

As noted, much of the functional infrastructure for providing OA has already been developed. In 2000,13 using the Open Archives Initiative (OAI) Protocol for Metadata Harvesting (OAI-PMH) 1, the Eprints 14 group at the University of Southampton designed the first and now widely used free software (GNU Eprints) for creating OAI-interoperable Institutional Repositories (IRs). Researchers can self-archive the metadata and the full-texts of their peer-reviewed, published articles by depositing them in these IRs. (If they wish, they may also deposit their pre-peer-review preprints, any postpublication revisions, their accompanying research data [D-OA], and the metadata, summaries and reference lists of their books). Not only can Google and Google Scholar harvest the contents of these IRs, but so can OAI services such as OAIster,15 a virtual central repository through which users can search all the distributed OAI-compliant IRs. The IRs can also provide download and other usage metrics. In addition, one of us (Tim Brody) has created Citebase,16 a scientometric navigational and evaluational engine that can rank articles and authors on the basis of a variety of metrics.17
Citebase’s current database 18 is not the network of IRs, because those IRs are still almost empty. (Only about 15% of research is being self-archived spontaneously today, because most institutions and funders have not yet mandated P-OA.) Consequently, for now, Citebase is instead focussed on the Physics Arxiv,19 a special central repository and one of the oldest ones. In some areas of physics, the level of spontaneous self-archiving in Arxiv has already been at or near 100% for a number of years now. Hence, Arxiv provides a natural preview of what the capabilities of a scientometric engine like Citebase would be, once it could be applied to the entire research literature (because the entire literature had reached 100% P-OA).
First, Citebase links most of the citing articles to the cited articles in Arxiv (but not all of them, because Citebase’s linking software is not 100% successful for the articles in Arxiv, not all current articles are in Arxiv, and of course the oldest articles were published before OA self-archiving was possible). This generates citation counts for each successfully linked article. In addition, citation counts for authors are computed. However, this is currently being done for first-authors only: name-disambiguation still requires more work. On the other hand, once 100% P-OA is reached, it should be much easier to extract all names by triangulation - if persistent researcher-name identifiers have not yet come into their own by then.
So Citebase can rank either articles or authors in terms of their citation counts. It can also rank articles or authors in terms of their download counts (Figure 1). (Currently, this is based only on UK downloads: in this respect, Arxiv is not a fully OA database in the sense described above. Its metadata and texts are OA, but its download hypermetrics are not. Citebase gets its download metrics from a UK Arxiv mirror site, which Southampton happens to host. Despite the small and UK-biased download sample however, it has nevertheless been possible to show that early download counts are highly correlated with - hence predictive of - later citation counts.20)

Citebase can generate chronometrics too: the growth rate, decay rate and other parameters of the growth curve for both downloads and citations (Figure 2). It can also generate co-citation counts (how often two articles, or authors, are jointly cited). Citebase also provides “hub” and “authority” counts. An authority is cited by many authorities; a hub cites many authorities; a hub is more like a review article; and an authority is more like a much cited piece of primary research.
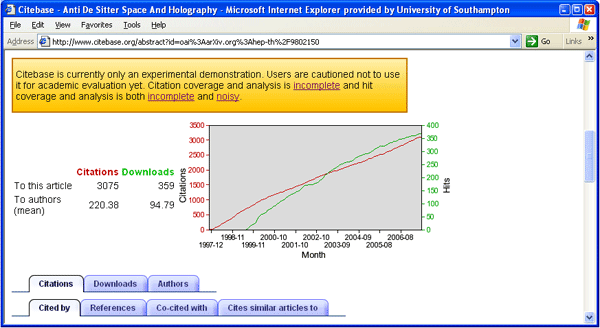
Citebase can currently rank a sample of articles or authors on each of these metrics, one metric at a time. We shall see shortly how these separate, “vertically based” rankings, one metric at a time, can be made into a single “horizontally based” one, using weighted combinations of multiple metrics jointly to do the ranking. If Citebase were already being applied to the worldwide P-OA network of IRs, and if that network contained 100% of each institution’s research publication output, along with each publication’s metrics, this would not only maximise research access, usage and impact, as OA is meant to do, but it would also provide an unprecedented and invaluable database for scientometric data-mining and analysis. OA scientometrics - no longer constrained by the limited coverage, access tolls and non-interoperability of today’s multiple proprietary databases for publications and metrics - could trace the trajectory of ideas, findings, and authors across time, across fields and disciplines, across individuals, groups, institutions and nations, and even across languages. Past research influences and confluences could be mapped, ongoing ones could be monitored, and future ones could be predicted or even influenced (through the use of metrics to help guide research employment and funding decisions).
Citebase today, however, merely provides a glimpse of what would be possible with an OA scientometric database. Citebase is largely based on only one discipline (physics) and uses only a few of the rich potential arrays of candidate metrics, none of them as yet validated. But more content, more metrics, and validation are on the way.


