-maintenance Toyota Camry of supercomputing, not the Formula One race car of supercomputing with its energy inefficiency, unreliability, and exorbitant operational and maintenance costs. In addition, extrapolating today’s failure rates to an HPC system with 100,000 processors suggests that such a system would “spend most of its time checkpointing and restarting. Worse yet, since many failures are heat related, the [failure] rates are likely to increase as processors consume more power.”5
| System | CPUs | Reliability |
|---|---|---|
| ASCI Q | 8,192 | MTBI: 6.5 hours. Leading outage sources: storage, CPU, memory. |
| ASCI White | 8,192 | MTBF: 5.0 hours ('01) and 40 hours ('03). Leading outage sources: storage, CPU, 3rd-party HW. |
| PSC Lemieux | 3,016 | MTBI: 9.7 hours. |
MTBI: mean time between interrupts = wall clock hours / # downtime periods, MTBF: mean time between failures (measured)


