Large-Scale Computational Scientific and Engineering Project Development and Production Workflows

November 2006 B
|
Large-Scale Computational Scientific and Engineering Project Development and Production Workflows
|
November 2006 B |
Computational science and engineering (CSE) is becoming an important tool for scientific research and development and for engineering design. It is being used to make new scientific discoveries and predictions, to design experiments and analyze the results, to predict operational conditions, and to develop, analyze and assess engineering designs. Each application generally requires a different type of application program, but there are important common elements. As computer power continues to grow exponentially, the potential for CSE to address many of the most crucial problems of society increases as well. The peak power of the next generation of computers will be in the range of 1015 floating point operations per second achieved with hundreds of thousands of processors. It is becoming possible to run applications that include accurate treatments of all of the scientific effects that are known to be important for a given application. However, as the complexity of computers and application programs increases, the CSE community is finding it difficult to develop the highly complex applications that can exploit the advances in computing power. We are facing the possibility that we will have the computers but we may not be able to quickly and more easily develop large-scale applications that can exploit the power of those computers.
In support of the Defense Advanced Research Projects Agency’s High Productivity Computing Systems Program (DARPA HPCS) to reduce these software difficulties, we have conducted case studies of many large scale CSE projects and identified the key steps involved in developing and using CSE tools.1 This information is helping the computer architects for the DARPA HPCS computers understand the processes involved in developing and using large-scale CSE projects, and identify the associated bottlenecks and challenges. This has facilitated their efforts to develop and implement productivity improvements in computer architectures and in the software support infrastructure. This information can also used as a blueprint for new projects.
While CSE workflows share many features with traditional Information Technology (IT) software project workflows, there are important differences. IT projects generally begin with the specification of a detailed set of requirements.2 The requirements are used to plan the project. In contrast, it is generally impossible to define a precise set of requirements and develop a detailed software design and workplan for the development and application of large-scale CSE projects. This is not because CSE projects have no requirements. Indeed, the requirements for CSE projects, the laws of nature, are very definite and are not flexible. The challenge computational scientists and engineers face is to develop and apply new computational tools that are instantiations of these laws. CSE applications generally address new phenomena. Because they address new issues, they often exhibit new and unexpected behavior. Successful projects identify the properties of nature that are most important for the phenomena being studied and develop and implement computational methods that accurately simulate those properties. The initial set of candidate algorithms and effects usually turns out to be inadequate and new ones have to be developed and implemented. Successful code development is thus a “requirements discovery” process. For these reasons, the development and use of CSE projects is a complex and highly iterative process. While it is definitely not the waterfall model, it does share some of the features of more modern software engineering workflows such as the “spiral” development model.2

A typical CSE project has the following steps (Figure 1):
These large tasks strongly overlap each other. There is usually a lot of iteration among the steps and within each step. Quite commonly, it turns out that some of the candidate algorithms are not sufficiently accurate, robust, stable or efficient, and new candidate algorithms must be identified, implemented and tested. Similarly, comparison with experimental data (validation) usually shows that the initial set of physical phenomena does not include all of the effects necessary to accurately simulate the phenomenon of interest. The project then needs to identify the effects that were not included in the model but are necessary for accurate simulations, incorporate them in the application, and assess whether the new candidate effects are adequate for simulating the target phenomenon. Often this series of steps will be iterated many times.
