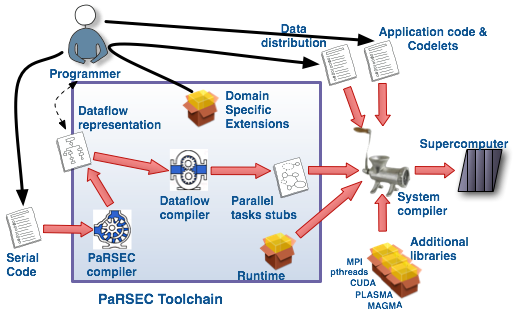
From a high-level standpoint the scheduler in PaRSEC is divided in two parts. One is generic, handling the placement of ready tasks into the actual scheduling infrastructure. The second is generated by the pre-compiler and is algorithm dependent. This part uses the knowledge discovered by the pre-compiler during the JDF analysis, and encapsulates properties of the algorithm itself (such as priorities, tasks ordering and the critical path). As described previously, in PaRSEC, the scheduler is partly in the library and partly in the opaque object compiled from the JDF representation. Internally, PaRSEC creates a thread per core on the local machine and binds them on each core. Each thread runs its own version of the scheduler, alternating between times when it runs the body of the task, and times when it executes the local scheduler to find a new task to run. As a consequence, the scheduling is not only distributed between the nodes, it is also distributed between the cores.
To improve locality and data reuse on NUMA architectures, the schedule function (part of the PaRSEC library) favors the queuing of the new enabled tasks in the local queue of the calling thread. A task that is en-queued in this queue has a greater chance to be executed on the same core, maximizing cache and memory locality. If the thread-local queue is full, the tasks are put on a single node-local waiting-queue. When a task is completed, an epilogue, compiled from the JDF and found in the opaque object, is executed to compute which tasks are now enabled, and the thread looks up the next task to run. The most recently added task in the local queue is chosen; if no such task is found, the thread first tries to pop from the queues of the other threads and then from the node queue, following an order that maps the physical hierarchy of the cores on the node. The PaRSEC environment uses the HWLOC library to discover the architecture of the machine at run time and to define the work stealing strategy. The JDF representation, including both the generated code and the dynamic data structures, are specifically tailored to handle DAGs that enable simultaneously a large number of dependencies.

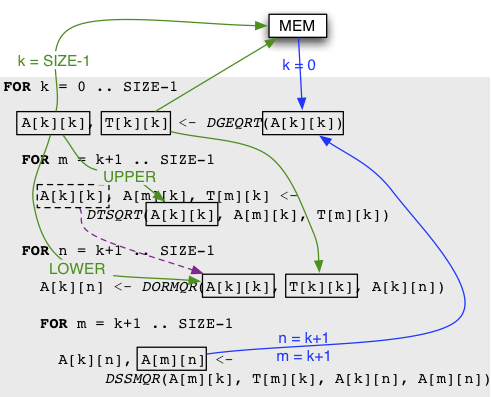
DAG of QR for a 4x4 tiles matrix on a 2x2 grid of processors
The Figure above represents the complete unrolling of the Tile QR JDF for SIZE = 4, on a 2 × 2 process grid. Plain arrows represent communications, and dotted arrows data that is passed from one task to another on the same computing node. The bold arrows represent the life cycle of the data pointed by V in the DGEQRT(0) task, that is sent to DTSQRT(0, 1), then continues towards DTSQRT(0, 2), and finishes in DTSQRT(0, 3).
As illustrated by the figure, in addition to tracking dependencies, PaRSEC needs to track data flows between tasks. When a task is completed, the epilogue stores pointers to each of the data produced by the task in a structure shared between the threads. When a new task is to be scheduled, the pointers corresponding to all local variables are retrieved from this shared structure, and assigned to the local variables, before the task is executed. When all tasks depending on a particular data are completed, the engine stops tracking this data, and releases all internal resources associated with it.
At the end of the epilogue, the thread has noted, using the binding between tasks and data in the JDF, which tasks, if any, will execute remotely, and which data from the completed task they require. The epilogue ends with a call to the Asynchronous Communication Engine to trigger the emission of the output data to the requesting nodes. The Asynchronous Communication Engine is implemented as a separate thread (one per node) that serves the data exchange needs of the tasks. A producer/consumer approach is taken: the orders are pushed into a queue, and the communication engine will serve them as soon as possible.
Task completions which enable remote tasks (by satisfying their dependencies) are signified from one communication engine to the others using small control messages containing the reference of the completed task. When a communication engine learns that a remote task has completed, it computes which local tasks this enables, and sends, when possible, a control message to receive the corresponding data, following a pull protocol.
In PaRSEC, communications are implicitly inferred from the data dependencies between tasks, according to the binding between tasks and data, as defined in the JDF. Asynchrony and dynamic scheduling are key concepts of PaRSEC, meaning that the communication engine has also to exhibit the same properties in order to effectively achieve communication/computation overlap and asynchronous progress of tasks in a distributed environment.
As a consequence, in PaRSEC, all communications are handled by a separate communication thread which unlike the computation threads is not bound to any specific core. This decision has been made in order to decrease the potential load imbalance between the work imposed on the cores. By not imposing a binding on the communication thread, we give the opportunity to the operating system to move the communication thread to an idle core, or to migrate it regularly between the cores. For portability and efficiency reasons, the communication infrastructure is implemented using asynchronous point-to-point MPI communications.