

Performance of a system can only be measured relative to a workload description. This is usually achieved by selecting a set of benchmarks representative of a particular workload of interest. Beyond this, there cannot be a meaningful, absolute performance measure valid for all possible workloads. The complexity of programming codes on a given system also depends on the set of codes in question. Therefore, (PC) can be defined only relative to a workload and not in absolute terms! The situation is even more complex when we consider coding the same algorithm in different languages and with different programming styles.
Programming for performance is easier if we understand the influence of system and code features on performance behavior and if unexplained performance variations are small. The level of performance transparency does, however, not indicate any level of performance itself. It only specifies, that we understand performance. This understanding of performance behavior of a code on a system implies that we can develop an accurate performance model for it. Therefore, my approach is to use the accuracy of a suitable set of performance models to quantify the (PC).
In the ideal case the selected performance model should incorporate the effects of all code features easily controllable in a given program-ming language and not include any architectural features inaccessible to the programmer. In essence, the performance models for calculating a PC value should reflect the (possible) behavior of a programmer, in which case PC reflects the performance transparency and complexity of performance control the programmer will experience.
Goodness of fit measures for modeling measurements are based on the Sum of Squared Errors (SSE). For a system Si the performance Pij of a set of n codes Cj is measured. Different measurements j might also be obtained with the same code executed with different problem parameters such as problem sizes and resource parameters such as concurrency levels. A performance model Mkl is used to predict performance Mikl for the same set of experiments.
| Operation | Dimension* | Initial data: Pj, Mj | [ops/sec] |
| Transform Pj, Mj to ideal flat metric | [ops/cycle] |
| Log-transformation: P'j=log(Pi), M'j=log(Mi) | [log(ops/cycle)] |
| Basic Calculations | |
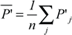 |
[log(ops/cycle)] |
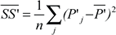 |
[(log(ops/cycle))2] |
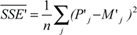 |
[(log(ops/cycle))2] |
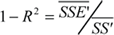 |
[] |
| Back-Transformations | |
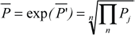 |
[ops/cycle] |
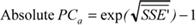 |
[ops/cycle] |
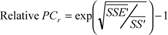 |
[] |
| Back-transformation of P¯;PCa to original scale and metrics | [ops/sec] |
*Inverse dimensions could be chosen as well.
To arrive at a PC measure with the same metric as performance, I have to use standard deviation (SD), which is the square-root of average SSE, and I cannot use the more widely used total sum. The average SSEkl for each system i and model k across all codes j is then given by 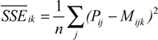 . While these SSE values are still absolute numbers (they carry dimension), they are easily transformed into relative numbers by dividing them by the similarly defined Sum of Squares (SS) of the measured data P:
. While these SSE values are still absolute numbers (they carry dimension), they are easily transformed into relative numbers by dividing them by the similarly defined Sum of Squares (SS) of the measured data P: 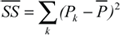 and
and 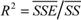 .
.
To further reduce the range of performance values, a log-transformation should be applied to the original data. This effectively bases the calculated SSE values on relative errors instead of absolute errors. To obtain numbers in regular dimensions, I transform the final values of SSE back with an exponential function. The resulting numbers turn out to be known as geometric standard deviation, representing multiplicative instead of additive, relative values, which are larger or equal to one. For convenience, I transform these values into the usual range of larger than zero by subtracting one. The full sequence of the calculation step is summarized in Table 1.
The outlined methodology can be applied equally to absolute performance metrics or to relative efficiency metrics. PCa represents an absolute metric while PCr would be the equivalent, relative efficiency metric. PCr is in the range [0,1] and reflects the percentage of the original variation not resolved in the performance model. Hence, while using PCr care has to be taken when comparing different systems, as a system with larger relative complexity PCr might have lower absolute complexity PCa. This is the same problem as comparing the performance of different systems using efficiency metrics such as ops/cycle or speedup.


