|
|
The Direct Acyclic Graph Environment |
DAGuE consists of a runtime engine and a set of tools to build, analyze, and pre-compile a compact representation of a DAG. The internal representation of Direct Acyclic Graphs used by DAGuE is called JDF. It expresses the different types of tasks of an application and their data dependencies.
The DAGuE library includes the runtime environment that consists of a distributed multi-level dynamic scheduler, an asynchronous communication engine and a data dependencies engine. The user is responsible for expressing the task distribution in the JDF (helping the H2J tool to translate the original sequential code in a distributed version), and distributing and initializing the orig- inal input data accordingly. The runtime environment is then re- sponsible for finding an efficient scheduling of the tasks, detecting remote dependencies and automatically moving data between dis- tributed resources. |
Converting Sequential Code to a DAG representation |
Most applications can be described as a sequential SMPSS-like code, as shown in the figure below. This sequential representation can be automatically translated in the JDF representation (described in the sections below) using our tool, H2J, which is based on the integer programming framework Omega-Test. The JDF representation of a DAG is then precompiled as C-code by our framework and linked in the final binary program, with the DAGuE library.

Sequential code of the Tile-QR Factorization. Typical input for the H2J conversion tool.
The H2J tool computes the symbolic analysis of the data flows, and transforms this in our internal representation of the DAG, called the JDF. An example of the analysis done on the QR factorization algorithm above is represented below, for the DGEQRT task:
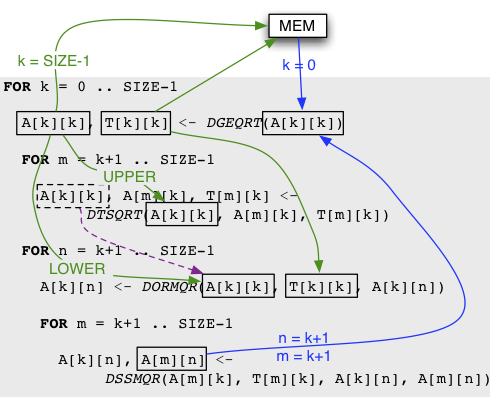
Analysis of the data flows for the DGEQRT task of the QR Factorization. |
The DAG representation: the JDF format |
The JDF is the compact representation of DAGs in DAGuE; a language used to describe the DAGs of tasks in a synthetic and concise way. A realistic example of JDF, for the QR factorization of the Figure above is given below:


JDF representation of the QR Factorization
To explain the behavior of the DAGuE runtime environment on this internal representation, let us look closely at the task DGEQRT. It takes a single input variable: V. After modifying V, DGEQRT sends it to memory and to other tasks, and produces an output variable, T, to be sent to memory and to another task. V is the name of the variable that represents A(k, k) in the QR Sequential code, and T is the name of the variable that represents T(k,k). Each of the blue dependencies of this figure translates as an input dependency for V, while each of the green dependencies translates as an output dependency for V or T. V can come either from memory (local to the node on which the task executes or located in a remote node), or from the output C2 of the task DSSMQR(k-1, k, k). One might notice that for output dependencies, the language supports ranges of tasks as targets for a data.
Each dependency line may end with a type qualifier between braces (e.g. lines 5 to 9). As seen in the sequential code, for the QR operation, the dependencies of lines 5 and 6 represent different dependencies applying to two different parts of the same tile (A(k, k)). This type qualifier provides a way for the application developer to specify which part of the tile is involved in each dependency. Dependencies on T (lines 8 and 9) also require a type qualifier, because the communication engine needs to know that T is not a regular tile of doubles.
The JDF representation requires that all dependencies are expressed symmetrically as an output dependency for a task, and an input for another. Most users don't need to consider this themselves, since the H2J tool translates a sequential code into a correct JDF representation. At run time, the compiled opaque object from the JDF keeps a symbolic representation of the task system on each node. The runtime represents single tasks only by their name and parameter values, without unrolling (or traversing) the whole DAG in memory at any time, or requiring any communication. Operations like evaluating if this task is to be executed locally, or on a remote node, or computing the descending and ascending tasks of any given task, are done locally, by computing the context of the task from this symbolic representation. |
DAG Scheduling in DAGuE |
From a high-level standpoint the scheduler in DAGuE is divided in two parts. One is generic, handling the placement of ready tasks into the actual scheduling infrastructure. The second is generated by the pre-compiler and is algorithm dependent. This part uses the knowledge discovered by the pre-compiler during the JDF analysis, and encapsulates properties of the algorithm itself (such as priorities, tasks ordering and the critical path). As described previously, in DAGuE, the scheduler is partly in the library and partly in the opaque object compiled from the JDF representation. Internally, DAGuE creates a thread per core on the local machine and binds them on each core. Each thread runs its own version of the scheduler, alternating between times when it runs the body of the task, and times when it executes the local scheduler to find a new task to run. As a consequence, the scheduling is not only distributed between the nodes, it is also distributed between the cores.