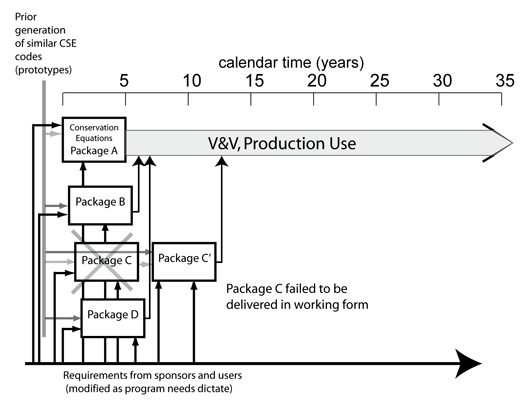
Another key aspect of CSE project workflows is the project life cycle (Figure 2). Large-scale CSE projects can have a life cycle of 30 to 40 years or more, far longer than most Information Technology projects. The NASTRAN engineering analysis code was originally developed in the 1960s and is still heavily used today.3 In contrast, the time between generations of computers is much shorter, often no more than two to four years. A typical major CSE project has an initial design and development phase (including verification and initial validation), that often lasts five or more years (Fig. 2). That is followed by a second phase in which the initial release is further validated, improved and then further developed based on experience by the users running real problems. A production phase follows during which the code is used to solve real problems. If the project is successful, the production phase is often the most active development phase. Once the code enters heavy use, many deficiencies and defects become apparent and need to be fixed, and the users generate new requirements for expanded capability. The new requirements may be due to new demands by the sponsor or user community, to the desire to incorporate new algorithmic improvements, or to the need to port to different computer platforms. Even if no major changes are made during the production phase, substantial code maintenance is usually required for porting the code to different platforms, responding to changes in the computational infrastructure, and fixing problems due to non-optimal initial design choices. The rule of thumb among many major CSE projects is that about one FTE of software maintenance support is needed for each four FTEs of users.

Historically, many, if not most, CSE codes have included only a limited number of effects and were developed by teams of one to five or so professionals. The few CSE codes that were multi-effect generally developed one module for a new effect and added it to the existing code (Figure 3). Once the new module had been successfully integrated into the major application, the developers then started development of the next module. This approach had many advantages. It allowed the developers and users to extensively use and test the basic capability of the code while there was time to make changes in the choices of solution algorithms, data structures, mesh and grid topologies and structures, user interfaces, etc. The users were able to verify and validate the basic capability of the code. Then they were able to test each new capability as it was added. The developers got rapid feedback on every new feature and capability. The developers of new modules had a good understanding of the existing code because many of them had written it. It was therefore possible to make optimum trade-offs in the development of good interfaces between the existing code and new modules. On the other hand, serial development takes a long time. If a code has four major modules that take five years to develop, the full code won’t be ready for 20 years. Unfortunately, by then the whole code may be obsolete. Certainly the code will have been ported to new platforms many times.

To overcome these limitations, multi-effect codes are now generally developed in parallel (Figure 4). If a code is designed to include four effects, and the modules for each effect take five years to develop, then the development team will consist of 20 members plus those needed to support the code infrastructure. If all goes well, the complete code with treatments of all four effects will be ready five or six years after the start of the project instead of 20 years.
Because the development teams are much larger, and the individual team members often don’t have working experience with the modules and codes being developed by the other module sub-teams, the software engineering challenges are much greater. Parallel development also increases the relative risks. If the development of a module fails, a new effort has to be started. If one out of four module initial development efforts fail, then the impact on total development time is to double it compared to only a twenty-five percent increase with serial development.
The code development and production phases of software projects involve many different types of activities. In general each requires different tools and methods. We were able to define four broad categories of tools (and methods) that are typically required in different phases of the scientific software lifecycle. The potential suppliers for these tools and methods include platform vendors, commercial third party vendors, academic institutions, and open source developers.
This includes the computer operating system (e.g., Linux, AIX, True64, etc.), text editors, interactive development environments (e.g., Eclipse), languages and compilers (Fortran, C, C++, JAVA, etc.) including language enhancements parallel computers (Co-array Fortran, UPC, HPF, OpenMP, Pthreads, etc.), parallel communication libraries (e.g., MPI), symbolic mathematics and engineering packages with a high level of abstraction (Mathematica, Maple, Matlab, etc.), interpretative and compiled scripting languages (PERL, Python, etc.), debuggers (e.g., Totalview), syntax checkers, static and dynamic analysis tools, parallel file systems, linkers and build tools (e.g., MAKE), job schedulers (e.g., LFS), job monitoring tools, performance analysis tools (e.g. Vampir, Tau, Open Speedshop, etc.). This software can either be supplied by the platform vendor or by third parties. For instance, AIX is supplied by IBM. Etnus markets the debugger Totalview.
