

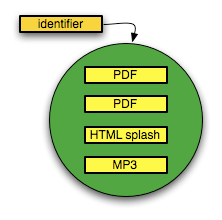
The new units of communication that are emerging from the modern research environment have a compound nature that does not have a direct parallel in traditional, paper-based publications or in the digital versions thereof (e.g., pdf, LaTex). They are aggregates of multiple distinct components that can vary according to semantic type (article, simulation, video, dataset, software, etc.), media type (text, image, audio, video, mixed), media format (PDF, XML, MP3, etc.), and network location (different components made accessible by different repositories). In addition, each aggregate carries an identifier associated with it by the information system that composed the aggregation, thereby establishing it as a logical unit of scholarly communication. In the remainder of this paper, we will refer to these aggregates as either compound information objects or compound objects (Figure 1).
These compound objects are a fundamental building block of eScience and eScholarship, and support for them is an essential aspect of cyberinfrastructure.3 For example, the ImageWeb 4 activity led by David Shotton’s BioInformatics Research Group at the University of Oxford explores the creation of so-called image webs that integrate cellular images held by publishers, research organizations, museums, and institutional repositories. Also, Gregory Crane, a leading scholar in the humanities, envisions the notion of recombinant documents.5 These documents have a number of features that differentiate compound documents from physical documents or their digital incunabula.5 They aggregate new information and existing fine-grained digital information. The aggregation can be human-author based, for example, as the result of a workflow within a so-called scholarly workbench,6 or machine-generated based, for example, on machine learning techniques and web crawling.7 The aggregation of an existing information unit into a compound object (re-use) is not due to the inherent nature of the aggregated unit, but is the result of the algorithmic design or the intention of the human that composed the compound object. Finally, these objects may be dynamic and grow over time based on usage patterns as well as social activity that provide additional context for the information within them.8


