The Many-Core Inflection Point for Mass Market Computer Systems

February 2007
|
The Many-Core Inflection Point for Mass Market Computer Systems
|
February 2007 |
Major changes in the commercial computer software industry are often caused by significant shifts in hardware technology. These changes are often foreshadowed by hardware and software technology originating from high performance, scientific computing research. Innovation and advancement in both communities have been fueled by the relentless, exponential improvement in the capability of computer hardware over the last 40 years and much of that improvement (keenly observed by Gordon Moore and widely known as "Moore's Law") was the ability to double the number of microelectronic devices that could be crammed onto a constant area of silicon (at a nearly constant cost) every two years or so. Further, virtually every analytical technique from the scientific community (operations research, data mining, machine learning, compression and encoding, signal analysis, imaging, mapping, simulation of complex physical and biological systems, cryptography) has become widely deployed, broadly benefiting education, health care and entertainment as well as enabling the world-wide delivery of cheap, effective and profitable services from eBay to Google.
In stark contrast to the scientific community, commercial application software programmers have not, until recently, had to grapple with massively concurrent computer hardware. While Moore's law continues to be a reliable predictor of the aggregate computing power that will be available to commercial software, we can expect very little improvement in serial performance of general purpose CPUs. So if we are to continue to enjoy improvements in software capability at the rate we have become accustomed to, we must use parallel computing. This will have a profound effect on commercial software development including the languages, compilers, operating systems, and software development tools, which will in turn have an equally profound effect on computer and computational scientists.
Power dissipation in clocked digital devices is proportional to the clock frequency, imposing a natural limit on clock rates. While compensating scaling has enabled commercial CPUs to increase clock speed by a factor of 4,000 in the last 10 years, the ability of manufacturers to dissipate heat has reached a physical limit. Leakage power dissipation gets worse as gates get smaller, because gate dielectric thicknesses must proportionately decrease. As a result, a significant increase in clock speed without heroic (and expensive) cooling is not possible. Chips would simply melt. This is the "Power Wall" confronting serial performance, and our back is firmly against it: Significant clock-frequency increases will not come without heroic measures, or materials technology breakthroughs.
Not only does clock speed appear to be limited, but memory performance improvement increasingly lags behind processor performance improvement. This introduces a problematic and growing memory latency barrier to computer performance improvements. To try to improve the "average memory reference" time to fetch or write instructions or data, current architectures have ever growing caches. Cache misses are expensive, causing delays of hundreds of (CPU) clock cycles. The mismatch in memory speed presents a "Memory Wall" for increased serial performance.
In addition to the performance improvements that have arisen from frequency scaling, hardware engineers have also improved performance, on average, by having duplicate hardware speculatively execute future instructions before the results of current instructions are known, while providing hardware safeguards to prevent the errors that might be caused by out of order execution.1 Unfortunately, branches must be "guessed" to decide what instructions to execute simultaneously (if you guess wrong, you throw away this part of the result) and data dependencies may prevent successive instructions from executing in parallel, even if there are no branches. This is called Instruction Level Parallelism (ILP). A big benefit of ILP is that existing programs enjoy performance benefits without any modification. But ILP improvements are difficult to forecast since the "speculation" success is difficult to predict, and ILP causes a super-linear increase in execution unit complexity (and associated power consumption) without linear speedup. Serial performance acceleration using ILP has also stalled because of these effects.2 This is the "ILP Wall."
David Patterson of Berkeley has a formulaic summary of the serial performance problem: "The power wall + the memory wall + the ILP wall = a brick wall for serial performance." Thus, the heroic line of development followed by materials scientists and computer designers to increase serial performance now yields diminishing returns. Computer architects have been forced to turn to parallel architectures to continue to make progress. Parallelism can be exploited by adding more independent CPUs, data-parallel execution units, additional registers sets (hardware threads), more independent memory controllers to increase memory bandwidth (this requires more output pins) and bigger caches. Computer architects can also consider incorporating different execution units, which dramatically improve some computations but not others (e.g., GPU like units that excel at structured data parallelism and streaming execution units with local memory as Cray did in many of its early machines3). Heterogeneity need not only mean completely different "abstract" execution unit models but may include incorporating computation engines with the same instruction set architecture, but different performance and power consumption characteristics. All of these take advantage of dramatically higher on-chip interconnect data rates.
