SLOPE - A Compiler Approach to Performance Prediction and Performance Sensitivity Analysis for Scientific Codes

November 2006 B
|
SLOPE - A Compiler Approach to Performance Prediction and Performance Sensitivity Analysis for Scientific Codes
|
November 2006 B |
The lack of tools that can provide programmers with adequate feedback at a level of abstraction the programmers can relate to makes the problem of performance prediction and thus of performance portability in today’s or tomorrow’s machines extremely difficult. This paper describes SLOPE – the Source Level Open64 Performance Evaluator. SLOPE uses an approach to the problem of performance prediction and architecture sensitivity analysis using source level program analysis and scheduling techniques. In this approach, the compiler extracts the computation’s high-level data-flow-graph information by inspection of the source code. Taking into account the data access patterns of the various references in the code the tool uses a list-scheduling algorithm to derive performance bounds for the program under various architectural scenarios. The end result is a very fast prediction of what the performance could be but, more importantly, the reasoning of why the predicted performance is what it is. We have experimented with a real code that engineers and scientists use in practice. The results yield important qualitative performance sensitivity information that can be used when allocating computing resources to the computation in a judicious fashion for maximum resource efficiency and/or help guide the application of compiler transformations such as loop unrolling.
Modern, high-end computers present a complex execution environment that makes performance understanding and performance portability extremely difficult. Programmers go to extreme lengths to manually apply various high-level transformations, most notably loop-unrolling, in an attempt to expose more Instruction-Level-Parallelism (ILP) and thus take advantage of micro architecture features such as pipelining, super-scalar and multi-core characteristics. The lack of performance prediction and analysis tools that can provide feedback to the programmer about the performance leaves the programmer in an uncomfortable position. Without understanding why the performance is what it is, the programmer is forced to search for the best possible transformation sequences by trial and error. Furthermore, existing performance understanding tools provide feedback at a very low level of abstraction, such as cache miss rates or clocks-per-clock-cycle providing no clue as to what the bottlenecks that lead to such metric values are.
Earlier approaches to performance modeling and understanding were purely empirical. Researchers developed representative kernel codes of large-scale applications such as the NAS Parallel1 and the SPEC.2 By observing the performance of these kernels on a given machine one could extrapolate in a qualitative fashion, the performance behavior of a real application. More recently researchers have developed models for the performance of parallel applications by examining its memory behavior.3 4 Other work has focused on modeling the behavior of an application by first accurately characterizing the running time of the sequential portions of the application using analytical modeling based on intimate knowledge of the applications mathematics and empirical observations to extract the corresponding parameter values.5 On the other end of the spectrum, cycle-level simulators for architecture performance understanding at a very low level are simply too slow for realistic workloads. As a result, the simulations tend to focus on a minute subset of the instruction stream or use sampling techniques, and are thus limited to very focused architectural analyses.
This article describes an alternative approach to the problem of performance prediction and architecture sensitivity analysis using source level program analysis and scheduling techniques. In this approach, the compiler first isolates the basic blocks of the input source program and extracts the corresponding high-level data-flow-graph (DFG) information. It then uses the high-level information about the data access patterns of array references to determine the expected latency of memory operations. Once the DFG of each basic block, most notably the ones in the body of nested loops is extracted, the compiler tool uses a list-scheduling algorithm to determine the execution time of the computation. This scheduling makes use of the DFG as well as the functional resources available in the architecture like the number of load/store or functional units and for specific operation latency values.
While this approach has the advantage of being less sensitive to the specific details of an existing machine and not taking into account, with accuracy, the effects of a given compiler, it offers other benefits that instruction-level instrumentation-based performance analysis tools cannot offer. First, it is much closer to the source code and thus can provide feedback to the programmer about which operations (not necessarily instructions) can lead to performance bottlenecks. For example, if the schedule reveals that an indirect array access is accessed randomly, it can determine that this load operation will exhibit a high memory latency and thus stall the pipelining of a functional unit. Under these scenarios the compiler can notify the programmer of the operations that are very likely to cause severe performance degradation. Second, and because it operates at a much higher level we do not require any sort of lengthy low-level instrumentation that requires the code to be executed to extract (sampled) traces. Finally, we are free to emulate future architecture features, such as dedicated custom functional units (e.g., gather-scatter unit), or even emulate some operations in memory by assigning specific costs to specific subsets of the DFG in a computation.
We have experimented with this approach using UMT2K, a synthetic kernel modeled after a real physics photon transport code. 6 Using this computational kernel, our tool determines qualitatively that in the absence of loop unrolling no more than two functional arithmetic units are needed to attain a level of performance that is consistent with the critical path of the computation. When the core is unrolled by a factor of four, no more than four functional arithmetic units are needed. In the context of a multi-core architecture, this information would allow a compiler to schedule and adapt its run-time execution strategy to unroll just the required amount depending on the available units.
The rest of this article is organized as follows. In the next section we describe in more detail the technical approach of our tool and how it allows performance predictions, and we perform architectural sensitivity analysis. Section 3 presents the experimental results for our case study application – the UMT2K kernel code. We present concluding remarks in section 4.
