A System-wide Productivity Figure of Merit

November 2006 B
|
A System-wide Productivity Figure of Merit
|
November 2006 B |
Establishing a single, reasonably objective and quantitative framework to compare competing high productivity computing systems has been difficult to accomplish. There are many reasons for this, not the least of which is the inevitable subjective component of the concept of productivity. Compounding the difficulty, there are many elements that make up productivity and these are weighted and interrelated differently in the wide range of contexts into which a computer may be placed. Significantly improved productivity for high performance government and scientific computing is the key goal of the High Productivity Computing Systems (HPCS) program. Evaluating this critical characteristic across these contexts is clearly essential to attaining and confirming this goal.
This is not entirely a new phenomenon. Anyone who has driven a large scale computing budget request and procurement has had to address the problem of turning a set of preferences and criteria, newly defined by management, into a budget justification and a procurement figure of merit that will pass muster with agency (and OMB) auditors. The process of creating such a procurement figure of merit helps to focus the mind and cut through the complexity of competing user demands and computing options.
Imagining that we are initiating a procurement where Productivity = Utility/Cost will be the criteria, we have developed a total productivity figure of merit. This framework includes such system measurables as machine performance and reliability, developer productivity, and administration overhead and effectiveness of resource allocation. This is all in the context of information from the particular computing environment that may be proposing and procuring an HPCS computer. We note that this framework is applicable across the broad range of environments represented by HPCS mission partners and others with science and enterprise missions that are candidates for such systems.
The value of each variable in our figure of merit is intended to come from a single source, either from one of the HPCS R&D areas or from a mission organization that may procure a system. While we identify the potential source of each value, we do recognize that some of these numbers will not be easy to obtain, particularly those involving the impact of system design on human productivity. Nonetheless, we believe that, at the least, this framework will identify the individual metrics that these efforts should strive to measure. In the end, we will all have to admit that some combination of measurements, informed guesses, and subjective evaluations will be needed to arrive at a figure of merit number.
We also recognize that there is coupling between some of the variables we treat as independent. For example, a user's productivity is impacted by the way jobs are allocated. To deal with this, we suggest assuming an environment in which a particular variable is determined. This means that values for all the other variables, their “operating point,” must be specified for each measurement of a variable. 1 For measurable variables, these operating points come from measurements and studies. One could iterate to a final answer, but we argue that this is unnecessary because the effect of any such coupling, with reasonable operating point guesses, is far smaller than the precision (such as it might be) of any of the measured variables involved.
Not surprisingly, our figure of merit has much in common with ideas expressed in earlier HPCS work. 3 However, we extend beyond this in the following ways:
In a well-balanced HPCS, significant costs will be incurred for resources other than just the CPU cycles that dominate thinking in the commodity cluster architectures. In particular, memory and bandwidth resources will have cost as much or more than CPU, and efficient programs and job allocation will have to optimize use of memory and bandwidth resources as much as CPU. Our framework allows for the inclusion of any set of significantly costly resources.
A single job may be highly optimized, and those in the project it comes from will inevitably believe its utility (or value) approaches infinity. However, a computer center must optimize the total workload, given its organization's evaluation of relative priority (utility or value) for each project and job. The overall utility of the total output of the computer depends on the degree to which the allocation of system resources reflects the institution's priorities and determination of value (or utility). Further, the productivity of the administration staff depends on a system's administration environment and tools, and on its stability. 5
The remainder of this article is organized as follows. In Section 2 we define the productivity figure of merit as a combination of factors, where each factor represents a different aspect of productivity that can be evaluated relatively independently of the others. In Section 3 we show how the figure of merit captures the perspectives on productivity of people in different institutional roles and we show how productivity ratios can be used to simplify the evaluation process. In Section 4 we discuss the need for productivity benchmarking and propose the use of operating points to narrow the scope of the analysis needed for a productivity evaluation. We provide a recipe for using the figure of merit in Section 5. We conclude and describe our experience applying the figure of merit using a simple spreadsheet (available from the authors) in Section 6.