To improve locality and data reuse on NUMA architectures, the schedule function (part of the DAGuE library) favors the queuing of the new enabled tasks in the local queue of the calling thread. A task that is en-queued in this queue has a greater chance to be executed on the same core, maximizing cache and memory locality. If the thread-local queue is full, the tasks are put on a single node-local waiting-queue. When a task is completed, an epilogue, compiled from the JDF and found in the opaque object, is executed to compute which tasks are now enabled, and the thread looks up the next task to run. The most recently added task in the local queue is chosen; if no such task is found, the thread first tries to pop from the queues of the other threads and then from the node queue, following an order that maps the physical hierarchy of the cores on the node. The DAGuE environment uses the HWLOC library to discover the architecture of the machine at run time and to define the work stealing strategy. The JDF representation, including both the generated code and the dynamic data structures, are specifically tailored to handle DAGs that enable simultaneously a large number of dependencies.
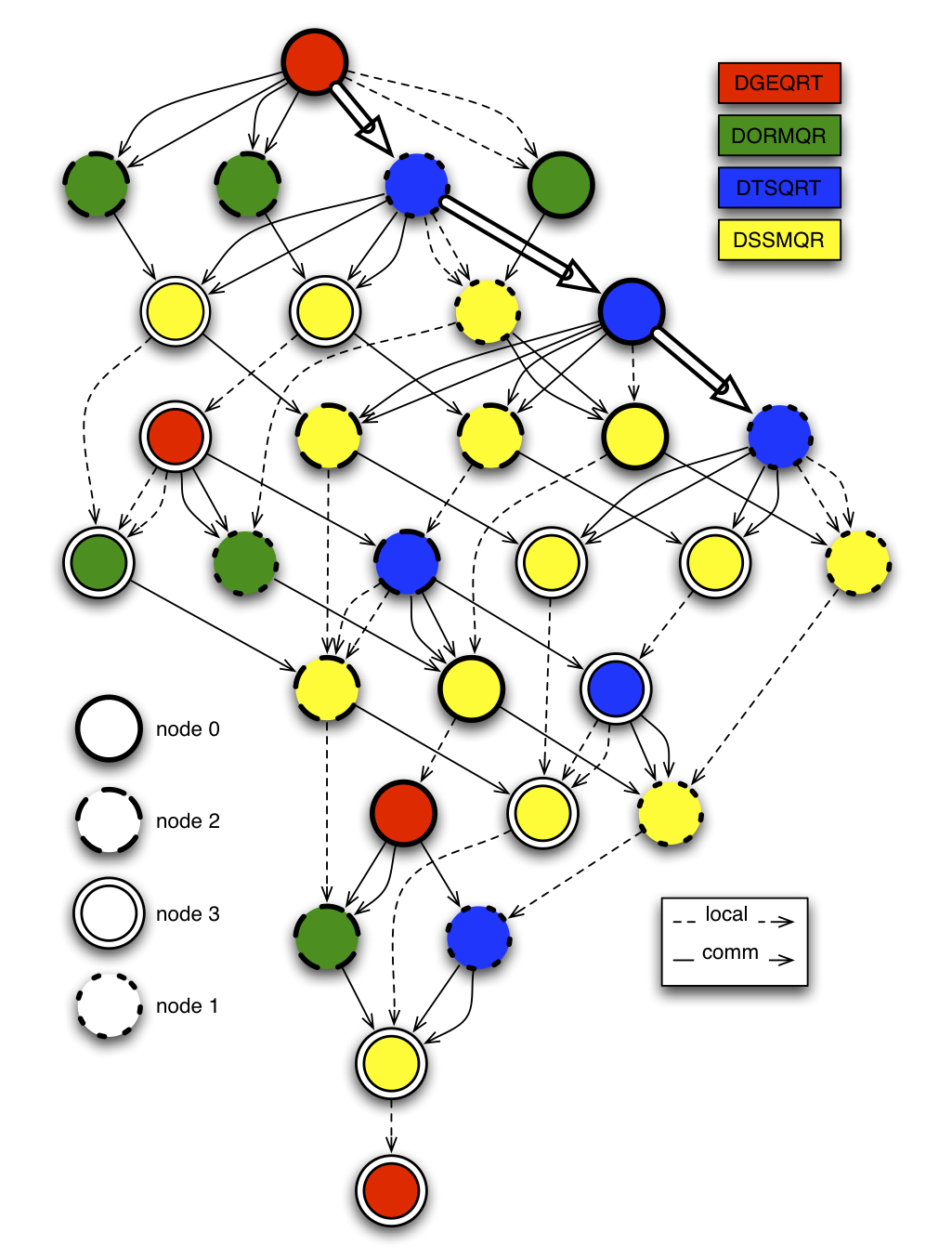
DAG of QR for a 4x4 tiles matrix on a 2x2 grid of processors
The Figure above represents the complete unrolling of the Tile QR JDF for SIZE = 4, on a 2 × 2 process grid. Plain arrows represent communications, and dotted arrows data that is passed from one task to another on the same computing node. The bold arrows represent the life cycle of the data pointed by V in the DGEQRT(0) task, that is sent to DTSQRT(0, 1), then continues towards DTSQRT(0, 2), and finishes in DTSQRT(0, 3).
As illustrated by the figure, in addition to tracking dependencies, DAGuE needs to track data flows between tasks. When a task is completed, the epilogue stores pointers to each of the data produced by the task in a structure shared between the threads. When a new task is to be scheduled, the pointers corresponding to all local variables are retrieved from this shared structure, and assigned to the local variables, before the task is executed. When all tasks depending on a particular data are completed, the engine stops tracking this data, and releases all internal resources associated with it.
At the end of the epilogue, the thread has noted, using the binding between tasks and data in the JDF, which tasks, if any, will execute remotely, and which data from the completed task they require. The epilogue ends with a call to the Asynchronous Communication Engine to trigger the emission of the output data to the requesting nodes. The Asynchronous Communication Engine is implemented as a separate thread (one per node) that serves the data exchange needs of the tasks. A producer/consumer approach is taken: the orders are pushed into a queue, and the communication engine will serve them as soon as possible.
