The HPC Challenge suite consists of several activity-based benchmarks designed to test various aspects of a computing platform (see “Design and Implementation of the HPC Challenge Benchmark Suite” in this issue). The four benchmarks used in this study were FFT (v0.6a), High Performance Linpack (HPL, v0.6a), RandomAccess (v0.5b), and Stream (v0.6a). These codes were run on the Lincoln Laboratory Grid (LLGrid), a cluster of dual-processor nodes connected by Gigabit Ethernet.9 The parallel codes were each run using 64 of these dual-processor nodes, for a total of 128 CPUs. The speedup for each parallel code was determined by dividing the runtime for a baseline serial C/Fortran code by the runtime for the parallel code (the serial Matlab code was treated the same as the parallel codes for purposes of comparison).
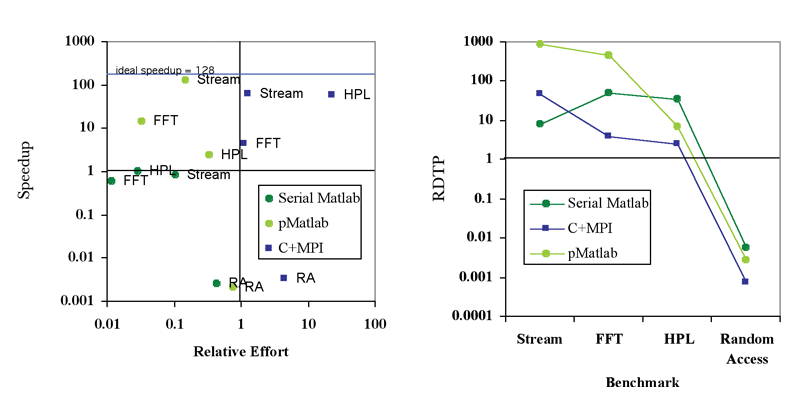
Figure 3 presents the results of RDTP analysis for the HPC Challenge benchmarks. With the exception of Random Access (the implementation of which does not scale well on distributed-memory computing clusters), the MPI implementations all fall into the upper-right quadrant of the graph, indicating that they deliver some level of parallel speedup, while requiring greater effort than the serial code. As expected, the serial Matlab implementations do not deliver any speedup, but all require less effort than the serial code. The pMatlab implementations (except Random Access) fall into the upper-left quadrant of the graph, delivering parallel speedup while at the same time requiring less effort.
The combination of parallel speedup and reduced effort means that the pMatlab implementations generally have higher RDTP values. On average the serial Matlab implementations come in second, due to their low relative effort. The MPI implementations, while delivering better speedup, also require more relative effort, leading to lower RDTP values.