Moore's law will grant computer architects ever more gates for the foreseeable future, and the challenge is to use them to deliver performance and power characteristics fit for their intended purpose. Figure 1 below illustrates a few hardware design choices. In 1(a), a client configuration might consist of two large "out of order" cores (OoC) incorporating all the ILP of current processors to run existing programs together with many smaller "in-order" cores (IoC) for programs that can take advantage of highly parallel software. Why many IoCs rather than correspondingly fewer of the larger OoCs? The reason is that spending gates on out-of order has poorer performance returns than simpler in-order cores, if parallel software can scale with cores. The server configuration in 1(b) incorporates many more IoCs and a "custom" core (say a crypto processor). Finally, multi-core computers are not just beneficial for raw performance but also reliability and power management so embedded processors will also undergo an architecture shift as illustrated in 1(c).

While the foregoing hardware architecture offers much more computing power, it makes writing software that can fully benefit from the hardware potentially much harder.
In scientific applications, improved performance has historically been achieved by having highly trained specialists modify existing programs to run efficiently as new hardware was provided.4 In fact, even re-writing existing programs in this environment was far too costly, and most organizations focused the specialists on rewriting small portions of the "mission critical" programs, called kernels. In the "good case," the mission critical applications spent 80 or 90% of their time in these kernels and the kernels represented a few percent of the application code. Thus making a kernel ten times faster could mean a nearly ten-fold performance improvement. Even so, this rewriting was time consuming, and organizations had to balance the risk of introducing subtle bugs into well tested programs against the benefit of increased speed at every significant hardware upgrade. All bets were off if the organization did not have the source code for the critical components.
By contrast, commercial vendors, thanks to the chip manufacturers who managed to rapidly improve the serial performance while maintaining the same hardware instruction set architecture, have been habituated to a world where all existing programs get faster with each new hardware generation. Further, software developers could confidently build new innovative software, which barely ran on then current hardware, knowing that it would run quite well on the next generation machine at the same cost. This will no longer occur for serial codes, but the goal of new software development tools must be to retain this very desirable characteristic as we move into the era of many-core computing. If we are successful, then building your software with these new tools and then faster hardware (or even just adding more hardware) will improve performance without further application programmer intervention.
In order to benefit from rapidly improving computer performance (and we all want that) and to retain the "write one, run faster on new hardware" paradigm, commercial software and scientific software must change their software development and system support.5 To achieve this, software development systems and supporting software must enable a significant portion of the programming community to construct parallel applications. There are several complementary approaches that may help us achieve this.
However, to fully exploit parallelism, programmers must understand a parallel execution model, develop parallel algorithms, and be equipped with much better tools to develop, test and automatically tune performance. This requires education as well as software innovation. Compilers, which bridge between intent-oriented features and the underlying execution model of the system, must incorporate idioms to explicitly identify parallel tasks as well as optimization techniques to identify and schedule implicitly parallel tasks discovered by it.7 Program analysis and testing are hard enough for sequential programs and are much harder in parallel programming. We must find mechanisms that contain concurrency and isolate threads and use those to make testing more robust. We have seen dramatic improvements in static analysis tools that identify software defects, reduce test burden and improve reliability. These techniques are being extended to incorporate identification of concurrency problems. Debuggers must evolve from the low-level machine model back to a more common and familiar model that a developer can reason about correctly and effectively. Finally, the need for tools for performance analysis to help identify bottlenecks will become crucial as we face the possibility of two orders of magnitude difference between optimized and naïve algorithms.
Many-core computers are more like "data-centers-on-a-chip" than traditional computers. System software will change to effectively manage resources on these systems while decomposing and rationalizing the system software function to provide more reliability and manageability. General purpose computer operating systems (which have not fundamentally changed since system and application software separated with the advent of "time shared" computers in the 1950's) will change as much as development tools.
To understand why, consider the following. Supercomputing applications are typically assigned dedicated system wide resources for each application run. This allows applications to tune algorithms to available resources: knowledge of the actual CPU resources available to the application at runtime, as well as memory, can drastically improve a sophisticated application's performance (database systems do a good job of this right now and too so often avoid, or out and out deceive, current operating systems to control real resources). By contrast, most commercial operating systems "time multiplex" the hardware resources8 to provide good utilization of expensive resources and anticipate that an application will run on a fairly narrow spectrum of architectures. Older operating systems also suffer from service, program and device isolation models, which are no longer appropriate but made perfect sense given earlier assumptions:
Many core operating systems will incorporate a hypervisor, a small and very reliable component that hosts many different operating systems (or copies of the same OS with different performance or security characteristics). Hypervisors perform the relatively slowly change in "space sharing" of resources. For example, a hypervisor might simultaneously dedicate a core for long periods of time to a multimedia OS partition/application combination and assign I/O devices to it, host an older, buggier version of an OS for compatibility, host a tightly controlled corporate partition, host a game partition requiring strong performance guarantees, and host a loosely controlled partition for web browsing on the same hardware. Each partition can be sure of both performance and security isolation, and one partition need not incur the performance, fragility or security characteristics of another.