Task completions which enable remote tasks (by satisfying their dependencies) are signified from one communication engine to the others using small control messages containing the reference of the completed task. When a communication engine learns that a remote task has completed, it computes which local tasks this enables, and sends, when possible, a control message to receive the corresponding data, following a pull protocol.
In DAGuE, communications are implicitly inferred from the data dependencies between tasks, according to the binding between tasks and data, as defined in the JDF. Asynchrony and dynamic scheduling are key concepts of DAGuE, meaning that the communication engine has also to exhibit the same properties in order to effectively achieve communication/computation overlap and asynchronous progress of tasks in a distributed environment.
As a consequence, in DAGuE, all communications are handled by a separate communication thread which unlike the computation threads is not bound to any specific core. This decision has been made in order to decrease the potential load imbalance between the work imposed on the cores. By not imposing a binding on the communication thread, we give the opportunity to the operating system to move the communication thread to an idle core, or to migrate it regularly between the cores. For portability and efficiency reasons, the communication infrastructure is implemented using asynchronous point-to-point MPI communications. |
DAGuE Performance Evaluation |
Here are some of the performances obtained using DAGuE for three well known dense matrix factorizations: Cholesky, QR, and LU. These evaluations were done on the Griffon cluster of the Grid'5000 experimental grid. It is a 646 cores machine composed of 81 dual socket Intel Xeon L5420 quad core processors at 2.5GHz with 16GB of memory, interconnected by a 20Gb/s Infiniband network.
We compare the performances of the DAGuE based factorizations with three other implementations. ScaLAPACK is the reference implementation for distributed parallel machines of some of the LAPACK routines. We used the vendor ScaLAPACK and BLAS implementations (from MKL-10.1.0.015). DSBP (version 2008-10-28) is a tailored implementation of the Cholesky factorization using 1) a tiled algorithm, 2) a specific data representation suited for Cholesky, and 3) a static scheduling engine. HPL is considered the state of the art implementation of an LU factorization. It is used as the prominent metric in the evaluation of the performance level of the most powerful machines in the world issued by the Top 500. The algorithm and programming paradigm are very similar to the ScaLAPACK version of the LU factorization, but extremely tuned.

