In the FT-LA project we have selected to investigate Algorithm Based Fault Tolerance (ABFT), which has many advantages: it does not rely on checkpoints, and it fits well with most of the standard BLAS3 kernels such as Matrix- Matrix multiplication or LU/QR decomposition. In this approach, the original matrices are preconditioned to generate a set of larger matrices including floating point redundancy data. Then, the application is spawned on more resources and the problem is solved with the usual algorithm on the redundant matrix (the above figure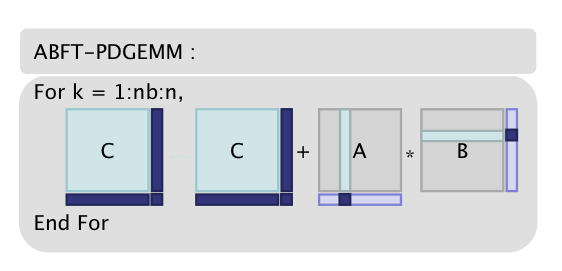 illustrate this concept for the example of a matrix multiplication).
illustrate this concept for the example of a matrix multiplication).
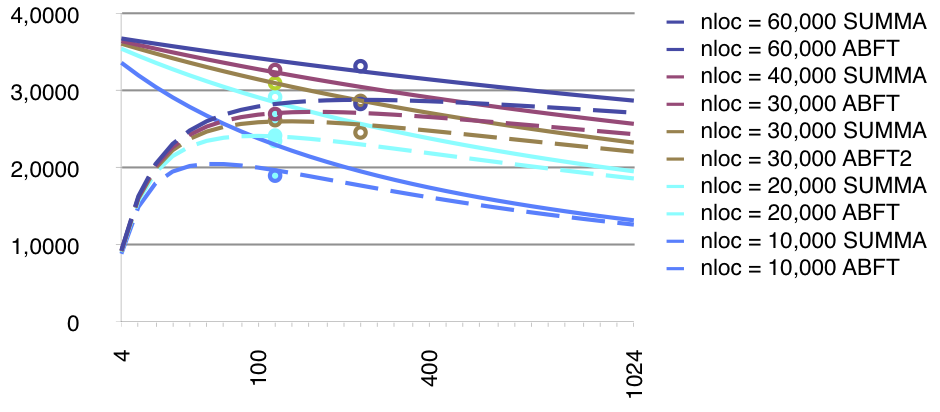
Should some failure occurs, the missing information can be rebuilt by applying a reduction on the data set stored on surviving processes. As the fault tolerant algorithm is similar to the original one, applied to a slightly larger data set, and as the recovery procedure can be expressed with a single reduction, the overall scalability is very good. The major drawback appears during the recovery: the reduction operation used to regenerate the lost processes data applies on floating point data. When the matrices are ill-conditioned, the numerical stability of the recovery can be poor, though generally this is not an issue. Once the data have been reconstructed, it is possible for the algorithm to weight the lost accuracy compared to a failure free run. As outlined by the above figure depicting performance of the summa algorithm with a growing number of processes, early performance results are very promising. The ABFT approach used in FT-LA is the only fault tolerant strategy benefiting from strong scalability. The more processors are used, the smaller is the fault tolerance overhead.


The prototype implementation we designed this year is based on the FT-MPI library, developed at the University of Tennessee, which aims at providing a consistent MPI environment to the application after a failure. Unlike MPI implementations strictly following the standard, in FT-MPI the communicators and internal data structures are not left in a random, unusable state after a failure hits another process. Instead, several recovery policies are available for the application to select from, including shrinking the communicator size to the now available number of processes, setting the failed process ranks as “blanks” allowing for the remaining processes to exclude the failed processes from subsequent communications, or replacing the missing processes with new incarnations. Using this tool, several fault tolerant linear algebra kernels have been designed, namely dgemm (summa and pumma algorithms), dgemv, dlacpy, dnrm2 and dnrm2mat. Using this library we could then develop a fault tolerant matrix-matrix multiply application to demonstrate its operation.


