Accelerators are designed for very high computing power and very high energy efficiency. Usually, this is accomplished by devoting much more area to floating point logic, and much less area to instruction control logic. Typically, accelerators require some form of instruction-level vectorization, and some form of thread-level parallelization. Most of the time, accelerators utilize static pipelines with no out-of-order execution (OOE) capabilities and no branch prediction.
Usually, this forces a style of programming where unrolling is taken to the extreme to expose instruction-level parallelism to the fullest. Frequently, corner cases are ignored, loop boundaries are fixed, and entire loop nests are eliminated by complete unrolling. It is often much more efficient to compute redundant results and discard them, than to take a branch.
Tuning kernels for accelerators is a challenge on its own, as the programmer faces a typical conundrum of multi-variable optimization. Not only is the number of parameters large, and therefore so is the resulting search space, but the parameters are also usually linked by counterintuitive relationships, i.e., a seemingly beneficial setting for one prevents a reasonable setting for another.

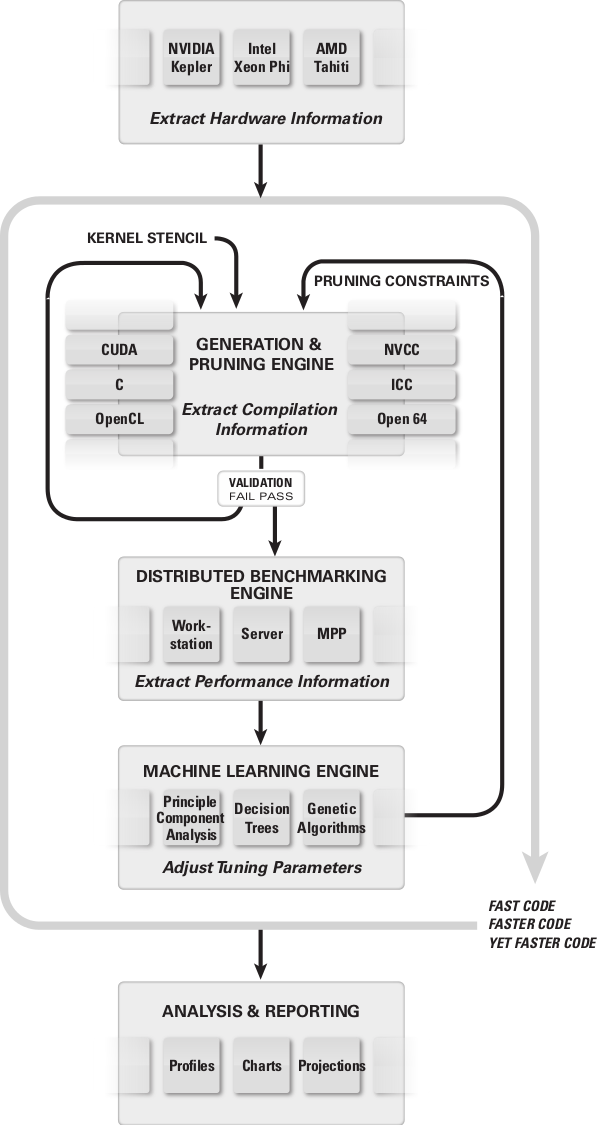 BEAST thrives in a large parameter space, not limited by any artificial constraints that could potentially hinder the search for the optimal solution. A large space is dealt with efficiently by powerful pruning, using a set of derived metrics, stemming from the harsh realities of the accelerator architecture. Inferior and invalid kernels are easily weeded out and discarded.
BEAST thrives in a large parameter space, not limited by any artificial constraints that could potentially hinder the search for the optimal solution. A large space is dealt with efficiently by powerful pruning, using a set of derived metrics, stemming from the harsh realities of the accelerator architecture. Inferior and invalid kernels are easily weeded out and discarded. 



