Symbolic Performance Modeling of HPCS Applications

November 2006 B
|
Symbolic Performance Modeling of HPCS Applications
|
November 2006 B |
Performance and workload modeling have numerous uses at every stage of the high-end computing lifecycle: design, integration, procurement, installation, tuning, and maintenance. Despite the tremendous usefulness of performance models, their construction remains largely a manual, complex, and time-consuming exercise. Many of these techniques serve the overall purpose of modeling but few common techniques have gained widespread acceptance across the community. In most cases, researchers create models by manually interrogating applications with an array of performance, debugging, and static analysis tools to refine the model iteratively until the predictions fall within expectations. In other cases, researchers start with an algorithm description, and develop the performance model directly from this abstract description. In particular, DARPA’s High Productivity Computing Systems (HPCS) program requires understanding and predicting application requirements almost eight years in advance, when prototype hardware and perhaps even system simulators do not exist. In this light, performance modeling takes on a critical importance because system architects must make choices that match application workloads while DARPA and its HPCS mission partners must set aggressive but realistic goals for performance.
In this article, we describe a new approach to performance model construction, called modeling assertions (MA), which borrows advantages from both the empirical and analytical modeling techniques1 2. This strategy has many advantages over traditional methods: isomorphism with the application structure; easy incremental validation of the model with empirical data; uncomplicated sensitivity analysis; and straightforward error bounding on individual model terms. We demonstrate the use of MA by designing a prototype framework, which allows construction, validation, and analysis of models of parallel applications written in FORTRAN and C with the MPI communication library. We use the prototype to construct models of NAS CG, SP benchmarks3 and a production level scientific application called Parallel Ocean Program (POP).4
A further advantage of our approach is that the MA symbolic models encapsulate an application’s key input parameters as well as the workload parameters, including the computation and the communication characteristics of the modeled applications. The MA scheme requires an application developer to describe the workload requirements of a given block of code using the MA API in the form of code annotations. These code annotations are independent of the target platforms. Moreover, the MA scheme allows multi-resolution modeling of scientific applications. In other words, a user can decide which functions are critical to a given application and can annotate and subsequently develop detailed performance models of the key functions. Depending on the runtime accuracy of the model, a user can develop hierarchical, multi-resolution performance models of selected functions, for instance, models of critical loop blocks within a time-consuming function. MA models can capture the control structure of an application. Thus, not only an aggregated workload metric is generated, but also the distribution of a given workload over an entire execution cycle can be modeled using the MA framework.
The outline of the paper is as follows: the motivation behind the modeling assertion technique is presented in section 2. Section 3 explains the components of the Modeling Assertions framework. Section 4 describes model construction and validation using the NAS CG benchmarks. Section 5 presents the scalability of the NAS CG and SP benchmarks and POP communication behavior together with an analysis of sensitivity of workload requirements. Section 6 concludes with benefits and contributions of the modeling assertions approach to performance modeling studies.
In order to evaluate our approach of developing symbolic models with MA, we have designed a prototype framework. This framework has two main components: a library for instrumenting applications and a post-processing toolset. Figure 1 shows the components of the MA framework. The MA API is used to annotate the source code. As the application executes, the runtime system captures important information in trace files. These trace files are then post-processed to validate, analyze, and construct models. The post-processor currently has three main classes; model validation, control-flow model creation, and symbolic model generation classes. The symbolic model shown in the Figure 1 is generated for the MPI send volume. This symbolic model can be evaluated, and is compatible, with MATLAB5 and Octave.6

Currently, MA can be used to model computation and communication of applications. The MA API provides a set of functions to annotate a given FORTRAN or C code that uses MPI message-passing for communication. For example, ma_loop_start, a MA API function, can be used to mark the start of a loop. Upon execution, the code instrumented with MA API functions generates trace files. For parallel applications, one trace file is generated for each MPI task. The trace files contain traces for ma_xxx calls and MPI communication events. Most MA calls require a pair of ma_xxx_start and a ma_xxx_end calls. The ma_xxx_end traces are primarily used to validate the modeling assertions against the runtime values. In our current implementation, the assertions for the number of floating-point operations, ma_flop_start/stop, invoke the PAPI hardware counter API7 to collect empirical data and compare it to the prediction. The ma_mpi_xxx assertions on the other hand are validated by implementing MPI wrapper functions (PMPI) and by comparing ma_mpi_xxx traces to PMPI_xxx traces. Additional functions are provided in the MA API to control the tracing activity; for example, to control the size of the trace files, by enabling and disabling the tracing at both compile and run time. At runtime, the MA runtime system (MARS) tracks and captures the actual instantiated values as they execute in the application. MARS creates an internal control flow representation of the calls to the MA library as they are executed. It also captures both the symbolic values and the actual values of the expressions. Multiple calls to the same routines with similar parameters is projected onto the same call graph, therefore, the data volume is reduced.
