

The precise algorithmic details of this particular SAR processing chain are given in its written specification. In Stage 1, the data is transformed in a series of steps from a n×mc single precision complex valued array to a m × nx single precision real valued array. At each step, either the rows or columns can be processed in parallel. This is sometimes referred to as “fine grain” parallelism. There is also pipeline or task parallelism that exploits the fact that each step in the pipeline can be performed in parallel, with each step processing a frame of data. Finally, there is also coarse grain parallelism, which exploits the fact that entirely separate SAR images can be processed independently. This is equivalent to setting up multiple pipelines.
At each step, the processing is along either the rows or the columns, which defines how much parallelism can be exploited. In addition, when the direction of parallelism switches from rows to columns or columns to rows, a transpose (or “cornerturn”) of the matrix must be performed. On a typical parallel computer a cornerturn requires every processor to talk to every other processor. These cornerturns often are natural boundaries along which to create different stages in a parallel pipeline. Thus, in Stage 1 there are four steps, which require three cornerturns. This is typical of most SAR systems.
In stage 2, pairs of images are compared to find the locations of new “targets.” In the case of the SAR benchmarks, these targets are just nfont × nfont images of rotated capital letters that have been randomly inserted into the SAR image. The Region Of Interest (ROI) around each target is then correlated with each possible letter and rotation to identify the precise letter, its rotation and location in the SAR image. The parallelism in this stage can be along the rows or columns or both, as long as enough overlapping edge data is kept on each processor to correctly do the correlations over the part of the SAR image for which it is responsible. These edge pixels are sometimes referred to as overlap, boundary, halo or guard cells. The input bandwidth is a key parameter in describing the overall performance requirements of the system. The input bandwidth (in samples/second) for each processing stage is given by
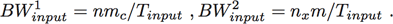 (1)
(1)A simple approach for estimating the overall required processing rate is to multiply the input bandwidth by the number of operations per sample required. Looking at Table 1, if we assume n ≈ nx ≈ 8000 and mc ≈ nx ≈ 4000, the operations (or work) done on each sample can be approximated by
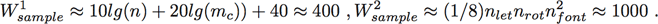 (2)
(2)Thus, the performance goal is approximately
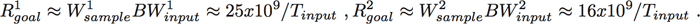 (3)
(3)Tinput varies from system to system, but can easily be much less than a second, which yields large compute performance goals. Satisfying these performance goals often requires a parallel computing system.
The file IO requirements in “System Mode” or “IO Only Mode” are just as challenging. In this case the goal is read and write the files as quickly as possible. During Stage 1 a file system must read in large input files and write out large image files. Simultaneously, during Stage 2, the image files are selected at random and read in and then many very small “thumbnail” images around the targets are read out. This diversity of file sizes and the need for simultaneous read and write is very stressing often requires a parallel file system.