In factoring out the productivity contributors, we take an approach that, like the blind men and the elephant, focuses on what can be measured at defined parts of the beast and builds to a picture of the whole productivity equation for a system in a particular environment. This assumes that our elephant is reasonably smooth and predictable between those points we can feel with our measurements. 7
We start with
Productivity = Utility/Cost
We expand the utility into system level and job level components
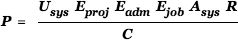 (1)
(1)
As a convention, we use the letters U, E, A, R, C to denote variables of utility, efficiency, availability, resources, and cost, respectively. The subscripts indicate the variables that address system level (including administrative and utility) and job level factors.
We recognize that some aspects of the system level efficiency will never be amenable to measurement and will always require subjective evaluation. Only subjective evaluation processes can address the first two variables in the utility numerator. In principle one can measure the last four variables and the HPCS research program is addressing such measurements.
We have been emphasizing that this is to be a figure of merit, including estimates and evaluations of what we expect the productivity output of an installation to be. For clarity, in explaining this formulation, we will start by talking as if we know what happened over the lifetime, as if we are doing a post-mortem. We will mention in passing how the components relate to ongoing work on productivity estimators. We will return to discuss these estimators in more detail in Section 4.
The goal of those optimizing utility at the job level is to maximize resources they can effectively apply to their problem. This will enable them to bring their project to a successful conclusion with higher utility (larger scale or finer granularity solutions or higher throughput of data intensive problems) or more rapidly (allowing more problems of similar utility to be accomplished within the lifetime of the resources). It is “not in their job description” to address the relative utility of their problem compared to others (though they may be inclined to do so). So, we consider utility at the job level, Ujob, to be just the cost ($) of the resources that they have effectively used, and the job level efficiency Ejob = Ujob/Csys, with Csys the total lifetime system cost. As defined below and in the Appendix, Ujob and Ejob are averaged over all jobs.
The government, or the owners or stockholders, establish how activities are to be valued by the institution management. Management valuation appears in the largely subjective Usys variable, which includes, for example, what constitutes “success” for a computing activity. They may well value a successfully completed activity higher than the cost of the resources used. (It would be unusual for them not to do so at budget proposal time.) Usys assumes, as managers might often wish, that all resources are available and fully allocated at all times during the life of their expensive system.8 We define it as a multiplier to the peak system resources in CPU units. System utilization efficiency and project level effectiveness is included in Eadm and Eproj as described below.
Once a system is delivered, the system administrators (and vendor) strive to meet management expectations for availability, Asys and system level resource utilization efficiency (including allocation), Eadm.
More detailed descriptions of the individual variables follow and they are expanded further in the Appendix. We indicate dimensional units in brackets.
P, the productivity, is dimensionless, as required by the common economic interpretation of the productivity concept we use, output/input, [$]/[$].
C is total cost of ownership, including all costs for developing software and running it on the computer, over a defined lifetime of the system (T). This is expanded into components in the Appendix. [$]
T is the lifetime of the system as defined in the typical budget approval process. It does not show up explicitly in the top-level equation, but it is important to the definitions of the variables as well as for the measurements. It will depend on considerations specific to each environment, including, for example, whether the procurement and justification (and cost) involve continuing upgrades. Those responsible for budget submissions at the proposing institution are the source of this variable. [yrs]
Ejob is the ratio of Ujob to the total system cost Csys. Ujob is the total productively used resources over the lifetime by all individual jobs in all project activities, normalized to the assumption of 100% availability and 100% resource allocation. To a large extent, this efficiency measures how well programs use parallel resources. We include other costly resources (e.g., memory, bandwidth, I/O) besides CPU. In order not to favor one class of resources over another, we weight the resources by their relative costs.9 We say “productively used” so that we only include resources that would be consumed in direct support of maximizing utility for the specified problem. Estimators for Ejob and for  , the corresponding average total project personnel time (including development and production) per project, are what Job-level Productivity Benchmarks should aim to measure for different environments and systems. More detailed definitions of these can be found in.2 [Dimensionless]
, the corresponding average total project personnel time (including development and production) per project, are what Job-level Productivity Benchmarks should aim to measure for different environments and systems. More detailed definitions of these can be found in.2 [Dimensionless]
Asys is the availability; the fraction of total resource time available to the jobs making up Rjob. This accounts for all planned and unplanned downtimes, but does not include job restarts due to failures, which is included in Esys below. Note this is not fraction of system time, but fraction of resource time, so that it accounts for portions of the large system being available when other portions are down. This parameter is based on vendor estimates of MTTF, maintenance requirements, and other RAS considerations. [Dimensionless]