As a motivating example, we demonstrate MA on the NAS CG benchmark. NAS CG computes an approximation to the smallest eigenvalue of a large, sparse, symmetric positive definite matrix, which is characteristic of unstructured grid computations. The main subroutine is conj_grad, which is called niter times. The benchmark results report time in seconds for the time step (do it = 1, niter) loop that is shown in Figure 2. Hence, we started constructing the model in the main program, starting from the conj_loop, as shown is Figure 2. The first step was to identify the key input parameters, na, nonzer, niter and nprocs (number of MPI tasks). Then, using ma_def_variable_assign_int function, we declared the essential derived values, which are later used in the MA annotations to simplify the model representation. Figure 2 only shows the MA annotations as applied to the NAS CG main loop. It does not show the annotations in the conj_grad subroutine, which are similar except for additional ma_subroutine_start and ma_subroutine_end calls. The annotations shown in Figure 2 capture the overall flow of the application at different levels in the hierarchy; loops (e.g., conj_loop, mpi), subroutines (e.g., conj_grad), basic loop blocks, etc. These annotations also define variables (e.g., na, nonzer, niter, nprocs), which are important to the user in terms of quantities that determine the problem resolution and its workload requirements. At the lowest level is the norm_loop as shown in Figure 2. The ma_loop_start and ma_loop_end annotations specify that the enclosed loop executes a number of iterations (e.g., l2npcols) with a typical number of MPI send and receive operations. More specifically, the ma_loop_start routine captures an annotation name (i.e., l2npcols = log2(num_proc_cols)), a symbolic expression that defines the number of iterations in terms of an earlier defined MA variable (i.e., num_proc_cols).
call maf_def_variable_int(’na’,na)
call maf_def_variable_assign_int (’num_proc_cols’,
’2ˆceil(log(nprocs)/(2*log(2)))’, num_proc_cols)
call maf_def_variable_assign_int( ’l2npcols’
call maf_loop_start(’conj_loop’, ’niter’, niter)
do it = 1, niter
call conj_grad ( colidx, reduce_recv_lengths )........
call maf_loop_start(’norm_loop’, ’l2npcols’, l2npcols)
do i = 1, l2npcols
call maf_mpi_irecv(’nrecv’,’dp*2’, dp*2,1)
call mpi_irecv( norm_temp2, 2, dp_type ........
call maf_loop_end(’norm_loop’,i-1)
The validation of an MA performance model is a two-stage process. When a model is initially being created, validation plays an important role in guiding the resolution of the model at various phases in the application. Later, the same model and validation technique can be used to validate against historical data and across the parameter space. The model verification output enables us to identify the most floating-point intensive loop block of the code in the CG benchmark. This loop block is shown in Figure 3, which is called twice during a conjugate gradient calculation in the CG benchmark. The symbolic floating point operation cost of the loop is approximately 2*na/(num_proc_cols*nonzer*ceiling(nonzer/nprows)).
do j=1,lastrow-firstrow+1
sum = 0.d0
do k=rowstr(j),rowstr(j+1)-1
sum = sum + a(k)*p(colidx(k))
enddo
w(j) = sum
Eddo
Using the MA models, we generated the scaling of the floating-point operation cost of the loop block in Figure 3 with the other loop blocks within a conjugate gradient iteration. The model predictions are shown in Figure 4. The total cost of two invocations of the submatrix vector multiply operation contributes to a large fraction of the total floating-point operation cost. Loop L1 is the first loop block in the CG timestep iteration and L2 is the second. Figure 4 shows that the workload is not evenly distributed among the different loop blocks (or phases of calculations), and the submatrix vector multiply loop can be a serious bottleneck. Furthermore, as we scale the problem to a large number of processors, we begin to identify loops that are either the Amdahl’s proportions of the serial code or their loop count is directly proportional to the number of MPI tasks in the system. We found that the loop count of loop number 3 and 8 depend on the number of MPI tasks (log2(log2(MPI_tasks)), while loop 1 and 8 scale at a slower rate than loop 2 and 7 (submatrix vector multiply loop), since the cost of loop 2 and 7 is divided twice by the scaling parameters as compared to 1 and 8, which is divided once by the scaling parameter. Another interesting feature is the scaling pattern, which is not linear because the mapping and distribution of workload depends on the ceiling (log2(MPI_tasks)).
We collected the runtime data for the loops blocks in CG time step iterations on XT38 and Blue Gene/L9 processors to validate our workload distribution and scaling patterns. Figure 5 shows the percentage of runtime spent in individual loop blocks. Comparing it with the workload distribution in Figure 4, we observe not only a similar workload distribution but also a similar scaling pattern. Note that the message passing communication times are not included in these runtime measurements. We collected data for the Class D CG benchmark on the XT3 system, which also validates the floating-point message count distribution and scaling characteristics that are generated by the symbolic MA models.
 Figure 4. Distribution of floating-point operation cost within a time step iteration in the NAS CG benchmark.
|
 Figure 5. Percentage of total runtime spent in individual loop blocks in a CG iteration.
|
One of the aims of creating the models of scientific applications is to be able to predict the application requirements for the future problem configurations at scale. We use our MA models to understand the sensitivity of floating-point operations, memory requirements per processor, and message volume to applications’ input parameters.
