

These experiments focus on three major aspects of performance analysis; varying the number of functional units, varying which operations are pipelined, and varying the latency of the load operations. The main goal of these experiments is to understand which aspect of the computation is limiting the performance of its execution, i.e., if the computation is memory or performance bound and how many units should be allocated to its execution in the most profitable fashion.
Figure 1 (left) depicts the impact of additional load and store units for all operations to execute in a pipelined fashion with the exception of the division, square root and reciprocal operations. For one Load/Store unit and one arithmetic unit the schedule of the unrolled version of the main basic block takes 955 clock cycles. As the graph indicates, there are clearly diminishing returns after two arithmetic units. The graph also shows that for this specific set of parameters, varying the number of load/store units does not alter performance significantly. This clearly indicates that computation is not data starved.
Figure 1 (right) depicts the same analysis but this time for the version of the code where the angular loop is unrolled by a factor of four. In this case the length of the schedule is longer as there are more arithmetic and load and store operations and the benefit of adding more functional units tails off for four units rather then for two units as in the previous unrolled case.
 |
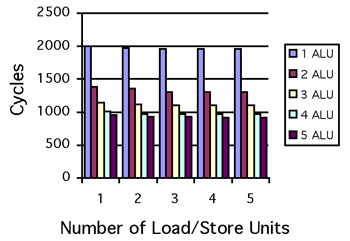 |
In either of the cases above, the computation is clearly bounded by the number of arithmetic units. For increasing numbers of load/store units the execution schedule varies little revealing that the computation is compute-bounded.
We have also observed the efficiency of various architecture variations by computing the number of executed operations per clock cycle for each scenario. Table 3 below presents the numerical results for the two unrolling scenarios and one Load/Store unit with one Arithmetic unit versus five of each units.
| Unrolling Factor | ||
| Number of Load/Store units and Arithmetic units | 1 | 4 |
| 1 | 1.30 | 2.73 |
| 5 | 1.015 | 1.2 |
The results in table 3 clearly show a substantial increase in the number of executed arithmetic operations for the case of a single arithmetic unit and a single load store unit versus the case of five units of each. For the configuration with five units, the efficiency metric drops approximately 25% for the original code and 50% for the code unrolled by a factor of four, thus revealing the later configuration not to be cost effective.
In order to observe the effect of the latency of the memory hierarchy we have analyzed the impact of increasing the latency of the load operations from 20 to 50 clock cycles. The results, depicted in figure 3 reveal that when the code is unrolled by a factor of four the performance is insensitive to the memory latency. This confirms that this code is not memory-bound. The results reveal that there is a 30% increase from one to two arithmetic units and a steady increase of 17% for two to three and three to four arithmetic units. This performance improvement is in stark contrast to the negligible gains obtained by increasing the number of load and store units.
It is also interesting to note that the schedule time for a system with arithmetic units that pipeline all opcodes11 with a single arithmetic unit is roughly equivalent to the standard code (without any unrolling) with five arithmetic units when both codes are unrolled four times. Also, when the code is not unrolled, increasing the number of arithmetic units has no effect when all opcodes are pipelined.