The product Esys≡EadmEproj is the effectiveness of the workload resource allocation at meeting the institution's priorities. System architecture, software, and administrative tools can make a big difference to this important metric. This is where utility (or value) enters the picture and we go beyond just looking at job-level optimization. We assume that the institution will have a process for establishing the priority or the utility or the value of the individual projects and jobs. Esys is the ratio of the actual total value of the jobs run over the lifetime to the optimal total that would come from maximally efficient management of a reference HPCS platform,10 for a given job mix, a given installed system configuration, and a given time pattern of resource downtime. As shown in [2], we allow for time dependent values, since allocation efficiency that completes a job or project long after it is needed has little or no value. We recognize explicitly (see further discussion in [2]) that not all the factors that go into Esys are amenable, even in principle, to before or after the fact quantitative measurement. Some will need to be evaluated subjectively, and primarily have to do with the effectiveness with which projects (management assigned and valued tasks) are able to accomplish management goals and schedules. This is why we have written Esys as a product with Eadm as the measurable part and Eproj the project effectiveness part requiring subjective evaluation. Eadm is the estimator that, along with the cost of administration, is what System-level and Administration Productivity Benchmarks should aim to measure, for different systems, configurations, and user environments. Eproj represents other considerations that result in reduced efficiency at delivering utility. [Dimensionless]
Usys is the summed utility (or value) of all projects or activities, per unit of total available resources, R, that would complete successfully during the lifetime T if the system administrators given the systems tools and capabilities of the HPCS Reference Platform were able to attain the optimum level of resource utilization and the system was perfectly available. The values may be assigned by whatever process the institution uses to prioritize its projects and justify its budget proposals. This variable only includes the local institution's evaluation of the value of the projects it intends for the installation. In some environments, it may be ignored and set to a constant such as Csys. We convert all resource units to CPU operations, weighting by their relative costs. [$/ops]
Individuals with different professional responsibilities look at productivity with naturally different perspectives. These include, for example, acquisition decision makers, project managers, individual programmers (“users”), researchers, system administrators, service engineers, operators, vendors, and system designers. It is useful to focus on two of these, project managers, and decision makers.
In principle, project manager perspectives are aligned with their institutional management, the decision makers. In practice, they differ because at least our stereotype of a project manager is only concerned with project personnel costs and not either machine operating or capital costs. And similarly the project manager can only address certain terms in the utility numerator of the productivity ratio. So, the project manager's perspective on productivity is a subset of the decision maker in Eqs.1 and 2,
 (2)
(2)
The decision maker's (acquisition) productivity we developed in earlier sections is then
 (3)
(3)
Here Eorg=EadmAsys is the organization's and system's multi-project resource utilization efficiency.
We can get considerably more simplification and, perhaps, also more insight, if we now think in terms of comparing the new, next generation (HPCS) system that we are evaluating to a standard reference machine. This reference can be a defined traditional MPI cluster configuration for which there is some level of understanding and experience regarding productivity in its environment. All measurements and terms in Eq. 8 can be ratios of the new system to the reference. In most organizations, for budget and institutional reasons, the ratio of project (development personnel) costs to machine and operations costs is typically a constant. In this situation we conclude that
 (4)
(4)
The normalization to the reference system is indicated by bars. We assume that management evaluation of utility obtainable per effectively utilized resource is identical for the two systems ( =1). The not-surprising conclusion is that we can consider the relative improvement in productivity to be just the product of productivity measurables for the new system normalized to the old.
=1). The not-surprising conclusion is that we can consider the relative improvement in productivity to be just the product of productivity measurables for the new system normalized to the old.
We could get an accurate figure of merit as part of a post-mortem – after the life cycle is over. At that point, we could have access to real experience. But that's not what we want; we need to predict and estimate in advance. So where do our productivity estimators come from? We have been assuming there are two classes of productivity benchmarking activities: 1) at the job- and project-level, measuring development and production activities; and, 2) at the system-level, measuring administration activities and the effect of the differences in system designs and configuration options on administration overhead and system-level resource utilization.
Development, job- and project-level, productivity benchmarks would aim to measure - for the problem mix of a specific environment - the development time required to attain different levels of productive resource utilization. The simplest example is how much programming time it takes to attain various levels of speedup. Curves of productive resource utilization vs. development and other project personnel time will increase, probably like step functions and will usually present an obvious point of diminishing returns. This can be taken as the “operating point.” Averaged over the work flow and job mix, it provides an estimator of and ECPU, Emem, EBW, and EIO.