This includes running the code and collecting and analyzing the results. Many of the tools for the code development environment are required (operating system, job scheduler, etc.). In addition there are specific tasks that involve problem setup (e.g., mesh generation, decomposing the problem domain for parallel runs, etc.), checkpoint restart capability, recovery from faults and component failures (fault tolerance), monitoring the progress of a run, storing the results of the run, and analyzing the results (visualization, data analysis, etc.). Some of this software is supplied by the platform vendor and some by third parties. CEI, for instance, markets Ensight, a massively parallel 3D Visualization tool. Research Systems markets IDL, a data analysis tool. A key task is verification and validation which requires tools for comparing code results with test problem results, experimental data and results from other codes.
These tasks involve organizing, managing and monitoring the code development process. Tools that would help with this task include configuration management tools (e.g., CVS, Perforce, Razor, etc.), code design and code architecture (e.g., UML) although there are few examples of code design tools being used for HPC applications, documentation tools (word processors, web page design and development tools, etc.), software quality assurance tools, project design tools, and project management tools (Microsoft Project, Primavera, etc.). Most of these are supplied by commercial third party vendors. Development of code development collaboration tools for multi-institutional code development teams will also be important in the future (probably a third party task).
These tasks involve development and support of computational algorithms and libraries that are incorporated into working code. These include computational mathematics libraries (e.g., PETSc, NAG, HYPRE, and Trilinos.), physical data libraries, low-level memory management libraries (e.g., MPI), etc. These are supplied by computer platform vendors, commercial vendors, academic and national laboratory institutions, and the open source community.
For tasks that call for selection of an approach or method, the expectation is that the vendor will provide options and some guidance (documentation and consultation) on which approach or method is most appropriate for a set of specific requirements. In general a formal tool for making the selection is not required.
In the discussion that follows, the categories of software tools defined above will be listed under each major workflow stage.
The development and production workflow for a typical CSE project is highly iterative and exploratory. Each stage of software development involves many steps that are closely linked. If the steps can be completed successfully, the work proceeds to the next step (Figure 5). For most realistic cases, multiple issues arise at each step and resolution of the issues often requires iteration with prior steps. The detailed architecture of the code evolves as the code is developed and issues are discovered and resolved.
The degree to which each step becomes a formal process depends on the scale of the project. A small project involving only one or two people need not devote a lot of time to each process. Nonetheless, even small projects will go through almost all of the steps defined below. It is thus worthwhile for almost all projects to go through the checklist to ensure that they don’t miss a step, which would be simple to address early in the project, but difficult much later in the project.
Throughout this paper we define stakeholders as everyone who has a stake in the project including the sponsors, the users and customers, the project team, the project and institutional management, the groups who provide the computer and software infrastructure, and sub-contractors. Sub-contractors include everyone who develops and supplies crucial modules and software components for the project, but who are not part of the project team and not under the direct control of the project management.
The time scale for this phase is generally three months to a year. The first step involves assessing the state of the science and engineering, its potential for solving the problem of interest, and the development of a roadmap and high-level plan for the project. A key element is the assessment of prior and existing methods for solving this problem with an analysis of their strengths and weaknesses. Prior and existing computational tools provide highly useful prototypes for the proposed project; they embody the methods and algorithms that have been successful in the past and demonstrate the strengths and weaknesses of those methods. These help potential sponsors, users, stakeholders and domain experts achieve a common view of the problem. For the science community, this phase would result in a proposal for submission to a funding agency (e.g., NSF, DOE SC, etc.). This phase also would provide a document that will be essential for developing a customer base, getting additional support, and communicating the project goals, purpose, and plan to the stakeholders, including prospective project team members.

This stage involves knowledge of all of the development tasks cited above, but emphasizes detailed knowledge of software engineering and software project management, and computational algorithms and libraries. However, a note of caution is appropriate. Extensive use of software tools for project management is premature and can be a serious distraction. Similarly, extensive assessment of algorithms and methods is also premature. A high-level plan and general code architecture is needed before detailed work begins.