We now describe the details of our technical approach to the problem of performance prediction and sensitivity analysis using high-level source code information using static compiler data and control- dependence analysis techniques.
This analysis extracts the basic blocks at the source code level by inspection of the compiler intermediate representations in Whirl.7 Because the front-end of the compiler does perform some deconstruction of high-level constructs, most notably while-loops, it is not always possible to map the intermediate representation constructs back to source code constructs. Despite some of these shortcomings, the front-end does keep track of line number information that allows the tool to provide reasonably accurate feedback to the programmer.
For each basic block, the compiler extracts a data-flow graph accurately keeping track of the dependencies (true-, anti-, input- and output- dependences) via scalar variables and conservatively by considering that any reference to an array variable may induce a dependency. In some cases, the compiler can use data dependence analysis techniques (see e.g., 8) to disambiguate the references to arrays and thus eliminate false dependences in the DFG. In the current implementation, we make the optimistic assumption that arrays with distinct symbolic names are unaliased. While this assumption is clearly not realistic in the general case, it holds for the kernel code in our controlled experimental results.
Finally, we identify the loops of the code across the various basic blocks of a procedure to uncover basic and derived induction variables. This information is vital in determining array access stride information as explained below.
In this analysis, the compiler extracts the affine relations between scalar variables in the array indexing functions whenever possible taking into account the basic and derived induction variables. For example, knowing the fact that the scalar variables i and j are both loop induction variables, the array reference a[i][j+1] will have as affine coefficients the first and second dimension, respectively the values (1,0,0) and (0,1,1), where the last element in each tuple corresponds to the constants 0 and 1 in the expressions i+0 and j+1. Using this access information and the layout of the array (i.e., either column-wise and row-wise), the analysis determines the stride information for each access and thus makes judgments about the latency of the corresponding memory operations. Regular memory accesses are very likely to hit the cache or reside in registers as a result of an aggressive pre-fetching algorithm9 whereas an irregular or random memory reference is very likely to miss the cache. The construction of the DFG uses this knowledge to decorate the latency of the individual array accesses as either regular or irregular thus taking into account, to some extent, part of the memory hierarchy effects.
Using the extracted DFG, we then develop our own operation scheduler for determining the latency of the execution of each basic block. In this scheduler we can program the latencies of the individual operation as well as if they are executed in a pipelined fashion or not. Our scheduler also allows us to specify the number of functional units for either each individual type of operations or for a generic functional unit. For example, we can segregate the arithmetic and floating-point operations in a single functional unit or allow all of them to be executed in a generic functional unit with integer and floating-point operations. We can also specify multiple load and store units thus modeling the available bandwidth of the target architecture. Finally, we assume the scheduler is an on-line as-soon-as-possible scheduling algorithm with zero-time overhead in scheduling of the various operations in the various functional units.
For simplicity, in this first implementation, we assume the target architecture has enough registers available to support the manipulation of the various arithmetic and addressing operations. This assumption, while not unrealistic for basic blocks with a small number of statements, is clearly unrealistic for larger basic blocks that result from the application of program transformations such as loop unrolling. As such, the performance expectations derived using these assumptions should be viewed as an upper bound. For the same reason, we have folded the information about the data access pattern of array accesses in the scheduling by assuming that accesses that exhibit a very regular, strided data access pattern will have a low memory latency and those that are very irregular in nature will exhibit a high latency. This is because the first set is likely to hit the cache while the second is not.
Our scheduler, though simple, allows us to anticipate the completion time of the operations corresponding to a given basic block, along with various efficiency metrics, such as the number of clock cycles a given computation was stalled by while awaiting an available functional unit or awaiting a data dependency of the code to be satisfied. In our reporting, we use generic and architecture independent performance metrics such as the number of operations per clock cycle or number of floating point operations per clock cycle, rather then focusing on FLOPs or CPIs.
We now present preliminary experimental results of the performance expectation and sensitivity analysis for a synthetic code, the UMT2K, modeled after a real engineering application, a 3D, deterministic, multigroup, photon transport code for unstructured meshes. 6 We first describe the methodology followed in these experiments and then present and discussion our findings using our analysis approach.
We have built the basic analysis described above in section 2 using the Open64 compilation infrastructure.10 Our implementation takes an input source program file and focuses on the computationally intensive basic blocks. We used our analysis to extract DFG and generate performance expectation metrics for various combinations of architectural elements. We also applied manual unrolling to the significant loops in the kernel code as a way to compare the expected performance for the various code variants given the potential increase in instruction-level parallelism.
The computationally intensive section of the UMT2K code is located in what is designated the angular-loop located in the snswp3D subroutine. This loop contains a long basic block spanning about 300 lines of C code. This basic block, executed at each iteration of the loop, is the "core" of the computation, and has many high-latency floating point operations, such as divides (4) and multiplies (41) as depicted in Table 1.
| Total Operations |
FP Operations |
Integer Operations |
Load/Store Operations |
FP Multiplies |
FP Divides |
Integer Multiply |
| 272 | 93 | 95 | 84 | 41 | 4 | 22 |
In the next section we review some of the experimental results for this basic block in an unmodified form, as well as for manually unrolled versions to explore the performance impact of data dependences and number of arithmetic and load/store units on the projected performance. The unrolled versions will expose many opportunities to explore pipelined and non-pipelined execution of the various functional units and individual operations.