Similarly, administration, system-level, benchmarks can aim to measure Eadm. For aspects involving effective scheduling, this could be accomplished, specific to a given environment and system configuration, by creating a simulated scheduling environment and allowing working administrators to attempt to optimize the allocation of a list of prioritized (value assigned) jobs for some simulated time period. An ideal allocation would be defined for each environment as attaining the full value of each project including time considerations. The ratio of the measured to the ideal would give an estimator for this aspect of Esys. Just as for the development benchmarks, this can be treated as a curve where better allocation, more efficient use of resources, and a general increase in output value, uses more administrator time, and a reasonable operating point of diminishing returns is selected. The cost of the administrator time at this operating point would be included as all or part of cadm (depending on how complete a benchmark simulation is used).
Here is a step by step approach to a normalized productivity figure of merit based on workflow productivity measurements:
 11.
11. 13.
13. for each environment, and score the systems with regard to project success rate, accessibility, ease of use effectiveness, …
for each environment, and score the systems with regard to project success rate, accessibility, ease of use effectiveness, … ) or GUPs, etc. Vendors also provide information on availability of the new system. Reference system availability should be obtained from experience data.
) or GUPs, etc. Vendors also provide information on availability of the new system. Reference system availability should be obtained from experience data.
We have tried to demonstrate that the productivity figure of merit we have described here is really much simpler than it may have first appeared. It is no more than a way of getting to a single number that combines what we know or can guess about a system configured for a particular environment into something that approximates a measure of total productivity. It can be used in HPCS design comparisons, subsequent budget justifications, and ultimately, we hope, in procurements.
Many of the numbers needed as input are traditional cost and performance variables. The hard parts, of course, are the benchmarks needed to measure the productivity of humans when confronted with these new systems. We see these productivity benchmarks as simply measuring curves of efficiency of job resource utilization, or system utility optimization, vs. the cost in time of the human effort. These curves should clearly indicate an obvious point of diminishing returns, an operating point.
We recognize that we have made use of words like simply, clearly, obviously, and this may be unfair. We know that getting a number that approaches being a true measure of productivity for a given system is going to be difficult. We need goals for the productivity benchmarking efforts to aim at, and we think this framework provides them.
We have developed a spreadsheet, which may be obtained from the authors, that allows one to gain some intuition into how system-wide productivity comes together from the many components. The first six sheets of the spreadsheet are entry sheets to be completed by the different entities that may be responsible for the information: Vendor Cost, Host Environment and Values, Performance, Job-level Productivity, Administration Productivity, and Subjective Productivity Evaluation. The last sheet summarizes the calculated result.
We see the process of obtaining an informative figure of merit as being incremental. One may start by entering guesses, policies, and goals, and then progress through preliminary measurements and even post-mortem analysis. For each entry, the spreadsheet has a quality descriptor which may be selected from a list, presently including: canonical, policy, wild guess, informed guess, measured 100%, measured 30%, measured 10%, measured 1%, post mortem.
It is instructive to play with the spreadsheet, changing performance, productivity, and cost variables and seeing their effect on the figure of merit and its components on the last sheet of the spreadsheet. In this way, one can learn quickly in a particular environment what matters and what doesn't for the life-cycle productivity, our figure of merit. Even with the simplifications,15 and possible biases,16 built into this approach, we believe it goes furthest towards allowing a real understanding of how best to reach the goal of maximizing overall productivity. An example of the use of the spreadsheet to compare the productivity of two systems can be found in [2].