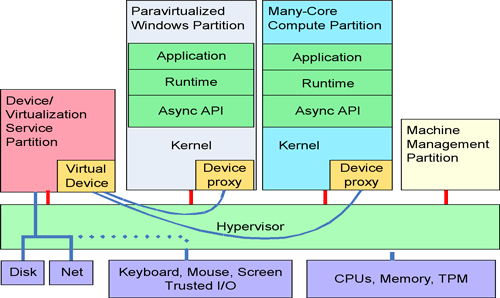
A many-core system stack (hypervisor, OS kernel, user mode run-time) must effectively assign resources securely and host concurrent operating environments. Machine-wide and OS health (root-kit detection, OS stuck), power management and coarse hardware resource allocation can be managed centrally while insulating partitions from harmful effects of other partitions. As with other software decomposition strategies, this simplifies software construction. Coarse partitioning also provides a good way to get coarse parallelism. Applications running concurrently in separate trust domains need the benefits of either rich operating environments or specialized environments that provide specific guarantees (such as real time scheduling). This also provides a vehicle to stage new facilities while retaining legacy environments unmodified. Each OS partition can exercise finer resource control over the resources it controls in conjunction with its application mix. Within a process, the application and supporting runtime can exert very fine grain control over resources in conjunction with the OS. Further, the OS must include a better asynchronous "system API" and lightweight native threads. Finally, the system stack must manage heterogeneous hardware; general purpose cores, GPUs, vector units and special cores such as encryption or compression.
Can people user this much computing power? Yes.9 The ultimate application mix is hard to forecast (applications that need this level of computing don't, by definition, exist, and the application specialists will not invest the effort required until they see some hardware). Again, we can speculate.
It is uncontroversial that servers (including home servers) will also benefit from many-core computing, and this will also boost the need for powerful clients. With cheap and ubiquitous sensors and natural language processing, we can anticipate environment aware, multi-media (vision, speech, gesture, object recognition, etc.) input and output human computer interfaces that "learn" user behaviors and offer suggestions or possibly automatically manage some tasks for users.
Better data mining and modeling will provide business intelligence and targeted customer service. Automated medical imaging, diagnosis and well being monitoring will be commonplace. High-level tools like MATLAB or Excel, designed for parallelism, will take advantage of increased power and delegate processing across the network, provided the right workflow tools are integrated.
With terabyte disks, these systems will make superb media library, capture, edit, and playback systems. Film fans can purchase, download, and view protected feature films on opening day. Most printed material and other media can be replaced with electronic versions, accessed via a broadband connection, with vastly improved search and cross reference capabilities. These machines can make virtual reality and realistic games, well, real. Not only entertainment but education will benefit.
Today's corporate servers will shrink to a few racks and become highly resilient to failure. State check pointing and load balancing will improve performance and reliability. Damage from catastrophic failures is limited to a few seconds of downtime and rollback. Provisioning, deploying, and administering these servers and applications are simplified and automated.
Massively parallel computational grids built of commodity hardware already solve scientific problems like computational chemistry, protein folding and drug design. "Supercomputers" already analyze nuclear events and water tables and predict the climate and the economy. The power of these systems and the reach of these techniques will vastly improve with new hardware, and scientists will have supercomputers under their desks. By the way, scientific, financial and medical "supercomputing" are no longer "small" business opportunities. More than 10% of servers are used in scientific applications.
Classic computational techniques (known in the scientific community as the "seven dwarves"10 – including equation solvers, adaptive mesh modeling, etc.) will help explore regimes that will change our lives.11 Already, Microsoft researchers and world class scientists are using advanced computational techniques to explore potential cures for Aids and cancer, model Hydrologic activity in agriculturally sensitive regions, perform seismic modeling and run virtual laboratories for advanced physics. As in the past, use by scientists will help illuminate the path for the rest of us.
Programmable systems are playing an increasingly large part in our lives and, in many ways, provide a world-wide "paradigm shift" comparable to the appearance of cheap, mass market printing in scope and benefit. Many-core computers signal a shift in Computer Science, Computational Science, and classical Commercial Software that (as in all good technology shifts) marry the past advances of many "knowledge workers" as well as provide a new avenue for qualitatively new advances.