Table 2 below depicts the latencies of the individual operations used in our approach. These latencies are notional rather then being representative of a real system.
|
Load (cache miss) |
Load Address |
32-bit int. Add |
32-bit Int. Multiply |
32-bit FP Multiply |
32-bit FP Divide |
Array Address Calculation (Non-affine) |
Array Address Calculation (Affine) |
| 20 | 2 | 1 | 12 | 50 | 60 | 33 | 13 |
These experiments focus on three major aspects of performance analysis; varying the number of functional units, varying which operations are pipelined, and varying the latency of the load operations. The main goal of these experiments is to understand which aspect of the computation is limiting the performance of its execution, i.e., if the computation is memory or performance bound and how many units should be allocated to its execution in the most profitable fashion.
Figure 1 (left) depicts the impact of additional load and store units for all operations to execute in a pipelined fashion with the exception of the division, square root and reciprocal operations. For one Load/Store unit and one arithmetic unit the schedule of the unrolled version of the main basic block takes 955 clock cycles. As the graph indicates, there are clearly diminishing returns after two arithmetic units. The graph also shows that for this specific set of parameters, varying the number of load/store units does not alter performance significantly. This clearly indicates that computation is not data starved.
Figure 1 (right) depicts the same analysis but this time for the version of the code where the angular loop is unrolled by a factor of four. In this case the length of the schedule is longer as there are more arithmetic and load and store operations and the benefit of adding more functional units tails off for four units rather then for two units as in the previous unrolled case.
 |
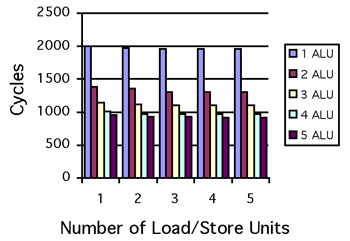 |
In either of the cases above, the computation is clearly bounded by the number of arithmetic units. For increasing numbers of load/store units the execution schedule varies little revealing that the computation is compute-bounded.
We have also observed the efficiency of various architecture variations by computing the number of executed operations per clock cycle for each scenario. Table 3 below presents the numerical results for the two unrolling scenarios and one Load/Store unit with one Arithmetic unit versus five of each units.
| Unrolling Factor | ||
| Number of Load/Store units and Arithmetic units | 1 | 4 |
| 1 | 1.30 | 2.73 |
| 5 | 1.015 | 1.2 |
The results in table 3 clearly show a substantial increase in the number of executed arithmetic operations for the case of a single arithmetic unit and a single load store unit versus the case of five units of each. For the configuration with five units, the efficiency metric drops approximately 25% for the original code and 50% for the code unrolled by a factor of four, thus revealing the later configuration not to be cost effective.
In order to observe the effect of the latency of the memory hierarchy we have analyzed the impact of increasing the latency of the load operations from 20 to 50 clock cycles. The results, depicted in figure 3 reveal that when the code is unrolled by a factor of four the performance is insensitive to the memory latency. This confirms that this code is not memory-bound. The results reveal that there is a 30% increase from one to two arithmetic units and a steady increase of 17% for two to three and three to four arithmetic units. This performance improvement is in stark contrast to the negligible gains obtained by increasing the number of load and store units.
It is also interesting to note that the schedule time for a system with arithmetic units that pipeline all opcodes11 with a single arithmetic unit is roughly equivalent to the standard code (without any unrolling) with five arithmetic units when both codes are unrolled four times. Also, when the code is not unrolled, increasing the number of arithmetic units has no effect when all opcodes are pipelined.

The architectural model developed in the current SLOPE implementation is rather simple (but not simplistic) in several respects. First, it assumes a zero overhead instruction scheduling. This is clearly not the case although pipelining execution techniques can emulate this aspect. Second, it does not take into account register pressure in the execution. Lastly, it does not yet take into account advanced execution techniques such as software pipelining and multi-threading. Ignoring these techniques and compiler implementation details clearly leads to quantitative results that differ, maybe substantially, from current high-end machines. Last but not least, this approach needs to be validated against a real architecture.
Nevertheless, this approach allows the development of quantitative architectural performance trends and hence allows architecture designers to make informed decisions about how to most efficiently allocate transistors. In the above case, a determination could be made between the complexity and power consumption (for example) of having an arithmetic that pipelines all operations (including divides) and simply replicating standard arithmetic. This information also allows developers to have an idea of what the performance trend increases will be on a proposed “future” machine for a given code.
We have described SLOPE, a system for performance prediction and architecture sensitivity analysis using source level program analysis and scheduling techniques. SLOPE provides a very fast qualitative analysis of the performance of a given kernel code. We have experimented with a real scientific code that engineers and scientists use in practice. The results yield important qualitative performance sensitivity information that can be used when allocating computing resources to the computation in a judicious fashion for maximum resource efficiency and/or help guide the application of compiler transformations such as loop unrolling.