The NAS Parallel Benchmark (NPB)7 suite consists of five kernel benchmarks and three pseudo-applications from the field of computational fluid dynamics. The NPB presents an excellent resource for this study, in that it provides multiple language implementations of each benchmark. The exact codes used were the C/Fortran (serial, OpenMP) and Java implementations from NPB-3.0, and the C/Fortran (MPI) implementations from NPB-2.4. In addition, a parallel ZPL8 implementation and two serial Matlab implementations were also included in the study.
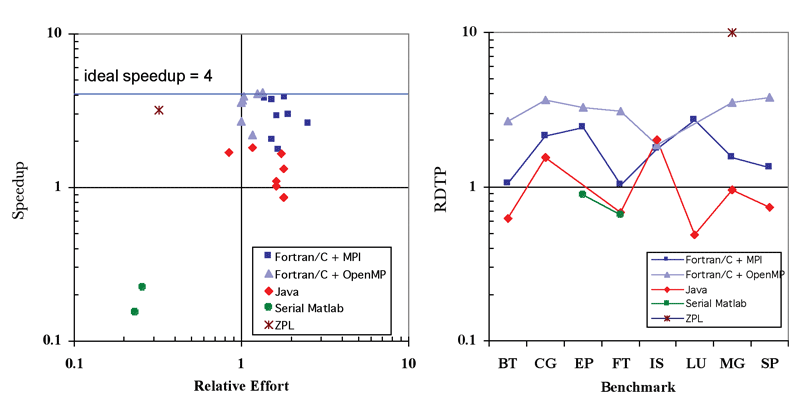
In Figure 2, the chart on the left displays speedup vs. relative effort for the NPB. Each data point corresponds to one of the eight benchmarks included in the NPB suite, and the results are grouped by implementation. The chart on the right plots the RDTP values for the various implementations of each of the eight NPB benchmark codes. For purposes of comparison, each parallel code was run using four processors. The speedup and relative effort for each benchmark implementation are calculated with respect to a reference serial code implemented in Fortran or C.
As shown, the OpenMP implementations tend to yield parallel speedup comparable to MPI, while requiring less relative effort. This is reflected in the higher RDTP values for OpenMP. The lone ZPL implementation falls in the upper-left quadrant of the graph, delivering relatively high speedup while requiring less effort, as compared to the serial Fortran implementation. Accordingly, this ZPL implementation has a high RDTP value. Although a single data point does not constitute a trend, this result was included as an example of an implementation that falls in this region of the graph. The Matlab results provide an example of an implementation that falls in the lower-left quadrant of the graph, meaning that its runtime is slower than serial Fortran, but it requires less relative effort. By virtue of its extremely low relative effort, the serial Matlab manages to have a RDTP value comparable to parallel Java.