Problem Scaling of the Cholesky, QR and LU Factorizations
We ran the different factorizations on the Griffon platform, with 81 nodes (648 cores), and for a varying problem size (from 13, 600 × 13, 600 to 130, 000 × 130, 000). We took the best block size value for each of the reference implementations. When the problem size increases, the total amount of computation increases as the cube of the size, while the total amount of data increases as the square of the size. For a fixed tile size, this also means that the number of tiles in the matrix increases with the square of the matrix size, and so does the number of tasks to schedule. Therefore, the global performance of each benchmark increases until a plateau is reached. On the Griffon platform, the amount of available memory was not sufficient to reach the plateau with neither of the implementations, except for the DAGuE QR. On the entire range of benchmarks and problem sizes, DAGuE outperforms the non-multi-core aware ScaLAPACK. This advantage is more pronounced for smaller problem sizes, although the lower amount of parallelism due to the smaller number of tiles makes it more difficult to harness the performance of the machine.
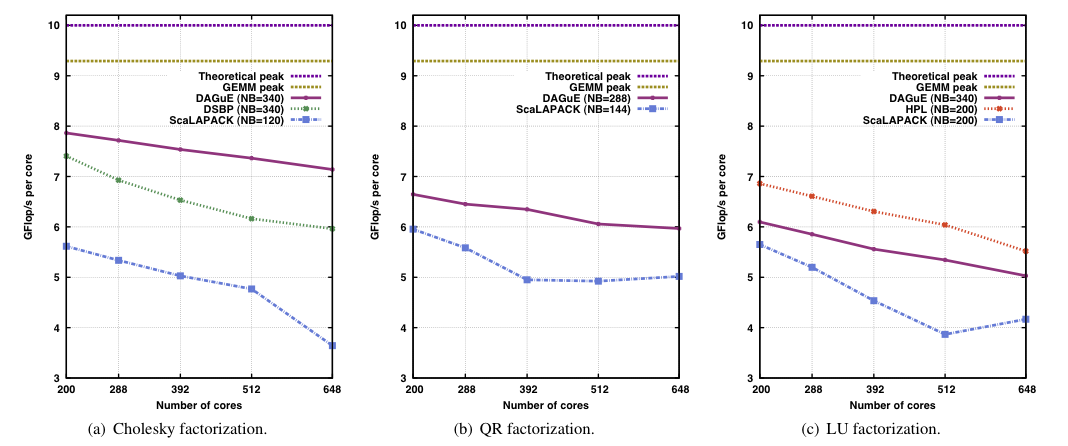
Strong Scalability, varying the number of nodes for N=93,500
We used the largest available matrix size for the smallest number of nodes (93, 500 × 93, 500) and the most efficient block size after tuning (340 × 340). Because the same ma- trix is distributed on an increasing number of nodes, the ratio between computations and communications decreases with the number of nodes, which leads to a decline in the efficiency per core of the benchmarks. On the Cholesky factorization, ScaLAPACK seems to suffer more from this effect, as it is unable to continue scaling after 512 cores for this matrix size. On the QR and LU benchmarks, because ScaLAPACK does not fully utilize the computing power of the nodes, the rate at which messages are pushed trough the network is lower, which in turn results in a smaller overall network utilization. Because the network contention is not as severe, it can scale almost linearly on QR between 312 and 648 cores. For the other benchmarks (DAGuE, DSBP and HPL), because they harness more efficiency from each local core, the higher execution rate also incurs more pressure on the network. This drives the network congestion to be the major factor hindering strong scalability.
Overall, the rate at which the performance decreases when more compute nodes are involved is smaller for DAGuE than for DSBP and HPL: In the case of Cholesky, DSBP suffers from a 20% per core performance degradation between 200 and 648 cores, compared to a 9.5% penalty for DAGuE. Similarly, in the case of LU, HPL exhibits a 18% decreased core efficiency between 200 and 648 cores, while DAGuE performance is hit by only 16%. This illustrates that DAGuE benefits from a slightly better strong scalability. |
Project Handouts
|

