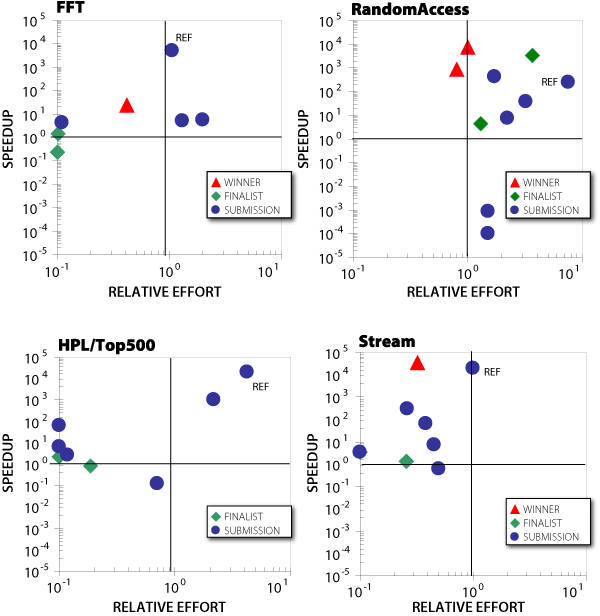
In the HPC Challenge Award Competition, teams were invited to submit their own implementations of selected benchmarks from the HPC Challenge benchmark suite.10 Evaluation of entries was weighted 50% for performance and 50% for code elegance, clarity, and size. The results of this competition are shown in Figure 4.
These graphs indicate the speedup and relative effort for each submitted implementation of the FFT, RandomAccess, HPL/Top500, and Stream benchmarks. Teams reported the performance of their implementation running on their own parallel computing platform, with no restriction on number of processors. This performance was compared to that of a baseline serial implementation to compute speedup. Relative effort is taken as the size of the parallel code relative to the baseline serial implementation. For each benchmark, the speedup and relative effort for the reference C/MPI implementation is indicated for comparison. The reference C/MPI implementation generally falls in the upper right quadrant of the graph, indicating that it achieved speedup at the cost of additional effort with respect to the serial version.
As shown in the graphs, 24 of the 30 submissions achieved speedup relative to the serial version, and 18 entries required less effort (i.e., smaller code size) relative to the serial version. All but two of the entries required less effort than the C/MPI reference implementation. It is also worth noting that half of the submissions, including all of the winning entries, fall in the upper left quadrant of the graph, indicating that they achieved speedup while requiring less development effort relative to the serial implementation. This result bolsters the argument for using a metric such as RDTP which takes into account both performance and developer effort.