| General Software infrastructure tool requirements: particularly configuration management (3), project management(3), documentation (3), computational mathematics (4), … |
The time scale for this phase is three months to a year. This is the major planning phase. While some small scale projects may not need much planning, many code development projects ultimately reach cost levels that exceed $100M over the life of the project. In every other type of technical work, sponsoring institutions require detailed plans for how the work will be accomplished, goals met, and progress monitored. They have found that plans and monitoring of progress are essential for minimizing project risks and maximizing project success. CSE is no exception. Developing plans for CSE projects is challenging. The plans must incorporate sufficiently detailed information on the project tasks, schedule and estimated costs for the project to be monitored and judged by the project sponsors and stakeholders. At the same time, the plans must preserve sufficient flexibility and agility that the project can successfully “discover, research, develop and invent” the domain science and solution algorithms need by the project. This is also the time to do a lot of prototyping and testing of candidate modules and algorithms and to explore the issues of integrating modules for different effects, particularly modules for effects that have time and distance scales that differ by many orders of magnitude.
| General Software infrastructure tool requirements and best practices include: ongoing [documentation of scientific model, equations, design, code, components(3)], configuration management (3), project management(3), component design(3), Compilers(1), Scripts (1), code driver(1), Linker/loaders(1), Syntax and static analyzers(1), Debuggers(1), V&V tools(2), .. |
This phase includes the development of the main code (highlighted in Figure 5), runtime controller, individual modules (highlighted in Figure 5), integration of the individual module’s physical databases, problem setup capability, and data analysis and assessment capability. It generally takes five to 10 years for the development of the initial capability of such a project. The steps are summarized below. As the project evolves, the software project management plan will need to be kept current. Risk management is a key issue. If an approach does not work, then alternatives need to be developed and deployed. All of the development should be under strong configuration management. The development of each module should follow a clearly documented plan that describes the domain science, equations, and computational approach. The final module should be thoroughly documented. This is essential for future maintenance and improvements.
| General Software infrastructure tool requirements and best practices: data analysis and visualization tools(2), tools for quantitative comparison of code results with test problem results, other code results and experimental data(2). |
Verification provides assurance that the models and equations in the code and the solution algorithms are mathematically correct, i.e., that the computed answers are the correct solutions of the model equations. Validation provides assurance that the models in the code are consistent with the laws of nature and are adequate to simulate the properties of interest.8 V&V is an ongoing process that lasts the life of the code. However, it is particularly intense during the development of the code and early adoption by the user community. Verification is accomplished with tests that show that the code can reproduce known answers and demonstrate the preservation of known symmetries and other predictable behavior. Validation is accomplished by comparing the code results for an experiment or observation with real data taken from the experiment or observation. A code must first be verified then validated. Without prior verification, agreement between experimental validation data and the code results can only be viewed as fortuitous. Without a successful, documented verification and validation program, there is no reason for any of the project stakeholders to be confident that the code results are accurate.9
| General Software infrastructure tool requirements and best practices: Data analysis tools, visualization tools, (2), documentation(3), job scheduling(1), |
Running a large-scale simulation on a large supercomputer represents a significant investment on the part of the sponsor. Large codes can cost $5M to $10M per year to develop, maintain and run, and more if the costs of validation experiments are included. Large computers are expensive resources. Computer time now costs approximately $1/cpu-hour (2006). A large project will need 5M cpu-hours or more. The total cost is thus in the range of $10M to $20M per year or more and hundreds of millions over the life of the project. It is analogous to getting run time on a large scale experiment (e.g., getting beam time at an accelerator, conducting experiments, collecting data, analyzing data). Sponsoring institutions and large scale experimental facilities and teams have learned that research and design activities of this scale require organization and planning to be successful.
Typical production runs from a large-scale computational project can produce TeraBytes or more of data. Analysis of the computational results is not only essential but can also be challenging.
The whole purpose of the computational system of computers, codes and results analysis is to provide information for the basis of decisions for scientific discovery, engineering design, prediction of operational conditions, etc. Often this is an iterative process. Analysis of the initial results will suggest several conclusions. Further production runs, and possibly further code development, will be needed to confirm those conclusions and suggest modifications. Finally, the decisions and the basis of the decisions need to be documented.
On the basis of many case studies of successful and unsuccessful Computational Science and Engineering Projects we have identified the steps that such projects follow from initial concept to final conclusions and decisions based on the results of the project. While none of the projects explicitly followed all these steps in an orderly fashion, the successful ones followed these steps either explicitly or implicitly. Key points emerged from the case studies.