

This issue of CTWatch Quarterly is intended to give an overview of the activity on e-Science and Grids in Europe. The European Commission were very early to identify Grids as a key technology for collaboration and resource sharing. The pioneering European DataGrid project, led by Fabrizio Gagliardi at CERN, worked with the world particle physics community, and with US computer scientists Ian Foster, Carl Kesselman and Miron Livny, to develop a global Grid infrastructure capable of moving large amounts of data and providing the vast shared compute resources needed to analyse this data. Many Petabytes of data per year will be generated by experiments at the Large Hadron Collider, currently under construction at the CERN Laboratory in Geneva. Similarly, the UK was also early to see the potential of Grid technologies for building the scientific ‘Virtual Organizations’ needed for networked scientific collaborations. In 2001, the UK announced the beginning of a $400M ‘e-Science’ initiative – where the term e-Science was introduced by John Taylor, the Director of the UK’s Office of Science and Technology, as a short-hand for the set of collaborative technologies needed to support the distributed multi-disciplinary science and engineering projects of the future.
It is now 2005 and the European Union has invested in a new generation of projects, building on the lessons of the European DataGrid and other similar projects. Besides investing in further R&D projects, the Commission has identified the need to develop and sustain an ‘e-Infrastructure’ consisting of a pan-European, high-speed research network, GEANT-2, together with a set of core Grid middleware services to support distributed scientific collaborations. The set of reports included here therefore includes three new R&D projects – SIMDAT, NextGrid and OntoGrid – plus the major Research Infrastructure project, EGEE – Enabling Grids for E-Science – which in many ways can be seen as the direct successor of the original European DataGrid project.
The SIMDAT project is developing generic Grid technology for the solution of complex application problems, and demonstrating this technology in several representative industry sectors. Special attention is being paid to security and the objective is to accelerate the uptake of Grid technologies in industry and services. Major European companies from the aerospace and automotive sectors and from the pharmaceutical industry are partners in the project which also involves major European Meteorological centers. By contrast, the NextGrid project is looking further out at the next generation of Grid technologies and is focused on inter-enterprise computing in the business sector with partners such as SAP, BT, Fujitsu, NEC and Microsoft.
OntoGrid represents another strand of activity and builds on pioneering work towards the development of a truly ‘Semantic Grid’ in the UK e-Science program. The project brings together knowledge services – such as ontology services, metadata stores and reasoning engines – with Grid services – such as workflow management, Virtual Organisation formation, debugging, resources brokering and data integration. This semantics-based approach to the Grid goes hand-in-hand with the exploitation of techniques from intelligent software agents for negotiation and coordination and peer-to-peer (P2P) computing for distributed discovery. These four projects are by no means all of the current EU Grid projects and details of these and other projects may be found on the Cordis website: http://www.cordis.lu/
The UK e-Science Program has now entered its third phase and this is focusing on laying the foundations for a sustainable national e-Infrastructure – or Cyberinfrastructure in US-speak. These activities are described in a short article by the editors.
Complementing the other article's in this issue, Dan Reed's personal reflections on the recent report of his PITAC subcommittee on Computational Science shows that a shared sense of current challenges and current opportunities is driving the development of e-Infrastructure and e-Science on both sides of the Atlantic.
The last article in this issue is of a different character and is a personal account by Microsoft’s Chief Technology Officer, Craig Mundie, of his own roots in High Performance Computing and the reasons why Microsoft are now taking steps to become engaged with the HPC community. This is a fascinating glimpse into the future and indicates that Microsoft intends to play a major role in the development of ‘commodity HPC’ systems.
Tony Hey and Anne Trefethen
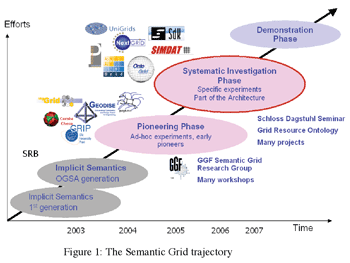 In the last few years, several projects have embraced the Semantic Grid vision and pioneered applications combining the strengths of the Grid and of semantic technologies, particularly the use of ontologies for describing Grid resources and improving interoperability.6 The UK myGrid7 project uses ontologies to describe and select web-based services used in the Life Sciences; the UK Geodise project uses ontologies to guide aeronautical engineers to select and configure Matlab scripts;8 the Collaboratory for Multi-scale Chemical Science9 and CombeChem10 projects both use semantic web technologies to describe provenance metadata for chemistry experiments; the US-based Biomedical Informatics Research Network uses technologies to mediate between different databases in neuroscience;11 and the UK’s CoAKTing project uses ontologies to assist in virtual meetings between scientists.12 On the Semantic Grid road we are now moving from a phase of exploratory experimentation to one of systematic investigation, architectural design and content acquisition for a semantic infrastructure that accompanies a cyberinfrastructure (Figure 1).
In the last few years, several projects have embraced the Semantic Grid vision and pioneered applications combining the strengths of the Grid and of semantic technologies, particularly the use of ontologies for describing Grid resources and improving interoperability.6 The UK myGrid7 project uses ontologies to describe and select web-based services used in the Life Sciences; the UK Geodise project uses ontologies to guide aeronautical engineers to select and configure Matlab scripts;8 the Collaboratory for Multi-scale Chemical Science9 and CombeChem10 projects both use semantic web technologies to describe provenance metadata for chemistry experiments; the US-based Biomedical Informatics Research Network uses technologies to mediate between different databases in neuroscience;11 and the UK’s CoAKTing project uses ontologies to assist in virtual meetings between scientists.12 On the Semantic Grid road we are now moving from a phase of exploratory experimentation to one of systematic investigation, architectural design and content acquisition for a semantic infrastructure that accompanies a cyberinfrastructure (Figure 1).  The aim of EGEE is to leverage the pre-existing grid efforts in Europe, thematic, national and regional, to build a production quality multi-science computing Grid. As a result, the primary objective is to build the infrastructure itself, connecting computing centres across Europe (and more recently, around the globe) into a coordinated service capable of supporting 24/7 use by large scientific communities. To support this production service, the project also aims to re-engineer existing middleware components to produce a service-orientated middleware solution. Finally, the project aims to engage the maximum number of users running applications on the infrastructure through dissemination, training and user support. These tasks have been divided into different activity areas, which are tackled by different groups within the project. These groups are distributed across a number of partner institutes with relevant experience, such that the project helps to connect its partners and encourage knowledge transfer in the process of achieving its goals.
The aim of EGEE is to leverage the pre-existing grid efforts in Europe, thematic, national and regional, to build a production quality multi-science computing Grid. As a result, the primary objective is to build the infrastructure itself, connecting computing centres across Europe (and more recently, around the globe) into a coordinated service capable of supporting 24/7 use by large scientific communities. To support this production service, the project also aims to re-engineer existing middleware components to produce a service-orientated middleware solution. Finally, the project aims to engage the maximum number of users running applications on the infrastructure through dissemination, training and user support. These tasks have been divided into different activity areas, which are tackled by different groups within the project. These groups are distributed across a number of partner institutes with relevant experience, such that the project helps to connect its partners and encourage knowledge transfer in the process of achieving its goals. 