 Figure 6. Sensitivity of the number of FP and LS operations by increasing the array size parameter:
na. |
 Figure 7. Sensitivity of FP and LS by increasing the number of non-zero elements parameter:
nonzer. |
We begin experiments with a validated problem instance, Class C, for both the NAS CG and SP benchmarks, and scale the input parameters linearly. Note that the MA framework has a post-processing toolset that allows validation of MA model annotations with the runtime values. For instance, the PAPI_FP_OPS (number of floating-point operations) empirical data was compared with the ma_flop predicted value. The validated problem instances, Class C, have na=150000, nonzer=15, for the CG Class C benchmark with 128 MPI tasks. We increase the value of na linearly and generate the floating-point and load-store operation count using the MA symbolic models of the NAS CG benchmark. Figure 6 shows that the floating-point and load-store cost in the CG experiments increase linearly with the na parameter value. Similarly, we generated the growth rates for the floating-point and load-store operation cost for the other input parameter, nonzer. Results in Figure 6 and Figure 7 show that the floating-point and load-store operation cost in CG are relatively more sensitive to the increase in the number of nonzer elements in the array than the array size: na.
In the second experiment, the NAS SP benchmark has a single application parameter, problem_size, which we have used to represent the workload requirements (floating-point, load-store, memory and communication) in the MA symbolic models. Figure 8 shows the increase in the floating-point and load-store operation count by increasing the problem_size linearly. Note that like CG, the initial set of experiments (Class S, W, A, B, C and D) are validated on the target MPP platforms. Figure 8 shows that the floating-point operation cost increases at a very high rate by increasing the problem_size.
 Figure 8. Sensitivity of workload requirements with respect to the SP input parameter:
problem_size. |
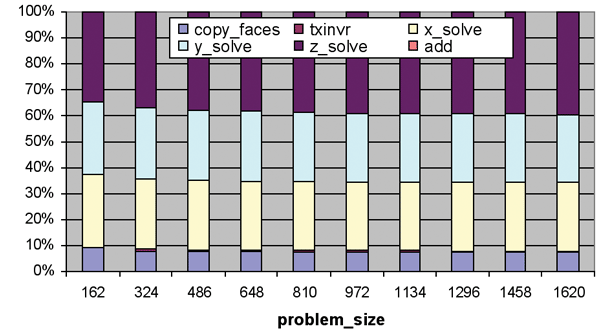 Figure 9. Impact of individual functions on overall increase in number of floating-point operations by increasing
problem_size parameter (1024 MPI tasks). |
Using the MA models, we not only generate the aggregated workload requirements shown earlier, but we also get an insight into the scaling behavior of the workload requirements within an application as a function of the problem_size parameter. Figure 9 shows the contribution of different functions in total floating-point operation count in SP time step iterations. The results shown in Figure 9 are generated for a fixed number of MPI tasks and by increasing the problem_size parameter linearly. The floating-point workload requirements generated by the MA model show that the z_solve is the most expensive function for runs with large number of processors. The cost of x_solve and y_solve are identical and consistent. Moreover, based on the MA model results shown in Figure 9, we can safely ignore the cost of txinvr and add functions in the further analysis.
Similarly, we studied the communication pattern of a climate application called Parallel Ocean Program (POP). POP is an ocean modeling code developed at the Los Alamos National Laboratory, which executes in a time-step fashion and has a standard latitude-longitude grid with km vertical levels. There are two main processes in a POP time-step: baroclinic and barotropic. Baroclinic requires only point-to-point communication and is highly parallelizable. Barotropic contains a conjugate gradient solver, which requires global reduction operations. Moreover, the discretized POP grid is mapped and distributed evenly on the two-dimensional processor grid. POP has two standard problem instances: x1 and .01. Processor grid dimensions are compile-time parameters in POP.
We studied the overall communication volume sensitivity and the individual message distribution in POP by varying the MPI grid sizes. POP uses MPI topology functions to create the two-dimensional virtual topology. All point-to-point communication operations are between the four nearest-neighbors in the 2D grid. Figure 10 shows the increase in overall volume in the two calculation phases, while Figure 11 shows the distribution of the message volume. Note that most messages are less than one Kbyte. Using this information, it is now possible to accurately reason about the actual application requirements. In this case, the application requires an interconnect that has low latency and low overhead for small messages.
 Figure 10. MPI volume scaling in POP.
|
 Figure 11. Distribution of individual message sizes.
|
MA is a new technique that combines the benefits from both analytic and empirical approaches, and it adds some new advantages, such as incremental model validation and multi-resolution modeling. Within the HPCS program, these models are useful to perform sensitivity analysis for future problem instances of HPCS applications. Moreover, the symbolic models can be evaluated efficiently and hence provide a powerful tool for application and algorithm developers to identify scaling bottlenecks and hotspots in their implementations. From the perspective of constructing, validating, and evaluating performance models, we believe that MA offers many benefits over conventional techniques throughout the performance lifecycle.