Here we expand the high level terms of Eq.1:
A. Cost
 (5)
(5)
Here,
 (6)
(6)
is the total life cycle cost of the system. [$]
It includes the following costs:
One Time Costs [$] [$]Initial hardware Initial software (system and purchased application software) Non-standard or specialized facility equipment (e.g., water cooling) Facility preparation (electrical and other building modification) Installation |
Recurring Costs [$/yr] [$/yr]Hardware maintenance (repair and preventive) Software maintenance (repair and preventive) Facility maintenance Hardware and software upgrades (as required by contracted goals) Electrical costs (for system and cooling)17 Space and standard facility equipment (GSA or other rate per sq-ft per year) |
 is the total lifetime administration costs.
is the total lifetime administration costs.
nadm is average number of personnel at the local institution supporting system maintenance and management, user assistance, and system workload optimization. cadm is the cost per person-year [$/person-year] of this support. These costs are in large measure affected by the workload environment as well as the system and its administration tools. nadm is the personnel load that System-level and Administration Productivity Benchmarks can aim to measure along with Eadm. nadm can be broken into two parts, one that is a baseline cost in the host environment for managing a system of this magnitude, 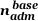 and a part that corresponds to the effort to optimize utilization and other activities where the administrators' productivity can be affected by administrative tools,
and a part that corresponds to the effort to optimize utilization and other activities where the administrators' productivity can be affected by administrative tools, 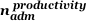 . [Persons]
. [Persons]
N is the total number, over the lifetime T, of unique program activities (projects with the goal of creating an appropriately efficient program and a correct and useful result). The definition of program activities and an estimate of N is very dependent on the local environment and should come from the institution for which systems are being evaluated. [Dimensionless]
is the average total project personnel time for one of the unique program activities counted by N. This includes, in addition to the software development effort, personnel costs for any production related effort (e.g., job submission, bookkeeping, etc.). This, along with Ejob, is what Job-level Productivity Benchmarks should aim to measure for different environments and systems. [Person-years]
cproj is the average cost per person-year of all project-related personnel. [$/Person-year]
Alternatively, we can write project costs in terms of the average total number of project personnel, nproj, over the lifetime, T, so that the total project cost is  .
.
B. Productively Used Resources at the Job Level
As noted before we define the job level utility as the cost of the resources productively used
Ujob=cCPUECPURCPU+cmemEmemRmem+cBWEBWRBW+c10E10R10 (7)
and the job level efficiency as
Ejob=Ujob/Csys (8)
Here, the subscripts refer to the resource types, CPU, memory, inter-processor bandwidth, and I/O bandwidth resources, respectively. This can obviously be generalized to include other resources with significant costs.
The cr are the total costs attributable to each resource per unit of that resource. The total life cost is Csys described above,
Csys=cCPURCPU+cmemRmem+cBWRBW+c10R10 (9)
The Rr are the total lifetime resources of type r used by all of the N project activities.18 The resources are assumed for the purposes of this job-level variable to have been 100% allocated and the time to be 100% available for one of the N activities.19 Note that costs only come into Eq.5 to provide a relative weight for the different resources.
The Rr are based on performance measurements and a choice of configuration options. Remember that the Rr include the lifetime, so that the units for CPU, memory, bandwidth, and IO are [ops] (not ops/sec), [byte-years], [bytes], and [bytes], respectively. We weight the resources by their relative costs, so Ujob, is just the cost ($) of the resources that the project teams could have used if they were perfectly efficient. The cr provide the conversion from resource units to utility as cost in $ [$/ops], [$/byte-years], [$/bytes], [$/bytes].
The Er are the fraction of the total of each resource productively utilized on average by all the jobs in the N project activities. The variables Er are efficiency estimators that Job-level Productivity Benchmark efforts can aim to measure (for specified workflows and job mixes) along with the average effort per activity, .
By “productively,” we mean that resources used only to support parallelization are not counted, and that the single processor algorithm being used is not wasteful of resources. This can either be a protocol rule in the benchmarking or the benchmarks can down-rate the utilization fractions Er for resource usage that is not in direct support of the task or algorithms that are less than optimal.20
The Er are [dimensionless].
C. Project and System Level Efficiency
Eadm, the measurable part of system efficiency, may be understood as the effectiveness of the administrative staff in allocating resources efficiently given the tools and the real environment of their system and the time that they have available, as included in the cost cadm. An estimator for this traditional measure of system utilization, Eadm, is what System-level and Administration Productivity Benchmarks can aim to measure, as discussed in Section 4.
Eproj is the subjective component of the figure of merit to allow for evaluation of issues, which might be attributed to system hardware or software, such as project failures or delays and the accessibility of the computing system environment to staff with different levels of computing skills. In general, it includes system or configuration factors that impact the effectiveness of programming teams at accomplishing their goals. This is where utility vs. time considerations may be included, as discussed in [1].
Eadm and Eproj are [dimensionless].
, defined below, are made.