The development of low pressure areas and the timelines of these turning into hurricanes can vary from a few hours to a few days. A worst case scenario could have an advance notice of less than 12 hours, making it difficult to quickly obtain resources for an extensive set of investigatory model runs and also making it imperative to be able to rapidly deploy models and analysis data.
One obvious solution would be to dedicate a set of supercomputers for hurricane prediction. This would however require a significant investment to deploy and maintain the resources in a state of readiness; multiple sites would be needed to provide reliability, and the extent of the modeling would be restricted by the size of the machines.
A different solution is to use resources that are deployed and maintained to support other scientific activities, for example the NSF TeraGrid (which will soon be capable of providing over 1 PetaFlops of power), the SURAgrid (developing a community of resources providers to support research in the southeast US), or the Louisiana Optical Network Initiative (LONI) (with around 100 TeraFlops for state researchers in Louisiana). Section 3 describes some of the issues involved when resources are provided to both a broad community of scientists and to support urgent computing.
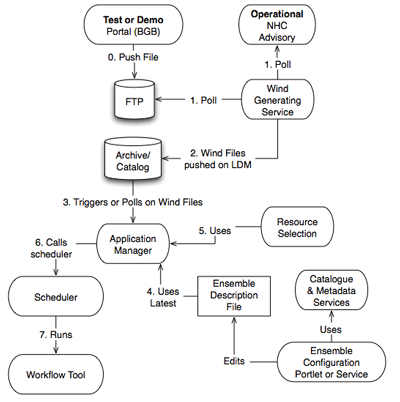
The impact of a hurricane is estimated from predicted storm surge height, wave height, inundation and other data. Coastal scientists provide estimations using a probabilistic ensemble of deterministic models to compute the probability distribution of plausible storm impacts. This distribution is then used to obtain a metric of relevance for the local emergency responders (e.g., the maximum water elevation or MEOW) and get to them in time to make an informed decision2. Thus, for every cycle there will be an ensemble of runs corresponding to the runs of all the models for each of the set of perturbed tracks. The SCOOP Cyberinfrastructure includes a workflow component to run each of the models for each of the tracks. The NHC advisory triggers the workflow that runs models to generate various products that are either input to other stages of the workflow or are final results that end up as visualized products. Figure 3 shows the SCOOP workflow from start to end and the interactions between various components.
During a storm event, the SCOOP workflow is initiated by an NHC advisory that becomes available on an FTP site that is continuously polled for new data. When new track data is detected, the wind field data is generated that is then pushed to the SCOOP archives using the Logical Data Manager (LDM) to handle data movement. Once the files are received at the archive, the archive identifies the file type and runs a trigger that triggers the execution of the wave and surge models. The trigger invokes the SCOOP Application Manager (SAM) that looks up the Ensemble Description File (EDF) to identify the urgency and priority associated with the run. The urgency and priority of a run and how the SCOOP system uses this information are elaborated in the next section.